make_pipeline#
- sklearn.pipeline.make_pipeline(*steps, memory=None, transform_input=('X_val',), verbose=False)[source]#
Construct a
Pipelinefrom the given estimators.This is a shorthand for the
Pipelineconstructor; it does not require, and does not permit, naming the estimators. Instead, their names will be set to the lowercase of their types automatically.- Parameters:
- *stepslist of Estimator objects
List of the scikit-learn estimators that are chained together.
- memorystr or object with the joblib.Memory interface, default=None
Used to cache the fitted transformers of the pipeline. The last step will never be cached, even if it is a transformer. By default, no caching is performed. If a string is given, it is the path to the caching directory. Enabling caching triggers a clone of the transformers before fitting. Therefore, the transformer instance given to the pipeline cannot be inspected directly. Use the attribute
named_stepsorstepsto inspect estimators within the pipeline. Caching the transformers is advantageous when fitting is time consuming.- transform_inputtuple or list of str, default=(“X_val”,)
This enables transforming some input arguments to
fit(other thanX) to be transformed by the steps of the pipeline up to the step which requires them. Requirement is defined via metadata routing. This can be used to pass a validation set through the pipeline for instance.By default, the validation set
X_valis always transformed.You can only use this if metadata routing is enabled, which you can enable using
sklearn.set_config(enable_metadata_routing=True).Added in version 1.6.
Changed in version 1.10: The default changed from
Noneto("X_val",).- verbosebool, default=False
If True, the time elapsed while fitting each step will be printed as it is completed.
- Returns:
- pPipeline
Returns a scikit-learn
Pipelineobject.
See also
PipelineClass for creating a pipeline of transforms with a final estimator.
Examples
>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.pipeline import make_pipeline >>> make_pipeline(StandardScaler(), GaussianNB(priors=None)) Pipeline(steps=[('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())])
Gallery examples#
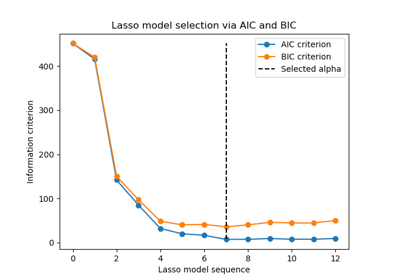
Analysis of the convergence of penalized logistic regression models

A demo of K-Means clustering on the handwritten digits data
Principal Component Regression vs Partial Least Squares Regression
Visualizing the probabilistic predictions of a VotingClassifier

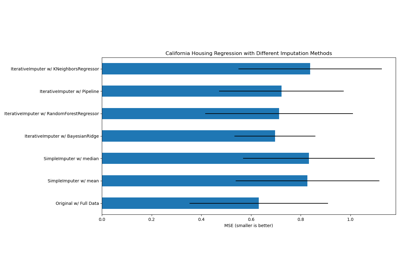
Imputing missing values with variants of IterativeImputer
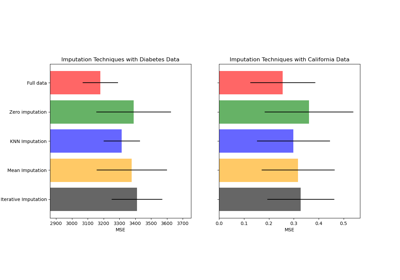
Imputing missing values before building an estimator
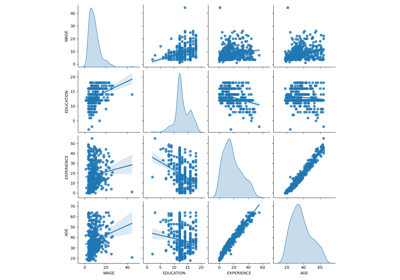
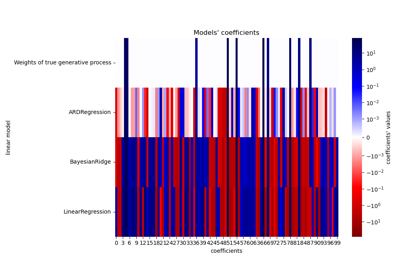
Common pitfalls in the interpretation of coefficients of linear models
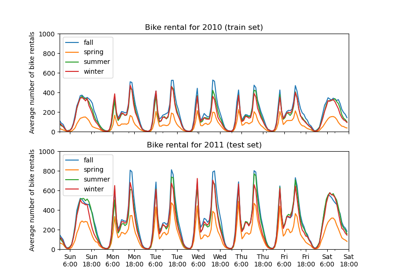
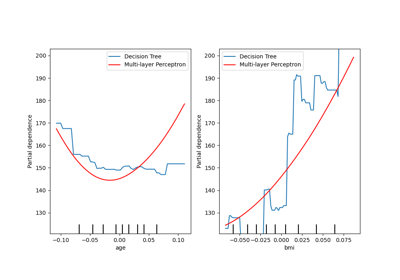
Partial Dependence and Individual Conditional Expectation Plots
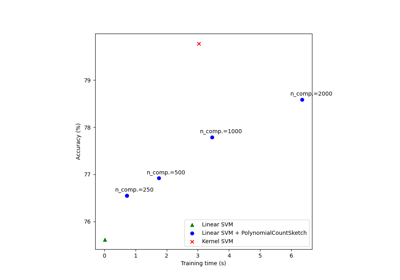
Scalable learning with polynomial kernel approximation
One-Class SVM versus One-Class SVM using Stochastic Gradient Descent

Manifold learning on handwritten digits: Locally Linear Embedding, Isomap…
Comparing anomaly detection algorithms for outlier detection on toy datasets


Post-tuning the decision threshold for cost-sensitive learning
Post-hoc tuning the cut-off point of decision function

Dimensionality Reduction with Neighborhood Components Analysis