TargetEncoder#
- class sklearn.preprocessing.TargetEncoder(categories='auto', target_type='auto', smooth='auto', cv=5, shuffle='deprecated', random_state='deprecated')[source]#
Target Encoder for regression and classification targets.
Each category is encoded based on a shrunk estimate of the average target values for observations belonging to the category. The encoding scheme mixes the global target mean with the target mean conditioned on the value of the category (see [MIC]).
When the target type is “multiclass”, encodings are based on the conditional probability estimate for each class. The target is first binarized using the “one-vs-all” scheme via
LabelBinarizer, then the average target value for each class and each category is used for encoding, resulting inn_features*n_classesencoded output features.TargetEncoderconsiders missing values, such asnp.nanorNone, as another category and encodes them like any other category. Categories that are not seen duringfitare encoded with the target mean, i.e.target_mean_.For a demo on the importance of the
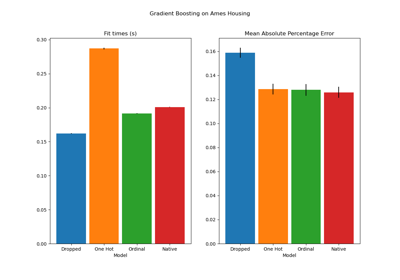
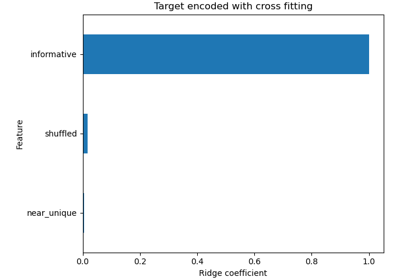
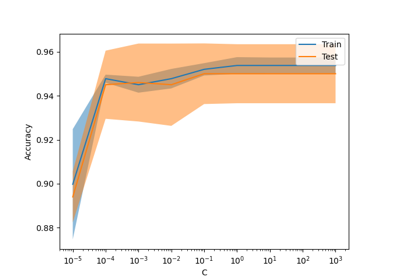
TargetEncoderinternal cross fitting, see Target Encoder’s Internal Cross fitting. For a comparison of different encoders, refer to Comparing Target Encoder with Other Encoders. Read more in the User Guide.Note
fit(X, y).transform(X)does not equalfit_transform(X, y)because a cross fitting scheme is used infit_transformfor encoding. See the User Guide for details.Added in version 1.3.
- Parameters:
- categories“auto” or list of shape (n_features,) of array-like, default=”auto”
Categories (unique values) per feature:
"auto": Determine categories automatically from the training data.list :
categories[i]holds the categories expected in the i-th column. The passed categories should not mix strings and numeric values within a single feature, and should be sorted in case of numeric values.
The used categories are stored in the
categories_fitted attribute.- target_type{“auto”, “continuous”, “binary”, “multiclass”}, default=”auto”
Type of target.
"auto": Type of target is inferred withtype_of_target."continuous": Continuous target"binary": Binary target"multiclass": Multiclass target
Note
The type of target inferred with
"auto"may not be the desired target type used for modeling. For example, if the target consisted of integers between 0 and 100, thentype_of_targetwill infer the target as"multiclass". In this case, settingtarget_type="continuous"will specify the target as a regression problem. Thetarget_type_attribute gives the target type used by the encoder.Changed in version 1.4: Added the option ‘multiclass’.
- smooth“auto” or float, default=”auto”
The amount of mixing of the target mean conditioned on the value of the category with the global target mean. A larger
smoothvalue will put more weight on the global target mean. If"auto", thensmoothis set to an empirical Bayes estimate.- cvint, cross-validation generator or an iterable, default=None
Determines the splitting strategy used in the internal cross fitting during
fit_transform. Splitters where each sample index doesn’t appear in the validation fold exactly once, raise aValueError. Possible inputs for cv are:None, to use a 5-fold cross-validation chosen internally based ontarget_type,
- integer, to specify the number of folds for the cross-validation chosen
internally based on
target_type,
CV splitter that does not repeat samples across validation folds,
an iterable yielding (train, test) splits as arrays of indices.
For integer/None inputs, if
target_typeis"continuous",KFoldis used, otherwiseStratifiedKFoldis used.Refer User Guide for more information on cross-validation strategies.
Changed in version 1.9: Cross-validation generators and iterables can also be passed as
cv.- shufflebool, default=True
Whether to shuffle the data in
fit_transformbefore splitting into folds. Note that the samples within each split will not be shuffled. Only applies ifcvis an int orNone. Ifcvis a cross-validation generator or an iterable,shuffleis ignored.Deprecated since version 1.9:
shuffleis deprecated and will be removed in 1.11. Pass a cross-validation generator ascvargument to specify the shuffling instead.- random_stateint, RandomState instance or None, default=None
When
shuffleis True,random_stateaffects the ordering of the indices, which controls the randomness of each fold. Otherwise, this parameter has no effect. Pass an int for reproducible output across multiple function calls. See Glossary.Deprecated since version 1.9:
random_stateis deprecated and will be removed in 1.11. Pass a cross-validation generator ascvargument to specify the random state of the shuffling instead.
- Attributes:
- encodings_list of shape (n_features,) or (n_features * n_classes) of ndarray
Encodings learnt on all of
X. For featurei,encodings_[i]are the encodings matching the categories listed incategories_[i]. Whentarget_type_is “multiclass”, the encoding for featureiand classjis stored inencodings_[j + (i * len(classes_))]. E.g., for 2 features (f) and 3 classes (c), encodings are ordered: f0_c0, f0_c1, f0_c2, f1_c0, f1_c1, f1_c2,- categories_list of shape (n_features,) of ndarray
The categories of each input feature determined during fitting or specified in
categories(in order of the features inXand corresponding with the output oftransform).- target_type_str
Type of target.
- target_mean_float
The overall mean of the target. This value is only used in
transformto encode categories.- n_features_in_int
Number of features seen during fit.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Defined only when
Xhas feature names that are all strings.- classes_ndarray or None
If
target_type_is ‘binary’ or ‘multiclass’, holds the label for each class, otherwiseNone.
See also
OrdinalEncoderPerforms an ordinal (integer) encoding of the categorical features. Contrary to TargetEncoder, this encoding is not supervised. Treating the resulting encoding as a numerical features therefore lead arbitrarily ordered values and therefore typically lead to lower predictive performance when used as preprocessing for a classifier or regressor.
OneHotEncoderPerforms a one-hot encoding of categorical features. This unsupervised encoding is better suited for low cardinality categorical variables as it generate one new feature per unique category.
References
Examples
With
smooth="auto", the smoothing parameter is set to an empirical Bayes estimate:>>> import numpy as np >>> from sklearn.preprocessing import TargetEncoder >>> X = np.array([["dog"] * 20 + ["cat"] * 30 + ["snake"] * 38], dtype=object).T >>> y = [90.3] * 5 + [80.1] * 15 + [20.4] * 5 + [20.1] * 25 + [21.2] * 8 + [49] * 30 >>> enc_auto = TargetEncoder(smooth="auto") >>> X_trans = enc_auto.fit_transform(X, y)
>>> # A high `smooth` parameter puts more weight on global mean on the categorical >>> # encodings: >>> enc_high_smooth = TargetEncoder(smooth=5000.0).fit(X, y) >>> enc_high_smooth.target_mean_ np.float64(44.3) >>> enc_high_smooth.encodings_ [array([44.1, 44.4, 44.3])]
>>> # On the other hand, a low `smooth` parameter puts more weight on target >>> # conditioned on the value of the categorical: >>> enc_low_smooth = TargetEncoder(smooth=1.0).fit(X, y) >>> enc_low_smooth.encodings_ [array([21, 80.8, 43.2])]
- fit(X, y)[source]#
Fit the
TargetEncoderto X and y.It is discouraged to use this method because it can introduce data leakage. Use
fit_transformon training data instead.Note
fit(X, y).transform(X)does not equalfit_transform(X, y)because a cross fitting scheme is used infit_transformfor encoding. See the User Guide for details.- Parameters:
- Xarray-like of shape (n_samples, n_features)
The data to determine the categories of each feature.
- yarray-like of shape (n_samples,)
The target data used to encode the categories.
- Returns:
- selfobject
Fitted encoder.
- fit_transform(X, y, **params)[source]#
Fit
TargetEncoderand transformXwith the target encoding.This method uses a cross fitting scheme to prevent target leakage and overfitting in downstream predictors. It is the recommended method for encoding training data.
Note
fit(X, y).transform(X)does not equalfit_transform(X, y)because a cross fitting scheme is used infit_transformfor encoding. See the User Guide for details.- Parameters:
- Xarray-like of shape (n_samples, n_features)
The data to determine the categories of each feature.
- yarray-like of shape (n_samples,)
The target data used to encode the categories.
- **paramsdict
Parameters to route to the internal CV object.
Can only be used in conjunction with a cross-validation generator as CV object.
For instance,
groups(array-like of shape(n_samples,)) can be routed to a CV splitter that acceptsgroups, such asGroupKFoldorStratifiedGroupKFold.Added in version 1.9: Only available if
enable_metadata_routing=True, which can be set by usingsklearn.set_config(enable_metadata_routing=True). See Metadata Routing User Guide for more details.
- Returns:
- X_transndarray of shape (n_samples, n_features) or (n_samples, (n_features * n_classes))
Transformed input.
- get_feature_names_out(input_features=None)[source]#
Get output feature names for transformation.
- Parameters:
- input_featuresarray-like of str or None, default=None
Not used, present here for API consistency by convention.
- Returns:
- feature_names_outndarray of str objects
Transformed feature names.
feature_names_in_is used unless it is not defined, in which case the following input feature names are generated:["x0", "x1", ..., "x(n_features_in_ - 1)"]. Whentype_of_target_is “multiclass” the names are of the format ‘<feature_name>_<class_name>’.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
Added in version 1.9.
- Returns:
- routingMetadataRouter
A
MetadataRouterencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- set_output(*, transform=None)[source]#
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame output"polars": Polars outputNone: Transform configuration is unchanged
Added in version 1.4:
"polars"option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- transform(X)[source]#
Transform X with the target encoding.
This method internally uses the
encodings_attribute learnt duringTargetEncoder.fit_transformto transform test data.Note
fit(X, y).transform(X)does not equalfit_transform(X, y)because a cross fitting scheme is used infit_transformfor encoding. See the User Guide for details.- Parameters:
- Xarray-like of shape (n_samples, n_features)
The data to determine the categories of each feature.
- Returns:
- X_transndarray of shape (n_samples, n_features) or (n_samples, (n_features * n_classes))
Transformed input.