Note
Go to the end to download the full example code or to run this example in your browser via JupyterLite or Binder.
Introducing the set_output API#
This example will demonstrate the set_output API to configure transformers to
output pandas DataFrames. set_output can be configured per estimator by calling
the set_output method or globally by setting set_config(transform_output="pandas").
For details, see
SLEP018.
First, we load the iris dataset as a DataFrame to demonstrate the set_output API.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
X_train.head()
To configure an estimator such as preprocessing.StandardScaler to return
DataFrames, call set_output. This feature requires pandas to be installed.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().set_output(transform="pandas")
scaler.fit(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled.head()
set_output can be called after fit to configure transform after the fact.
scaler2 = StandardScaler()
scaler2.fit(X_train)
X_test_np = scaler2.transform(X_test)
print(f"Default output type: {type(X_test_np).__name__}")
scaler2.set_output(transform="pandas")
X_test_df = scaler2.transform(X_test)
print(f"Configured pandas output type: {type(X_test_df).__name__}")
Default output type: ndarray
Configured pandas output type: DataFrame
In a pipeline.Pipeline, set_output configures all steps to output
DataFrames.
from sklearn.feature_selection import SelectPercentile
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
clf = make_pipeline(
StandardScaler(), SelectPercentile(percentile=75), LogisticRegression()
)
clf.set_output(transform="pandas")
clf.fit(X_train, y_train)
Each transformer in the pipeline is configured to return DataFrames. This means that the final logistic regression step contains the feature names of the input.
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
Note
If one uses the method set_params, the transformer will be
replaced by a new one with the default output format.
clf.set_params(standardscaler=StandardScaler())
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['x0', 'x2', 'x3'], dtype=object)
To keep the intended behavior, use set_output on the new transformer
beforehand
scaler = StandardScaler().set_output(transform="pandas")
clf.set_params(standardscaler=scaler)
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
Next we load the titanic dataset to demonstrate set_output with
compose.ColumnTransformer and heterogeneous data.
from sklearn.datasets import fetch_openml
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
The set_output API can be configured globally by using set_config and
setting transform_output to "pandas".
from sklearn import set_config
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
set_config(transform_output="pandas")
num_pipe = make_pipeline(SimpleImputer(), StandardScaler())
num_cols = ["age", "fare"]
ct = ColumnTransformer(
(
("numerical", num_pipe, num_cols),
(
"categorical",
OneHotEncoder(
sparse_output=False, drop="if_binary", handle_unknown="ignore"
),
["embarked", "sex", "pclass"],
),
),
verbose_feature_names_out=False,
)
clf = make_pipeline(ct, SelectPercentile(percentile=50), LogisticRegression())
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
/home/circleci/project/sklearn/preprocessing/_encoders.py:262: UserWarning: Found unknown categories in columns [0] during transform. These unknown categories will be encoded as all zeros
warnings.warn(msg, UserWarning)
0.7835365853658537
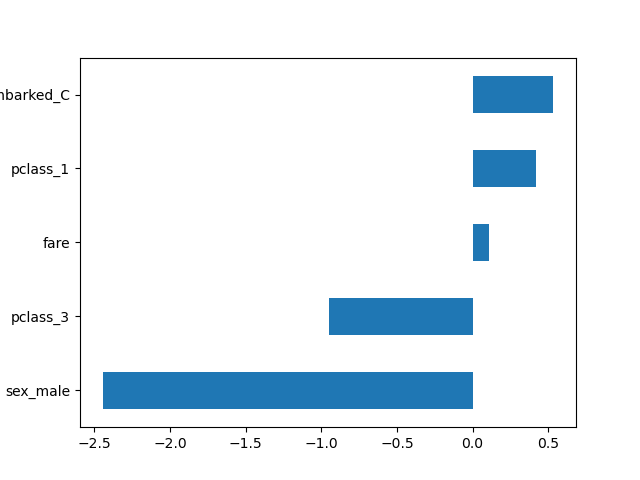
With the global configuration, all transformers output DataFrames. This allows us to easily plot the logistic regression coefficients with the corresponding feature names.
import pandas as pd
log_reg = clf[-1]
coef = pd.Series(log_reg.coef_.ravel(), index=log_reg.feature_names_in_)
_ = coef.sort_values().plot.barh()
In order to demonstrate the config_context functionality below, let
us first reset transform_output to its default value.
set_config(transform_output="default")
When configuring the output type with config_context the
configuration at the time when transform or fit_transform are
called is what counts. Setting these only when you construct or fit
the transformer has no effect.
from sklearn import config_context
scaler = StandardScaler()
scaler.fit(X_train[num_cols])
with config_context(transform_output="pandas"):
# the output of transform will be a Pandas DataFrame
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled.head()
outside of the context manager, the output will be a NumPy array
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled[:5]
array([[-0.4075046 , 0.32947033],
[ 0.00229114, -0.39640224],
[ nan, -0.49483117],
[ 1.09507978, -0.13790203],
[ 0.41208688, -0.39640224]])
Total running time of the script: (0 minutes 0.149 seconds)
Related examples