Note
Go to the end to download the full example code or to run this example in your browser via JupyterLite or Binder.
Plot classification boundaries with different SVM Kernels#
This example shows how different kernels in a SVC (Support Vector
Classifier) influence the classification boundaries in a binary, two-dimensional
classification problem.
SVCs aim to find a hyperplane that effectively separates the classes in their training
data by maximizing the margin between the outermost data points of each class. This is
achieved by finding the best weight vector \(w\) that defines the decision boundary
hyperplane and minimizes the sum of hinge losses for misclassified samples, as measured
by the hinge_loss function. By default, regularization is
applied with the parameter C=1, which allows for a certain degree of misclassification
tolerance.
If the data is not linearly separable in the original feature space, a non-linear kernel
parameter can be set. Depending on the kernel, the process involves adding new features
or transforming existing features to enrich and potentially add meaning to the data.
When a kernel other than "linear" is set, the SVC applies the kernel trick, which
computes the similarity between pairs of data points using the kernel function without
explicitly transforming the entire dataset. The kernel trick surpasses the otherwise
necessary matrix transformation of the whole dataset by only considering the relations
between all pairs of data points. The kernel function maps two vectors (each pair of
observations) to their similarity using their dot product.
The hyperplane can then be calculated using the kernel function as if the dataset were represented in a higher-dimensional space. Using a kernel function instead of an explicit matrix transformation improves performance, as the kernel function has a time complexity of \(O({n}^2)\), whereas matrix transformation scales according to the specific transformation being applied.
In this example, we compare the most common kernel types of Support Vector Machines: the
linear kernel ("linear"), the polynomial kernel ("poly"), the radial basis function
kernel ("rbf") and the sigmoid kernel ("sigmoid").
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Creating a dataset#
We create a two-dimensional classification dataset with 16 samples and two classes. We plot the samples with the colors matching their respective targets.
import matplotlib.pyplot as plt
import numpy as np
X = np.array(
[
[0.4, -0.7],
[-1.5, -1.0],
[-1.4, -0.9],
[-1.3, -1.2],
[-1.1, -0.2],
[-1.2, -0.4],
[-0.5, 1.2],
[-1.5, 2.1],
[1.0, 1.0],
[1.3, 0.8],
[1.2, 0.5],
[0.2, -2.0],
[0.5, -2.4],
[0.2, -2.3],
[0.0, -2.7],
[1.3, 2.1],
]
)
y = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1])
# Plotting settings
fig, ax = plt.subplots(figsize=(4, 3))
x_min, x_max, y_min, y_max = -3, 3, -3, 3
ax.set(xlim=(x_min, x_max), ylim=(y_min, y_max))
# Plot samples by color and add legend
scatter = ax.scatter(X[:, 0], X[:, 1], s=150, c=y, label=y, edgecolors="k")
ax.legend(*scatter.legend_elements(), loc="upper right", title="Classes")
ax.set_title("Samples in two-dimensional feature space")
plt.show()
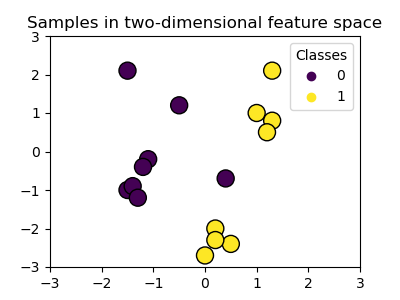
We can see that the samples are not clearly separable by a straight line.
Training SVC model and plotting decision boundaries#
We define a function that fits a SVC classifier,
allowing the kernel parameter as an input, and then plots the decision
boundaries learned by the model using
DecisionBoundaryDisplay.
Notice that for the sake of simplicity, the C parameter is set to its
default value (C=1) in this example and the gamma parameter is set to
gamma=2 across all kernels, although it is automatically ignored for the
linear kernel. In a real classification task, where performance matters,
parameter tuning (by using GridSearchCV for
instance) is highly recommended to capture different structures within the
data.
Setting response_method="predict" in
DecisionBoundaryDisplay colors the areas based
on their predicted class. Using response_method="decision_function" allows
us to also plot the decision boundary and the margins to both sides of it.
Finally the support vectors used during training (which always lay on the
margins) are identified by means of the support_vectors_ attribute of
the trained SVCs, and plotted as well.
from sklearn import svm
from sklearn.inspection import DecisionBoundaryDisplay
def plot_training_data_with_decision_boundary(
kernel, ax=None, long_title=True, support_vectors=True
):
# Train the SVC
clf = svm.SVC(kernel=kernel, gamma=2).fit(X, y)
# Settings for plotting
if ax is None:
_, ax = plt.subplots(figsize=(4, 3))
x_min, x_max, y_min, y_max = -3, 3, -3, 3
ax.set(xlim=(x_min, x_max), ylim=(y_min, y_max))
# Plot decision boundary and margins
common_params = {"estimator": clf, "X": X, "ax": ax}
DecisionBoundaryDisplay.from_estimator(
**common_params,
response_method="predict",
plot_method="pcolormesh",
alpha=0.3,
)
DecisionBoundaryDisplay.from_estimator(
**common_params,
response_method="decision_function",
plot_method="contour",
levels=[-1, 0, 1],
colors=["k", "k", "k"],
linestyles=["--", "-", "--"],
)
if support_vectors:
# Plot bigger circles around samples that serve as support vectors
ax.scatter(
clf.support_vectors_[:, 0],
clf.support_vectors_[:, 1],
s=150,
facecolors="none",
edgecolors="k",
)
# Plot samples by color and add legend
ax.scatter(X[:, 0], X[:, 1], c=y, s=30, edgecolors="k")
ax.legend(*scatter.legend_elements(), loc="upper right", title="Classes")
if long_title:
ax.set_title(f" Decision boundaries of {kernel} kernel in SVC")
else:
ax.set_title(kernel)
if ax is None:
plt.show()
Linear kernel#
Linear kernel is the dot product of the input samples:
It is then applied to any combination of two data points (samples) in the
dataset. The dot product of the two points determines the
cosine_similarity between both points. The
higher the value, the more similar the points are.
plot_training_data_with_decision_boundary("linear")
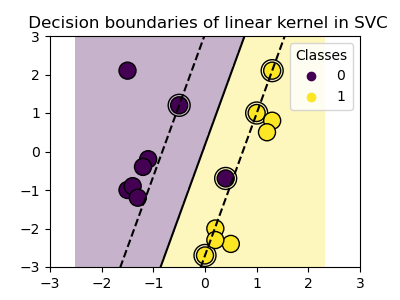
Training a SVC on a linear kernel results in an
untransformed feature space, where the hyperplane and the margins are
straight lines. Due to the lack of expressivity of the linear kernel, the
trained classes do not perfectly capture the training data.
Polynomial kernel#
The polynomial kernel changes the notion of similarity. The kernel function is defined as:
where \({d}\) is the degree (degree) of the polynomial, \({\gamma}\)
(gamma) controls the influence of each individual training sample on the
decision boundary and \({r}\) is the bias term (coef0) that shifts the
data up or down. Here, we use the default value for the degree of the
polynomial in the kernel function (degree=3). When coef0=0 (the default),
the data is only transformed, but no additional dimension is added. Using a
polynomial kernel is equivalent to creating
PolynomialFeatures and then fitting a
SVC with a linear kernel on the transformed data,
although this alternative approach would be computationally expensive for most
datasets.
plot_training_data_with_decision_boundary("poly")
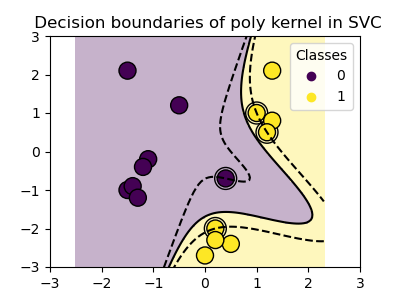
The polynomial kernel with gamma=2 adapts well to the training data,
causing the margins on both sides of the hyperplane to bend accordingly.
RBF kernel#
The radial basis function (RBF) kernel, also known as the Gaussian kernel, is the default kernel for Support Vector Machines in scikit-learn. It measures similarity between two data points in infinite dimensions and then approaches classification by majority vote. The kernel function is defined as:
where \({\gamma}\) (gamma) controls the influence of each individual
training sample on the decision boundary.
The larger the euclidean distance between two points \(\|\mathbf{x}_1 - \mathbf{x}_2\|^2\) the closer the kernel function is to zero. This means that two points far away are more likely to be dissimilar.
plot_training_data_with_decision_boundary("rbf")
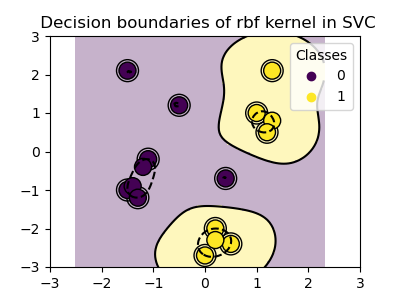
In the plot we can see how the decision boundaries tend to contract around data points that are close to each other.
Sigmoid kernel#
The sigmoid kernel function is defined as:
where the kernel coefficient \({\gamma}\) (gamma) controls the influence
of each individual training sample on the decision boundary and \({r}\) is
the bias term (coef0) that shifts the data up or down.
In the sigmoid kernel, the similarity between two data points is computed using the hyperbolic tangent function (\(\tanh\)). The kernel function scales and possibly shifts the dot product of the two points (\(\mathbf{x}_1\) and \(\mathbf{x}_2\)).
plot_training_data_with_decision_boundary("sigmoid")
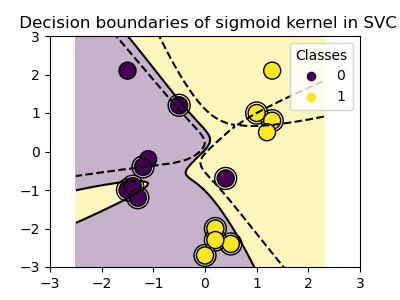
We can see that the decision boundaries obtained with the sigmoid kernel appear curved and irregular. The decision boundary tries to separate the classes by fitting a sigmoid-shaped curve, resulting in a complex boundary that may not generalize well to unseen data. From this example it becomes obvious, that the sigmoid kernel has very specific use cases, when dealing with data that exhibits a sigmoidal shape. In this example, careful fine tuning might find more generalizable decision boundaries. Because of its specificity, the sigmoid kernel is less commonly used in practice compared to other kernels.
Conclusion#
In this example, we have visualized the decision boundaries trained with the provided dataset. The plots serve as an intuitive demonstration of how different kernels utilize the training data to determine the classification boundaries.
The hyperplanes and margins, although computed indirectly, can be imagined as planes in the transformed feature space. However, in the plots, they are represented relative to the original feature space, resulting in curved decision boundaries for the polynomial, RBF, and sigmoid kernels.
Please note that the plots do not evaluate the individual kernel’s accuracy or quality. They are intended to provide a visual understanding of how the different kernels use the training data.
For a comprehensive evaluation, fine-tuning of SVC
parameters using techniques such as
GridSearchCV is recommended to capture the
underlying structures within the data.
XOR dataset#
A classical example of a dataset which is not linearly separable is the XOR pattern. HEre we demonstrate how different kernels work on such a dataset.
xx, yy = np.meshgrid(np.linspace(-3, 3, 500), np.linspace(-3, 3, 500))
np.random.seed(0)
X = np.random.randn(300, 2)
y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)
_, ax = plt.subplots(2, 2, figsize=(8, 8))
args = dict(long_title=False, support_vectors=False)
plot_training_data_with_decision_boundary("linear", ax[0, 0], **args)
plot_training_data_with_decision_boundary("poly", ax[0, 1], **args)
plot_training_data_with_decision_boundary("rbf", ax[1, 0], **args)
plot_training_data_with_decision_boundary("sigmoid", ax[1, 1], **args)
plt.show()
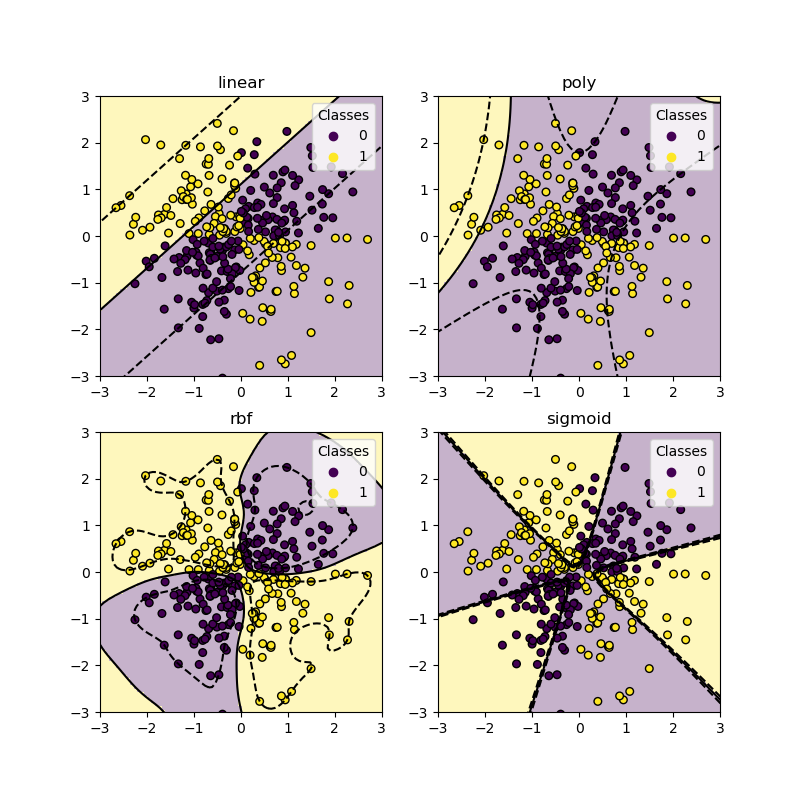
As you can see from the plots above, only the rbf kernel can find a
reasonable decision boundary for the above dataset.
Total running time of the script: (0 minutes 1.630 seconds)
Related examples
Plot different SVM classifiers in the iris dataset