Note
Go to the end to download the full example code or to run this example in your browser via JupyterLite or Binder.
Faces recognition example using eigenfaces and kernel approximation#
This example builds a classical face recognition pipeline on the “Labeled Faces in the Wild” (LFW) dataset, a preprocessed excerpt of which is available here: https://www.kaggle.com/datasets/jessicali9530/lfw-dataset
We reduce the dimensionality of the face images with PCA (the eigenfaces), then
approximate the RBF kernel with Nystroem
and train a LogisticRegression on the resulting
features. The full chain is wrapped in a Pipeline so
that cross-validation does not leak information from the test set. The
hyperparameters are tuned with a successive halving search
(HalvingRandomSearchCV) that minimizes the
log loss. We finally evaluate the model both quantitatively, with a
classification report and one-vs-rest ROC and precision-recall curves, and
qualitatively, by displaying the predictions and the eigenfaces.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Loading the dataset#
We download the Labeled Faces in the Wild (LFW) dataset and load it as numpy arrays. Each sample is a flattened grayscale image; the target is the identity of the person pictured.
from sklearn.datasets import fetch_lfw_people
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# Introspect the image arrays to find the shapes (for plotting).
n_samples, height, width = lfw_people.images.shape
# For machine learning we use the data directly (relative pixel positions are
# ignored by this model).
X = lfw_people.data
n_features = X.shape[1]
# The label to predict is the id of the person.
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print(f"n_samples: {n_samples}")
print(f"n_features: {n_features}")
print(f"n_classes: {n_classes}")
Total dataset size:
n_samples: 1288
n_features: 1850
n_classes: 7
Splitting the dataset#
We hold out 25% of the data for testing. Preprocessing and model fitting are chained in a pipeline below so that scaling and feature extraction are learned only from the training folds during cross-validation.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
Building the model pipeline#
We chain preprocessing and classification in a
Pipeline. PCA extracts eigenfaces as a compact
representation; Nystroem approximates
the RBF feature map so that a linear
LogisticRegression can model non-linear
decision boundaries while scaling better than a kernel SVM. Because logistic
regression outputs calibrated probabilities, we can tune the model by
minimizing the log loss.
from sklearn.decomposition import PCA
from sklearn.kernel_approximation import Nystroem
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
n_components = 150
model = Pipeline(
steps=[
("scaler", StandardScaler()),
("pca", PCA(n_components=n_components, svd_solver="randomized", whiten=True)),
("nystroem", Nystroem(random_state=42)),
("logreg", LogisticRegression(max_iter=5_000)),
]
)
model
Pipeline(steps=[('scaler', StandardScaler()),
('pca',
PCA(n_components=150, svd_solver='randomized', whiten=True)),
('nystroem', Nystroem(random_state=42)),
('logreg', LogisticRegression(max_iter=5000))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
Parameters
Parameters
Parameters
Tuning the pipeline with successive halving#
We tune the gamma and n_components of the Nystroem approximation and
the C regularization of the logistic regression with a successive halving
search (HalvingRandomSearchCV). The search
minimizes the log loss (neg_log_loss) and screens many candidates on small
training subsets before investing compute in the most promising ones. We set
min_resources high enough so that PCA can always extract 150 eigenfaces,
even in the first halving iteration.
from time import time
from scipy.stats import loguniform, randint
from sklearn.experimental import enable_halving_search_cv # noqa: F401
from sklearn.model_selection import HalvingRandomSearchCV
print("Fitting the classifier to the training set")
t0 = time()
param_distributions = {
"nystroem__gamma": loguniform(1e-4, 1e-1),
"nystroem__n_components": randint(50, 200),
"logreg__C": loguniform(1e-2, 1e2),
}
clf = HalvingRandomSearchCV(
model,
param_distributions,
n_candidates=30,
factor=3,
min_resources=300,
scoring="neg_log_loss",
random_state=42,
)
clf = clf.fit(X_train, y_train)
print(f"done in {time() - t0:.3f}s")
Fitting the classifier to the training set
done in 21.472s
print("Best estimator found by successive halving search:")
clf.best_estimator_
Best estimator found by successive halving search:
Pipeline(steps=[('scaler', StandardScaler()),
('pca',
PCA(n_components=150, svd_solver='randomized', whiten=True)),
('nystroem',
Nystroem(gamma=np.float64(0.0011756010900231862),
n_components=173, random_state=42)),
('logreg',
LogisticRegression(C=np.float64(20.651425578959262),
max_iter=5000))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Fitted attributes
Parameters
Fitted attributes
100 of 1,850 features
| x0 |
| x1 |
| x2 |
| x3 |
| x4 |
| x5 |
| x6 |
| x7 |
| x8 |
| x9 |
| x10 |
| x11 |
| x12 |
| x13 |
| x14 |
| x15 |
| x16 |
| x17 |
| x18 |
| x19 |
| x20 |
| x21 |
| x22 |
| x23 |
| x24 |
| x25 |
| x26 |
| x27 |
| x28 |
| x29 |
| x30 |
| x31 |
| x32 |
| x33 |
| x34 |
| x35 |
| x36 |
| x37 |
| x38 |
| x39 |
| x40 |
| x41 |
| x42 |
| x43 |
| x44 |
| x45 |
| x46 |
| x47 |
| x48 |
| x49 |
| x50 |
| x51 |
| x52 |
| x53 |
| x54 |
| x55 |
| x56 |
| x57 |
| x58 |
| x59 |
| x60 |
| x61 |
| x62 |
| x63 |
| x64 |
| x65 |
| x66 |
| x67 |
| x68 |
| x69 |
| x70 |
| x71 |
| x72 |
| x73 |
| x74 |
| x75 |
| x76 |
| x77 |
| x78 |
| x79 |
| x80 |
| x81 |
| x82 |
| x83 |
| x84 |
| x85 |
| x86 |
| x87 |
| x88 |
| x89 |
| x90 |
| x91 |
| x92 |
| x93 |
| x94 |
| x95 |
| x96 |
| x97 |
| x98 |
| x99 |
Parameters
Fitted attributes
100 of 150 features
| pca0 |
| pca1 |
| pca2 |
| pca3 |
| pca4 |
| pca5 |
| pca6 |
| pca7 |
| pca8 |
| pca9 |
| pca10 |
| pca11 |
| pca12 |
| pca13 |
| pca14 |
| pca15 |
| pca16 |
| pca17 |
| pca18 |
| pca19 |
| pca20 |
| pca21 |
| pca22 |
| pca23 |
| pca24 |
| pca25 |
| pca26 |
| pca27 |
| pca28 |
| pca29 |
| pca30 |
| pca31 |
| pca32 |
| pca33 |
| pca34 |
| pca35 |
| pca36 |
| pca37 |
| pca38 |
| pca39 |
| pca40 |
| pca41 |
| pca42 |
| pca43 |
| pca44 |
| pca45 |
| pca46 |
| pca47 |
| pca48 |
| pca49 |
| pca50 |
| pca51 |
| pca52 |
| pca53 |
| pca54 |
| pca55 |
| pca56 |
| pca57 |
| pca58 |
| pca59 |
| pca60 |
| pca61 |
| pca62 |
| pca63 |
| pca64 |
| pca65 |
| pca66 |
| pca67 |
| pca68 |
| pca69 |
| pca70 |
| pca71 |
| pca72 |
| pca73 |
| pca74 |
| pca75 |
| pca76 |
| pca77 |
| pca78 |
| pca79 |
| pca80 |
| pca81 |
| pca82 |
| pca83 |
| pca84 |
| pca85 |
| pca86 |
| pca87 |
| pca88 |
| pca89 |
| pca90 |
| pca91 |
| pca92 |
| pca93 |
| pca94 |
| pca95 |
| pca96 |
| pca97 |
| pca98 |
| pca99 |
Parameters
Fitted attributes
| Name | Type | Value |
|---|---|---|
|
component_indices_
component_indices_: ndarray of shape (n_components) Indices of ``components_`` in the training set. |
ndarray[int64](173,) | [244,467,836,..., 65,141,266] |
|
components_
components_: ndarray of shape (n_components, n_features) Subset of training points used to construct the feature map. |
ndarray[float32](173, 150) | [[ 1.45,-0.18, 0.09,..., 1.9 , 0.87, 0.31], [-0.18,-0.9 , 2.32,..., 0.04,-0.16, 0.08], [ 1.18,-1.99,-0.16,..., 0.71, 1.93,-0.59], ..., [ 1.01, 0.23,-0.32,...,-0.79, 0.48, 0.3 ], [ 2.09, 0.53,-0.95,..., 0.99, 0.14, 0.23], [ 0.28,-0.53, 1.28,..., 1.36,-0.46, 1.92]] |
|
n_features_in_
n_features_in_: int Number of features seen during :term:`fit`. .. versionadded:: 0.24 |
int | 150 |
|
normalization_
normalization_: ndarray of shape (n_components, n_components) Normalization matrix needed for embedding. Square root of the kernel matrix on ``components_``. |
ndarray[float32](173, 173) | [[ 2.91, 0.02,-0.11,..., 0.05,-0.15, 0.07], [ 0.02, 1.55, 0.02,...,-0.02,-0.01, 0.1 ], [-0.11, 0.02, 2.4 ,..., 0.16,-0.09,-0.02], ..., [ 0.05,-0.02, 0.16,..., 3.14, 0.04,-0.05], [-0.15,-0.01,-0.09,..., 0.04, 3.66,-0.13], [ 0.07, 0.1 ,-0.02,...,-0.05,-0.13, 2.41]] |
100 of 173 features
| nystroem0 |
| nystroem1 |
| nystroem2 |
| nystroem3 |
| nystroem4 |
| nystroem5 |
| nystroem6 |
| nystroem7 |
| nystroem8 |
| nystroem9 |
| nystroem10 |
| nystroem11 |
| nystroem12 |
| nystroem13 |
| nystroem14 |
| nystroem15 |
| nystroem16 |
| nystroem17 |
| nystroem18 |
| nystroem19 |
| nystroem20 |
| nystroem21 |
| nystroem22 |
| nystroem23 |
| nystroem24 |
| nystroem25 |
| nystroem26 |
| nystroem27 |
| nystroem28 |
| nystroem29 |
| nystroem30 |
| nystroem31 |
| nystroem32 |
| nystroem33 |
| nystroem34 |
| nystroem35 |
| nystroem36 |
| nystroem37 |
| nystroem38 |
| nystroem39 |
| nystroem40 |
| nystroem41 |
| nystroem42 |
| nystroem43 |
| nystroem44 |
| nystroem45 |
| nystroem46 |
| nystroem47 |
| nystroem48 |
| nystroem49 |
| nystroem50 |
| nystroem51 |
| nystroem52 |
| nystroem53 |
| nystroem54 |
| nystroem55 |
| nystroem56 |
| nystroem57 |
| nystroem58 |
| nystroem59 |
| nystroem60 |
| nystroem61 |
| nystroem62 |
| nystroem63 |
| nystroem64 |
| nystroem65 |
| nystroem66 |
| nystroem67 |
| nystroem68 |
| nystroem69 |
| nystroem70 |
| nystroem71 |
| nystroem72 |
| nystroem73 |
| nystroem74 |
| nystroem75 |
| nystroem76 |
| nystroem77 |
| nystroem78 |
| nystroem79 |
| nystroem80 |
| nystroem81 |
| nystroem82 |
| nystroem83 |
| nystroem84 |
| nystroem85 |
| nystroem86 |
| nystroem87 |
| nystroem88 |
| nystroem89 |
| nystroem90 |
| nystroem91 |
| nystroem92 |
| nystroem93 |
| nystroem94 |
| nystroem95 |
| nystroem96 |
| nystroem97 |
| nystroem98 |
| nystroem99 |
Parameters
Fitted attributes
Quantitative evaluation#
We measure the model quality on the held-out test set with a classification report and, since the probabilities are well calibrated, one-vs-rest ROC and precision-recall curves. The pipeline handles preprocessing internally.
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
from sklearn.preprocessing import label_binarize
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test)
y_score = clf.predict_proba(X_test)
print(f"done in {time() - t0:.3f}s")
print(classification_report(y_test, y_pred, target_names=target_names))
Predicting people's names on the test set
done in 0.013s
precision recall f1-score support
Ariel Sharon 0.64 0.54 0.58 13
Colin Powell 0.79 0.87 0.83 60
Donald Rumsfeld 0.77 0.63 0.69 27
George W Bush 0.87 0.95 0.91 146
Gerhard Schroeder 0.68 0.68 0.68 25
Hugo Chavez 0.80 0.53 0.64 15
Tony Blair 0.90 0.72 0.80 36
accuracy 0.83 322
macro avg 0.78 0.70 0.73 322
weighted avg 0.82 0.83 0.82 322
Because the problem is multiclass, we summarize the ranking quality of the predicted probabilities with one-vs-rest curves: each identity is in turn treated as the positive class against all the others. The ROC curve relates the true positive rate to the false positive rate, while the precision-recall curve is more informative when the positive class is rare, as is the case here where each identity is a small fraction of the test set.
from sklearn.metrics import PrecisionRecallDisplay, RocCurveDisplay
classes = list(range(n_classes))
y_onehot_test = label_binarize(y_test, classes=classes)
fig, (ax_roc, ax_pr) = plt.subplots(1, 2, figsize=(13, 6))
for class_id, name in enumerate(target_names):
RocCurveDisplay.from_predictions(
y_onehot_test[:, class_id],
y_score[:, class_id],
name=name,
ax=ax_roc,
plot_chance_level=(class_id == n_classes - 1),
)
PrecisionRecallDisplay.from_predictions(
y_onehot_test[:, class_id],
y_score[:, class_id],
name=name,
ax=ax_pr,
)
ax_roc.set_title("One-vs-rest ROC curves")
ax_pr.set_title("One-vs-rest precision-recall curves")
plt.tight_layout()
plt.show()
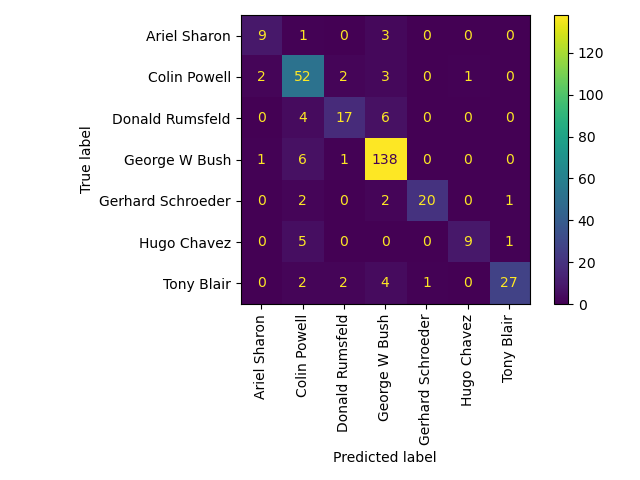
Qualitative evaluation#
We visualize a gallery of test portraits with their predicted and true labels to inspect the model’s mistakes at a glance.
def plot_gallery(images, titles, height, width, n_row=3, n_col=4):
"""Plot a gallery of portraits."""
fig, axs = plt.subplots(n_row, n_col, figsize=(1.8 * n_col, 2.4 * n_row))
fig.subplots_adjust(bottom=0, left=0.01, right=0.99, top=0.90, hspace=0.35)
for ax, image, title in zip(axs.ravel(), images, titles):
ax.imshow(image.reshape((height, width)), cmap=plt.cm.gray)
ax.set_title(title, size=12)
ax.set_xticks(())
ax.set_yticks(())
return fig
def make_title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(" ", 1)[-1]
true_name = target_names[y_test[i]].rsplit(" ", 1)[-1]
return f"predicted: {pred_name}\ntrue: {true_name}"
prediction_titles = [
make_title(y_pred, y_test, target_names, i) for i in range(y_pred.shape[0])
]
plot_gallery(X_test, prediction_titles, height, width)

<Figure size 720x720 with 12 Axes>
Eigenfaces gallery#
We display the most significant eigenfaces, i.e. the principal components that form the basis of the face representation learned by the fitted pipeline.
pca = clf.best_estimator_.named_steps["pca"]
eigenfaces = pca.components_.reshape((pca.n_components_, height, width))
eigenface_titles = [f"eigenface {i}" for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, height, width)
plt.show()

Conclusion#
This example walks through a classical face recognition pipeline in scikit-learn:
Eigenfaces (PCA) reduce the high-dimensional pixel space to a compact set of uncorrelated features that capture the main variations across faces.
Nystroem + LogisticRegression approximate a non-linear RBF kernel with a linear model that scales better than a kernel SVM and is tuned to minimize the log loss.
Pipeline chains preprocessing and classification so that cross-validation does not leak information from the test set.
Quantitative and qualitative evaluation on a held-out test set confirm whether the pipeline generalizes. The one-vs-rest ROC and precision-recall curves show how well the predicted probabilities rank each identity against the others, independently of any single decision threshold.
In practice, face recognition is often better addressed with convolutional neural networks, but this family of models is outside the scope of the scikit-learn library. Interested readers should instead try PyTorch or TensorFlow to implement such models.
Total running time of the script: (0 minutes 22.607 seconds)
Related examples
Multiclass Receiver Operating Characteristic (ROC)
Receiver Operating Characteristic (ROC) with cross validation
Analysis of the convergence of penalized logistic regression models
