classification_report#
- sklearn.metrics.classification_report(y_true, y_pred, *, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False, zero_division='warn')[source]#
Build a text report showing the main classification metrics.
Read more in the User Guide.
- Parameters:
- y_true1d array-like, or label indicator array / sparse matrix
Ground truth (correct) target values. Sparse matrix is only supported when targets are of multilabel type.
- y_pred1d array-like, or label indicator array / sparse matrix
Estimated targets as returned by a classifier. Sparse matrix is only supported when targets are of multilabel type.
- labelsarray-like of shape (n_labels,), default=None
Optional list of label indices to include in the report.
- target_namesarray-like of shape (n_labels,), default=None
Optional display names matching the labels (same order).
- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- digitsint, default=2
Number of digits for formatting output floating point values. When
output_dictisTrue, this will be ignored and the returned values will not be rounded.- output_dictbool, default=False
If True, return output as dict.
Added in version 0.20.
- zero_division{“warn”, 0.0, 1.0, np.nan}, default=”warn”
Sets the value to return when there is a zero division. If set to “warn”, this acts as 0, but warnings are also raised.
Added in version 1.3:
np.nanoption was added.
- Returns:
- reportstr or dict
Text summary of the precision, recall, F1 score for each class. Dictionary returned if output_dict is True. Dictionary has the following structure:
{'label 1': {'precision':0.5, 'recall':1.0, 'f1-score':0.67, 'support':1}, 'label 2': { ... }, ... }
The reported averages include macro average (averaging the unweighted mean per label), weighted average (averaging the support-weighted mean per label), and sample average (only for multilabel classification). Micro average (averaging the total true positives, false negatives and false positives) is only shown for multi-label or multi-class with a subset of classes, because it corresponds to accuracy otherwise and would be the same for all metrics. See also
precision_recall_fscore_supportfor more details on averages.Note that in binary classification, recall of the positive class is also known as “sensitivity”; recall of the negative class is “specificity”.
See also
precision_recall_fscore_supportCompute precision, recall, F-measure and support for each class.
confusion_matrixCompute confusion matrix to evaluate the accuracy of a classification.
multilabel_confusion_matrixCompute a confusion matrix for each class or sample.
Examples
>>> from sklearn.metrics import classification_report >>> y_true = [0, 1, 2, 2, 2] >>> y_pred = [0, 0, 2, 2, 1] >>> target_names = ['class 0', 'class 1', 'class 2'] >>> print(classification_report(y_true, y_pred, target_names=target_names)) precision recall f1-score support class 0 0.50 1.00 0.67 1 class 1 0.00 0.00 0.00 1 class 2 1.00 0.67 0.80 3 accuracy 0.60 5 macro avg 0.50 0.56 0.49 5 weighted avg 0.70 0.60 0.61 5 >>> y_pred = [1, 1, 0] >>> y_true = [1, 1, 1] >>> print(classification_report(y_true, y_pred, labels=[1, 2, 3])) precision recall f1-score support 1 1.00 0.67 0.80 3 2 0.00 0.00 0.00 0 3 0.00 0.00 0.00 0 micro avg 1.00 0.67 0.80 3 macro avg 0.33 0.22 0.27 3 weighted avg 1.00 0.67 0.80 3
Gallery examples#
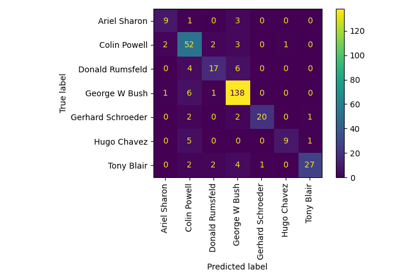
Faces recognition example using eigenfaces and kernel approximation
Column Transformer with Heterogeneous Data Sources


Custom refit strategy of a grid search with cross-validation

Restricted Boltzmann Machine features for digit classification
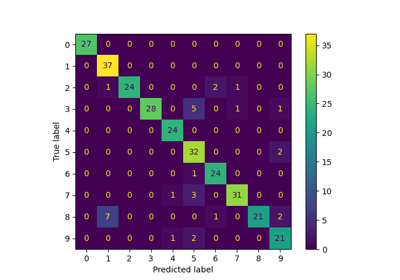
Label Propagation digits: Demonstrating performance

