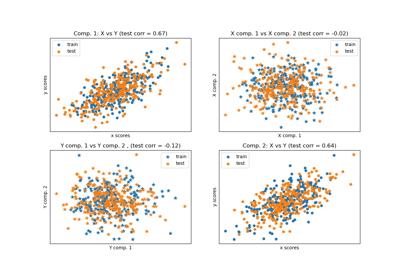
CCA#
- class sklearn.cross_decomposition.CCA(n_components=2, *, scale=True, max_iter=500, tol=1e-06, copy=True)[source]#
Canonical Correlation Analysis, also known as “Mode B” PLS.
For a comparison between other cross decomposition algorithms, see Compare cross decomposition methods.
Read more in the User Guide.
- Parameters:
- n_componentsint, default=2
Number of components to keep. Should be in
[1, min(n_samples, n_features, n_targets)].- scalebool, default=True
Whether to scale
Xandy.- max_iterint, default=500
The maximum number of iterations of the power method.
- tolfloat, default=1e-06
The tolerance used as convergence criteria in the power method: the algorithm stops whenever the squared norm of
u_i - u_{i-1}is less thantol, whereucorresponds to the left singular vector.- copybool, default=True
Whether to copy
Xandyin fit before applying centering, and potentially scaling. If False, these operations will be done inplace, modifying both arrays.
- Attributes:
- x_weights_ndarray of shape (n_features, n_components)
The left singular vectors of the cross-covariance matrices of each iteration.
- y_weights_ndarray of shape (n_targets, n_components)
The right singular vectors of the cross-covariance matrices of each iteration.
- x_loadings_ndarray of shape (n_features, n_components)
The loadings of
X.- y_loadings_ndarray of shape (n_targets, n_components)
The loadings of
y.- x_rotations_ndarray of shape (n_features, n_components)
The projection matrix used to transform
X.- y_rotations_ndarray of shape (n_targets, n_components)
The projection matrix used to transform
y.- coef_ndarray of shape (n_targets, n_features)
The coefficients of the linear model such that
yis approximated asy = X @ coef_.T + intercept_.- intercept_ndarray of shape (n_targets,)
The intercepts of the linear model such that
yis approximated asy = X @ coef_.T + intercept_.Added in version 1.1.
- n_iter_list of shape (n_components,)
Number of iterations of the power method, for each component.
- n_features_in_int
Number of features seen during fit.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Defined only when
Xhas feature names that are all strings.Added in version 1.0.
See also
PLSCanonicalPartial Least Squares transformer and regressor.
PLSSVDPartial Least Square SVD.
Examples
>>> from sklearn.cross_decomposition import CCA >>> X = [[0., 0., 1.], [1.,0.,0.], [2.,2.,2.], [3.,5.,4.]] >>> y = [[0.1, -0.2], [0.9, 1.1], [6.2, 5.9], [11.9, 12.3]] >>> cca = CCA(n_components=1) >>> cca.fit(X, y) CCA(n_components=1) >>> X_c, y_c = cca.transform(X, y)
- fit(X, y)[source]#
Fit model to data.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Training vectors, where
n_samplesis the number of samples andn_featuresis the number of predictors.- yarray-like of shape (n_samples,) or (n_samples, n_targets)
Target vectors, where
n_samplesis the number of samples andn_targetsis the number of response variables.
- Returns:
- selfobject
Fitted model.
- fit_transform(X, y=None)[source]#
Learn and apply the dimension reduction on the train data.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Training vectors, where
n_samplesis the number of samples andn_featuresis the number of predictors.- yarray-like of shape (n_samples, n_targets), default=None
Target vectors, where
n_samplesis the number of samples andn_targetsis the number of response variables.
- Returns:
- selfndarray of shape (n_samples, n_components)
Return
x_scoresifyis not given,(x_scores, y_scores)otherwise.
- get_feature_names_out(input_features=None)[source]#
Get output feature names for transformation.
The feature names out will prefixed by the lowercased class name. For example, if the transformer outputs 3 features, then the feature names out are:
["class_name0", "class_name1", "class_name2"].- Parameters:
- input_featuresarray-like of str or None, default=None
Only used to validate feature names with the names seen in
fit.
- Returns:
- feature_names_outndarray of str objects
Transformed feature names.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- inverse_transform(X, y=None)[source]#
Transform data back to its original space.
- Parameters:
- Xarray-like of shape (n_samples, n_components)
New data, where
n_samplesis the number of samples andn_componentsis the number of pls components.- yarray-like of shape (n_samples,) or (n_samples, n_components)
New target, where
n_samplesis the number of samples andn_componentsis the number of pls components.
- Returns:
- X_originalndarray of shape (n_samples, n_features)
Return the reconstructed
Xdata.- y_originalndarray of shape (n_samples, n_targets)
Return the reconstructed
Xtarget. Only returned whenyis given.
Notes
This transformation will only be exact if
n_components=n_features.
- predict(X, copy=True)[source]#
Predict targets of given samples.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Samples.
- copybool, default=True
Whether to copy
Xor perform in-place normalization.
- Returns:
- y_predndarray of shape (n_samples,) or (n_samples, n_targets)
Returns predicted values.
Notes
This call requires the estimation of a matrix of shape
(n_features, n_targets), which may be an issue in high dimensional space.
- score(X, y, sample_weight=None)[source]#
Return coefficient of determination on test data.
The coefficient of determination, \(R^2\), is defined as \((1 - \frac{u}{v})\), where \(u\) is the residual sum of squares
((y_true - y_pred)** 2).sum()and \(v\) is the total sum of squares((y_true - y_true.mean()) ** 2).sum(). The best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value ofy, disregarding the input features, would get a \(R^2\) score of 0.0.- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test samples. For some estimators this may be a precomputed kernel matrix or a list of generic objects instead with shape
(n_samples, n_samples_fitted), wheren_samples_fittedis the number of samples used in the fitting for the estimator.- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True values for
X.- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
\(R^2\) of
self.predict(X)w.r.t.y.
Notes
The \(R^2\) score used when calling
scoreon a regressor usesmultioutput='uniform_average'from version 0.23 to keep consistent with default value ofr2_score. This influences thescoremethod of all the multioutput regressors (except forMultiOutputRegressor).
- set_output(*, transform=None)[source]#
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame output"polars": Polars outputNone: Transform configuration is unchanged
Added in version 1.4:
"polars"option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_predict_request(*, copy: bool | None | str = '$UNCHANGED$') CCA[source]#
Configure whether metadata should be requested to be passed to the
predictmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- copystr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
copyparameter inpredict.
- Returns:
- selfobject
The updated object.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') CCA[source]#
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') CCA[source]#
Configure whether metadata should be requested to be passed to the
transformmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed totransformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it totransform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- copystr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
copyparameter intransform.
- Returns:
- selfobject
The updated object.
- transform(X, y=None, copy=True)[source]#
Apply the dimension reduction.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Samples to transform.
- yarray-like of shape (n_samples, n_targets), default=None
Target vectors.
- copybool, default=True
Whether to copy
Xandy, or perform in-place normalization.
- Returns:
- x_scores, y_scoresarray-like or tuple of array-like
Return
x_scoresifyis not given,(x_scores, y_scores)otherwise.