Normalizer#
- class sklearn.preprocessing.Normalizer(norm='l2', *, copy=True)[source]#
Normalize samples individually to unit norm.
Each sample (i.e. each row of the data matrix) with at least one non zero component is rescaled independently of other samples so that its norm (l1, l2 or inf) equals one.
This transformer is able to work both with dense numpy arrays and scipy.sparse matrix (use CSR format if you want to avoid the burden of a copy / conversion).
Scaling inputs to unit norms is a common operation for text classification or clustering for instance. For instance the dot product of two l2-normalized TF-IDF vectors is the cosine similarity of the vectors and is the base similarity metric for the Vector Space Model commonly used by the Information Retrieval community.
For an example visualization, refer to Compare Normalizer with other scalers.
Read more in the User Guide.
- Parameters:
- norm{‘l1’, ‘l2’, ‘max’}, default=’l2’
The norm to use to normalize each non zero sample. If norm=’max’ is used, values will be rescaled by the maximum of the absolute values.
- copybool, default=True
Set to False to perform inplace row normalization and avoid a copy (if the input is already a numpy array or a scipy.sparse CSR matrix).
- Attributes:
See also
normalizeEquivalent function without the estimator API.
Notes
This estimator is stateless and does not need to be fitted. However, we recommend to call
fit_transforminstead oftransform, as parameter validation is only performed infit.Examples
>>> from sklearn.preprocessing import Normalizer >>> X = [[4, 1, 2, 2], ... [1, 3, 9, 3], ... [5, 7, 5, 1]] >>> transformer = Normalizer().fit(X) # fit does nothing. >>> transformer Normalizer() >>> transformer.transform(X) array([[0.8, 0.2, 0.4, 0.4], [0.1, 0.3, 0.9, 0.3], [0.5, 0.7, 0.5, 0.1]])
- fit(X, y=None)[source]#
Only validates estimator’s parameters.
This method allows to: (i) validate the estimator’s parameters and (ii) be consistent with the scikit-learn transformer API.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
The data to estimate the normalization parameters.
- yIgnored
Not used, present here for API consistency by convention.
- Returns:
- selfobject
Fitted transformer.
- fit_transform(X, y=None, **fit_params)[source]#
Fit to data, then transform it.
Fits transformer to
Xandywith optional parametersfit_paramsand returns a transformed version ofX.- Parameters:
- Xarray-like of shape (n_samples, n_features)
Input samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
Target values (None for unsupervised transformations).
- **fit_paramsdict
Additional fit parameters. Pass only if the estimator accepts additional params in its
fitmethod.
- Returns:
- X_newndarray array of shape (n_samples, n_features_new)
Transformed array.
- get_feature_names_out(input_features=None)[source]#
Get output feature names for transformation.
- Parameters:
- input_featuresarray-like of str or None, default=None
Input features.
If
input_featuresisNone, thenfeature_names_in_is used as feature names in. Iffeature_names_in_is not defined, then the following input feature names are generated:["x0", "x1", ..., "x(n_features_in_ - 1)"].If
input_featuresis an array-like, theninput_featuresmust matchfeature_names_in_iffeature_names_in_is defined.
- Returns:
- feature_names_outndarray of str objects
Same as input features.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- set_output(*, transform=None)[source]#
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame output"polars": Polars outputNone: Transform configuration is unchanged
Added in version 1.4:
"polars"option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') Normalizer[source]#
Configure whether metadata should be requested to be passed to the
transformmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed totransformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it totransform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- copystr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
copyparameter intransform.
- Returns:
- selfobject
The updated object.
- transform(X, copy=None)[source]#
Scale each non zero row of X to unit norm.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
The data to normalize, row by row. scipy.sparse matrices should be in CSR format to avoid an un-necessary copy.
- copybool, default=None
Copy the input X or not.
- Returns:
- X_tr{ndarray, sparse matrix} of shape (n_samples, n_features)
Transformed array.
Gallery examples#
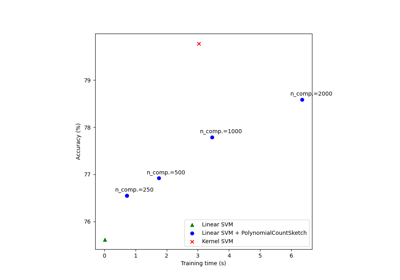
Scalable learning with polynomial kernel approximation
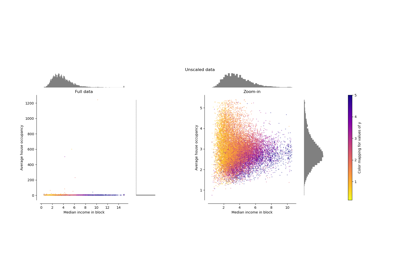
Compare the effect of different scalers on data with outliers