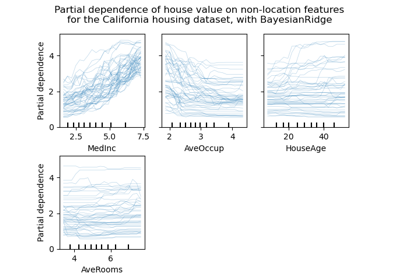
fetch_california_housing#
- sklearn.datasets.fetch_california_housing(*, data_home=None, download_if_missing=True, return_X_y=False, as_frame=False, n_retries=3, delay=1.0)[source]#
Load the California housing dataset (regression).
Samples total
20640
Dimensionality
8
Features
real
Target
real 0.15 - 5.
Read more in the User Guide.
- Parameters:
- data_homestr or path-like, default=None
Specify another download and cache folder for the datasets. By default all scikit-learn data is stored in ‘~/scikit_learn_data’ subfolders.
- download_if_missingbool, default=True
If False, raise an OSError if the data is not locally available instead of trying to download the data from the source site.
- return_X_ybool, default=False
If True, returns
(data.data, data.target)instead of a Bunch object.Added in version 0.20.
- as_framebool, default=False
If True, the data is a pandas DataFrame including columns with appropriate dtypes (numeric, string or categorical). The target is a pandas DataFrame or Series depending on the number of target_columns.
Added in version 0.23.
- n_retriesint, default=3
Number of retries when HTTP errors are encountered.
Added in version 1.5.
- delayfloat, default=1.0
Number of seconds between retries.
Added in version 1.5.
- Returns:
- dataset
Bunch Dictionary-like object, with the following attributes.
- datandarray, shape (20640, 8)
Each row corresponding to the 8 feature values in order. If
as_frameis True,datais a pandas object.- targetnumpy array of shape (20640,)
Each value corresponds to the median house value in units of 100,000. If
as_frameis True,targetis a pandas object.- feature_nameslist of length 8
Array of ordered feature names used in the dataset.
- DESCRstr
Description of the California housing dataset.
- framepandas DataFrame
Only present when
as_frame=True. DataFrame withdataandtarget.Added in version 0.23.
- (data, target)tuple if
return_X_yis True A tuple of two ndarray. The first containing a 2D array of shape (n_samples, n_features) with each row representing one sample and each column representing the features. The second ndarray of shape (n_samples,) containing the target samples.
Added in version 0.20.
- dataset
Notes
This dataset consists of 20,640 samples and 9 features.
Examples
>>> from sklearn.datasets import fetch_california_housing >>> housing = fetch_california_housing() >>> print(housing.data.shape, housing.target.shape) (20640, 8) (20640,) >>> print(housing.feature_names[0:6]) ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup']
Gallery examples#

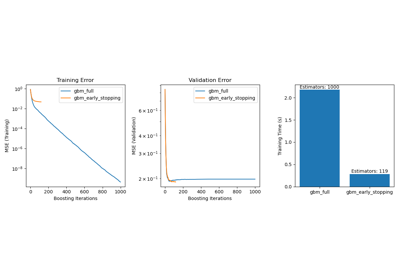
Comparing Random Forests and Histogram Gradient Boosting models
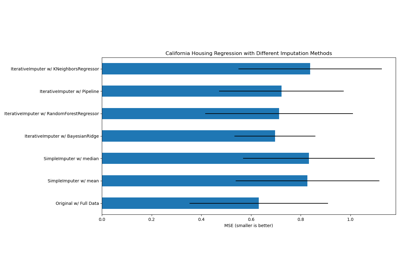
Imputing missing values with variants of IterativeImputer
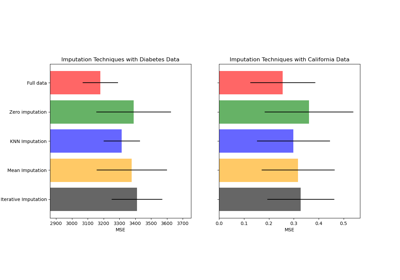
Imputing missing values before building an estimator
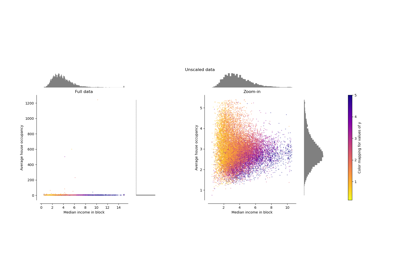
Compare the effect of different scalers on data with outliers