VotingRegressor#
- class sklearn.ensemble.VotingRegressor(estimators, *, weights=None, n_jobs=None, verbose=False)[source]#
Prediction voting regressor for unfitted estimators.
A voting regressor is an ensemble meta-estimator that fits several base regressors, each on the whole dataset. Then it averages the individual predictions to form a final prediction.
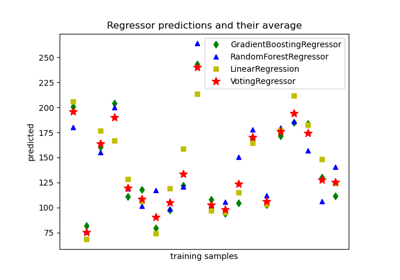
For a detailed example, refer to Plot individual and voting regression predictions.
Read more in the User Guide.
Added in version 0.21.
- Parameters:
- estimatorslist of (str, estimator) tuples
Invoking the
fitmethod on theVotingRegressorwill fit clones of those original estimators that will be stored in the class attributeself.estimators_. An estimator can be set to'drop'usingset_params.Changed in version 0.21:
'drop'is accepted. Using None was deprecated in 0.22 and support was removed in 0.24.- weightsarray-like of shape (n_regressors,), default=None
Sequence of weights (
floatorint) to weight the occurrences of predicted values before averaging. Uses uniform weights ifNone.- n_jobsint, default=None
The number of jobs to run in parallel for
fit.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. See Glossary for more details.- verbosebool, default=False
If True, the time elapsed while fitting will be printed as it is completed.
Added in version 0.23.
- Attributes:
- estimators_list of regressors
The collection of fitted sub-estimators as defined in
estimatorsthat are not ‘drop’.- named_estimators_
Bunch Attribute to access any fitted sub-estimators by name.
Added in version 0.20.
n_features_in_intNumber of features seen during fit.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Only defined if the underlying estimators expose such an attribute when fit.
Added in version 1.0.
See also
VotingClassifierSoft Voting/Majority Rule classifier.
Examples
>>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> from sklearn.ensemble import RandomForestRegressor >>> from sklearn.ensemble import VotingRegressor >>> from sklearn.neighbors import KNeighborsRegressor >>> r1 = LinearRegression() >>> r2 = RandomForestRegressor(n_estimators=10, random_state=1) >>> r3 = KNeighborsRegressor() >>> X = np.array([[1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36]]) >>> y = np.array([2, 6, 12, 20, 30, 42]) >>> er = VotingRegressor([('lr', r1), ('rf', r2), ('r3', r3)]) >>> print(er.fit(X, y).predict(X)) [ 6.8 8.4 12.5 17.8 26 34]
In the following example, we drop the
'lr'estimator withset_paramsand fit the remaining two estimators:>>> er = er.set_params(lr='drop') >>> er = er.fit(X, y) >>> len(er.estimators_) 2
- fit(X, y, **fit_params)[source]#
Fit the estimators.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
Training vectors, where
n_samplesis the number of samples andn_featuresis the number of features.- yarray-like of shape (n_samples,)
Target values.
- **fit_paramsdict
Parameters to pass to the underlying estimators.
Added in version 1.5: Only available if
enable_metadata_routing=True, which can be set by usingsklearn.set_config(enable_metadata_routing=True). See Metadata Routing User Guide for more details.
- Returns:
- selfobject
Fitted estimator.
- fit_transform(X, y=None, **fit_params)[source]#
Return class labels or probabilities for each estimator.
Return predictions for X for each estimator.
- Parameters:
- X{array-like, sparse matrix, dataframe} of shape (n_samples, n_features)
Input samples.
- yndarray of shape (n_samples,), default=None
Target values (None for unsupervised transformations).
- **fit_paramsdict
Additional fit parameters.
- Returns:
- X_newndarray array of shape (n_samples, n_features_new)
Transformed array.
- get_feature_names_out(input_features=None)[source]#
Get output feature names for transformation.
- Parameters:
- input_featuresarray-like of str or None, default=None
Not used, present here for API consistency by convention.
- Returns:
- feature_names_outndarray of str objects
Transformed feature names.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
Added in version 1.5.
- Returns:
- routingMetadataRouter
A
MetadataRouterencapsulating routing information.
- get_params(deep=True)[source]#
Get the parameters of an estimator from the ensemble.
Returns the parameters given in the constructor as well as the estimators contained within the
estimatorsparameter.- Parameters:
- deepbool, default=True
Setting it to True gets the various estimators and the parameters of the estimators as well.
- Returns:
- paramsdict
Parameter and estimator names mapped to their values or parameter names mapped to their values.
- predict(X)[source]#
Predict regression target for X.
The predicted regression target of an input sample is computed as the mean predicted regression targets of the estimators in the ensemble.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
The input samples.
- Returns:
- yndarray of shape (n_samples,)
The predicted values.
- score(X, y, sample_weight=None)[source]#
Return coefficient of determination on test data.
The coefficient of determination, \(R^2\), is defined as \((1 - \frac{u}{v})\), where \(u\) is the residual sum of squares
((y_true - y_pred)** 2).sum()and \(v\) is the total sum of squares((y_true - y_true.mean()) ** 2).sum(). The best possible score is 1.0 and it can be negative (because the model can be arbitrarily worse). A constant model that always predicts the expected value ofy, disregarding the input features, would get a \(R^2\) score of 0.0.- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test samples. For some estimators this may be a precomputed kernel matrix or a list of generic objects instead with shape
(n_samples, n_samples_fitted), wheren_samples_fittedis the number of samples used in the fitting for the estimator.- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True values for
X.- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
\(R^2\) of
self.predict(X)w.r.t.y.
Notes
The \(R^2\) score used when calling
scoreon a regressor usesmultioutput='uniform_average'from version 0.23 to keep consistent with default value ofr2_score. This influences thescoremethod of all the multioutput regressors (except forMultiOutputRegressor).
- set_output(*, transform=None)[source]#
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame output"polars": Polars outputNone: Transform configuration is unchanged
Added in version 1.4:
"polars"option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of an estimator from the ensemble.
Valid parameter keys can be listed with
get_params(). Note that you can directly set the parameters of the estimators contained inestimators.- Parameters:
- **paramskeyword arguments
Specific parameters using e.g.
set_params(parameter_name=new_value). In addition, to setting the parameters of the estimator, the individual estimator of the estimators can also be set, or can be removed by setting them to ‘drop’.
- Returns:
- selfobject
Estimator instance.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') VotingRegressor[source]#
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.