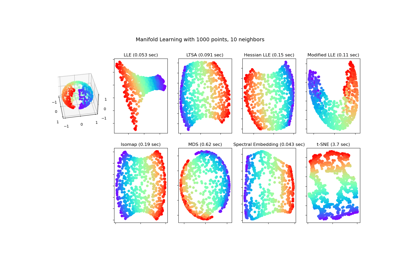
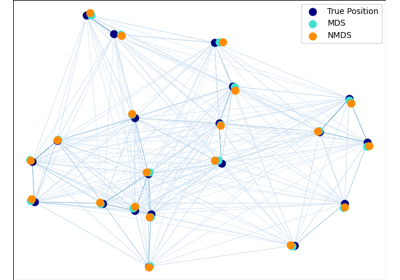
MDS#
- class sklearn.manifold.MDS(n_components=2, *, metric_mds=True, n_init=1, init='warn', max_iter=300, verbose=0, eps=1e-06, n_jobs=None, random_state=None, dissimilarity='deprecated', metric='euclidean', metric_params=None, normalized_stress='auto')[source]#
Multidimensional scaling.
Read more in the User Guide.
- Parameters:
- n_componentsint, default=2
Number of dimensions in which to immerse the dissimilarities.
- metric_mdsbool, default=True
If
True, perform metric MDS; otherwise, perform nonmetric MDS. WhenFalse(i.e. non-metric MDS), dissimilarities with 0 are considered as missing values.Changed in version 1.8: The parameter
metricwas renamed intometric_mds.- n_initint, default=1
Number of times the SMACOF algorithm will be run with different initializations. The final results will be the best output of the runs, determined by the run with the smallest final stress.
Changed in version 1.9: The default value for
n_initchanged from 4 to 1.- init{‘random’, ‘classical_mds’}, default=’random’
The initialization approach. If
random, random initialization is used. Ifclassical_mds, then classical MDS is run and used as initialization for MDS (in this case, the value ofn_initis ignored).Added in version 1.8.
Changed in version 1.10: The default value for
initwill change toclassical_mds.- max_iterint, default=300
Maximum number of iterations of the SMACOF algorithm for a single run.
- verboseint, default=0
Level of verbosity.
- epsfloat, default=1e-6
The tolerance with respect to stress (normalized by the sum of squared embedding distances) at which to declare convergence.
Changed in version 1.7: The default value for
epshas changed from 1e-3 to 1e-6, as a result of a bugfix in the computation of the convergence criterion.- n_jobsint, default=None
The number of jobs to use for the computation. If multiple initializations are used (
n_init), each run of the algorithm is computed in parallel.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. See Glossary for more details.- random_stateint, RandomState instance or None, default=None
Determines the random number generator used to initialize the centers. Pass an int for reproducible results across multiple function calls. See Glossary.
- dissimilarity{‘euclidean’, ‘precomputed’}
Dissimilarity measure to use:
- ‘euclidean’:
Pairwise Euclidean distances between points in the dataset.
- ‘precomputed’:
Pre-computed dissimilarities are passed directly to
fitandfit_transform.
Deprecated since version 1.8:
dissimilaritywas renamedmetricin 1.8 and will be removed in 1.10.- metricstr or callable, default=’euclidean’
Metric to use for dissimilarity computation. Default is “euclidean”.
If metric is a string, it must be one of the options allowed by
scipy.spatial.distance.pdistfor its metric parameter, or a metric listed insklearn.metrics.pairwise.distance_metricsIf metric is “precomputed”, X is assumed to be a distance matrix and must be square during fit.
If metric is a callable function, it takes two arrays representing 1D vectors as inputs and must return one value indicating the distance between those vectors. This works for Scipy’s metrics, but is less efficient than passing the metric name as a string.
Changed in version 1.8: Prior to 1.8,
metric=True/Falsewas used to select metric/non-metric MDS, which is now the role ofmetric_mds. The support forTrueandFalsewill be dropped in version 1.10, usemetric_mdsinstead.- metric_paramsdict, default=None
Additional keyword arguments for the dissimilarity computation.
Added in version 1.8.
- normalized_stressbool or “auto” default=”auto”
Whether to return normalized stress value (Stress-1) instead of raw stress. By default, metric MDS returns raw stress while non-metric MDS returns normalized stress.
Added in version 1.2.
Changed in version 1.4: The default value changed from
Falseto"auto"in version 1.4.Changed in version 1.7: Normalized stress is now supported for metric MDS as well.
- Attributes:
- embedding_ndarray of shape (n_samples, n_components)
Stores the position of the dataset in the embedding space.
- stress_float
The final value of the stress (sum of squared distance of the disparities and the distances for all constrained points). If
normalized_stress=True, returns Stress-1. A value of 0 indicates “perfect” fit, 0.025 excellent, 0.05 good, 0.1 fair, and 0.2 poor [1].- dissimilarity_matrix_ndarray of shape (n_samples, n_samples)
Pairwise dissimilarities between the points. Symmetric matrix that:
either uses a custom dissimilarity matrix by setting
dissimilarityto ‘precomputed’;or constructs a dissimilarity matrix from data using Euclidean distances.
- n_features_in_int
Number of features seen during fit.
Added in version 0.24.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Defined only when
Xhas feature names that are all strings.Added in version 1.0.
- n_iter_int
The number of iterations corresponding to the best stress.
See also
sklearn.decomposition.PCAPrincipal component analysis that is a linear dimensionality reduction method.
sklearn.decomposition.KernelPCANon-linear dimensionality reduction using kernels and PCA.
TSNET-distributed Stochastic Neighbor Embedding.
IsomapManifold learning based on Isometric Mapping.
LocallyLinearEmbeddingManifold learning using Locally Linear Embedding.
SpectralEmbeddingSpectral embedding for non-linear dimensionality.
References
[1]“Nonmetric multidimensional scaling: a numerical method” Kruskal, J. Psychometrika, 29 (1964)
[2]“Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis” Kruskal, J. Psychometrika, 29, (1964)
[3]“Modern Multidimensional Scaling - Theory and Applications” Borg, I.; Groenen P. Springer Series in Statistics (1997)
Examples
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import MDS >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = MDS(n_components=2, n_init=1, init="random") >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
For a more detailed example of usage, see Multi-dimensional scaling.
For a comparison of manifold learning techniques, see Comparison of Manifold Learning methods.
- fit(X, y=None, init=None)[source]#
Compute the position of the points in the embedding space.
- Parameters:
- Xarray-like of shape (n_samples, n_features) or (n_samples, n_samples)
Input data. If
metric=='precomputed', the input should be the dissimilarity matrix.- yIgnored
Not used, present for API consistency by convention.
- initndarray of shape (n_samples, n_components), default=None
Starting configuration of the embedding to initialize the SMACOF algorithm. By default, the algorithm is initialized with a randomly chosen array.
- Returns:
- selfobject
Fitted estimator.
- fit_transform(X, y=None, init=None)[source]#
Fit the data from
X, and returns the embedded coordinates.- Parameters:
- Xarray-like of shape (n_samples, n_features) or (n_samples, n_samples)
Input data. If
metric=='precomputed', the input should be the dissimilarity matrix.- yIgnored
Not used, present for API consistency by convention.
- initndarray of shape (n_samples, n_components), default=None
Starting configuration of the embedding to initialize the SMACOF algorithm. By default, the algorithm is initialized with a randomly chosen array.
- Returns:
- X_newndarray of shape (n_samples, n_components)
X transformed in the new space.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- set_fit_request(*, init: bool | None | str = '$UNCHANGED$') MDS[source]#
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- initstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
initparameter infit.
- Returns:
- selfobject
The updated object.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
Gallery examples#

Manifold learning on handwritten digits: Locally Linear Embedding, Isomap…