KBinsDiscretizer#
- class sklearn.preprocessing.KBinsDiscretizer(n_bins=5, *, encode='onehot', strategy='quantile', quantile_method='averaged_inverted_cdf', dtype=None, subsample=200000, random_state=None)[source]#
Bin continuous data into intervals.
Read more in the User Guide.
Added in version 0.20.
- Parameters:
- n_binsint or array-like of shape (n_features,), default=5
The number of bins to produce. Raises ValueError if
n_bins < 2.- encode{‘onehot’, ‘onehot-dense’, ‘ordinal’}, default=’onehot’
Method used to encode the transformed result.
‘onehot’: Encode the transformed result with one-hot encoding and return a sparse matrix. Ignored features are always stacked to the right.
‘onehot-dense’: Encode the transformed result with one-hot encoding and return a dense array. Ignored features are always stacked to the right.
‘ordinal’: Return the bin identifier encoded as an integer value.
- strategy{‘uniform’, ‘quantile’, ‘kmeans’}, default=’quantile’
Strategy used to define the widths of the bins.
‘uniform’: All bins in each feature have identical widths.
‘quantile’: All bins in each feature have the same number of points.
‘kmeans’: Values in each bin have the same nearest center of a 1D k-means cluster.
For an example of the different strategies see: Demonstrating the different strategies of KBinsDiscretizer.
- quantile_method{“inverted_cdf”, “averaged_inverted_cdf”,
“closest_observation”, “interpolated_inverted_cdf”, “hazen”, “weibull”, “linear”, “median_unbiased”, “normal_unbiased”}, default=”averaged_inverted_cdf” Method to pass on to np.percentile calculation when using strategy=”quantile”. Only
averaged_inverted_cdfandinverted_cdfsupport the use ofsample_weight != Nonewhen subsampling is not active.Added in version 1.7.
Changed in version 1.9: The default value changed from
"linear"to"averaged_inverted_cdf".- dtype{np.float32, np.float64}, default=None
The desired data-type for the output. If None, output dtype is consistent with input dtype. Only np.float32 and np.float64 are supported.
Added in version 0.24.
- subsampleint or None, default=200_000
Maximum number of samples, used to fit the model, for computational efficiency.
subsample=Nonemeans that all the training samples are used when computing the quantiles that determine the binning thresholds. Since quantile computation relies on sorting each column ofXand that sorting has ann log(n)time complexity, it is recommended to use subsampling on datasets with a very large number of samples.Changed in version 1.3: The default value of
subsamplechanged fromNoneto200_000whenstrategy="quantile".Changed in version 1.5: The default value of
subsamplechanged fromNoneto200_000whenstrategy="uniform"orstrategy="kmeans".- random_stateint, RandomState instance or None, default=None
Determines random number generation for subsampling. Pass an int for reproducible results across multiple function calls. See the
subsampleparameter for more details. See Glossary.Added in version 1.1.
- Attributes:
- bin_edges_ndarray of ndarray of shape (n_features,)
The edges of each bin. Contain arrays of varying shapes
(n_bins_, )Ignored features will have empty arrays.- n_bins_ndarray of shape (n_features,), dtype=np.int64
Number of bins per feature. Bins whose width are too small (i.e., <= 1e-8) are removed with a warning.
- n_features_in_int
Number of features seen during fit.
Added in version 0.24.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Defined only when
Xhas feature names that are all strings.Added in version 1.0.
See also
BinarizerClass used to bin values as
0or1based on a parameterthreshold.
Notes
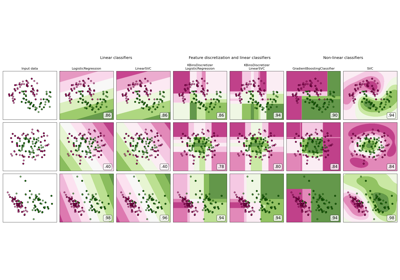
For a visualization of discretization on different datasets refer to Feature discretization. On the effect of discretization on linear models see: Using KBinsDiscretizer to discretize continuous features.
In bin edges for feature
i, the first and last values are used only forinverse_transform. During transform, bin edges are extended to:np.concatenate([-np.inf, bin_edges_[i][1:-1], np.inf])
You can combine
KBinsDiscretizerwithColumnTransformerif you only want to preprocess part of the features.KBinsDiscretizermight produce constant features (e.g., whenencode = 'onehot'and certain bins do not contain any data). These features can be removed with feature selection algorithms (e.g.,VarianceThreshold).Examples
>>> from sklearn.preprocessing import KBinsDiscretizer >>> X = [[-2, 1, -4, -1], ... [-1, 2, -3, -0.5], ... [ 0, 3, -2, 0.5], ... [ 1, 4, -1, 2]] >>> est = KBinsDiscretizer( ... n_bins=3, encode='ordinal', strategy='uniform' ... ) >>> est.fit(X) KBinsDiscretizer(...) >>> Xt = est.transform(X) >>> Xt array([[ 0., 0., 0., 0.], [ 1., 1., 1., 0.], [ 2., 2., 2., 1.], [ 2., 2., 2., 2.]])
Sometimes it may be useful to convert the data back into the original feature space. The
inverse_transformfunction converts the binned data into the original feature space. Each value will be equal to the mean of the two bin edges.>>> est.bin_edges_[0] array([-2., -1., 0., 1.]) >>> est.inverse_transform(Xt) array([[-1.5, 1.5, -3.5, -0.5], [-0.5, 2.5, -2.5, -0.5], [ 0.5, 3.5, -1.5, 0.5], [ 0.5, 3.5, -1.5, 1.5]])
While this preprocessing step can be an optimization, it is important to note the array returned by
inverse_transformwill have an internal type ofnp.float64ornp.float32, denoted by thedtypeinput argument. This can drastically increase the memory usage of the array. See the Vector Quantization Example whereKBinsDescretizeris used to cluster the image into bins and increases the size of the image by 8x.- fit(X, y=None, sample_weight=None)[source]#
Fit the estimator.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Data to be discretized.
- yNone
Ignored. This parameter exists only for compatibility with
Pipeline.- sample_weightndarray of shape (n_samples,)
Contains weight values to be associated with each sample.
Added in version 1.3.
Changed in version 1.7: Added support for strategy=”uniform”.
- Returns:
- selfobject
Returns the instance itself.
- fit_transform(X, y=None, **fit_params)[source]#
Fit to data, then transform it.
Fits transformer to
Xandywith optional parametersfit_paramsand returns a transformed version ofX.- Parameters:
- Xarray-like of shape (n_samples, n_features)
Input samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
Target values (None for unsupervised transformations).
- **fit_paramsdict
Additional fit parameters. Pass only if the estimator accepts additional params in its
fitmethod.
- Returns:
- X_newndarray array of shape (n_samples, n_features_new)
Transformed array.
- get_feature_names_out(input_features=None)[source]#
Get output feature names.
- Parameters:
- input_featuresarray-like of str or None, default=None
Input features.
If
input_featuresisNone, thenfeature_names_in_is used as feature names in. Iffeature_names_in_is not defined, then the following input feature names are generated:["x0", "x1", ..., "x(n_features_in_ - 1)"].If
input_featuresis an array-like, theninput_featuresmust matchfeature_names_in_iffeature_names_in_is defined.
- Returns:
- feature_names_outndarray of str objects
Transformed feature names.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- inverse_transform(X)[source]#
Transform discretized data back to original feature space.
Note that this function does not regenerate the original data due to discretization rounding.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Transformed data in the binned space.
- Returns:
- X_originalndarray, dtype={np.float32, np.float64}
Data in the original feature space.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KBinsDiscretizer[source]#
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
- Returns:
- selfobject
The updated object.
- set_output(*, transform=None)[source]#
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame output"polars": Polars outputNone: Transform configuration is unchanged
Added in version 1.4:
"polars"option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
Gallery examples#
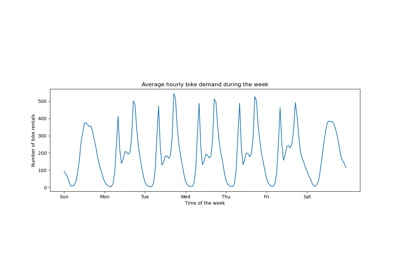
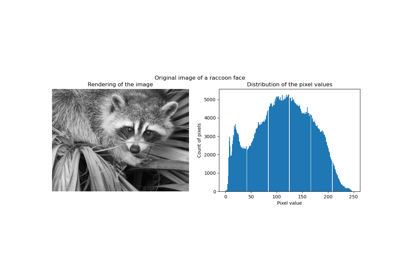
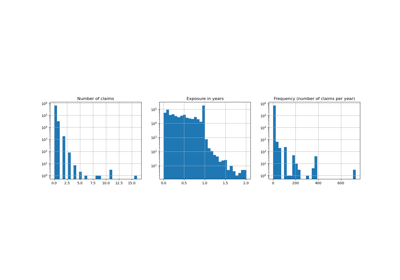
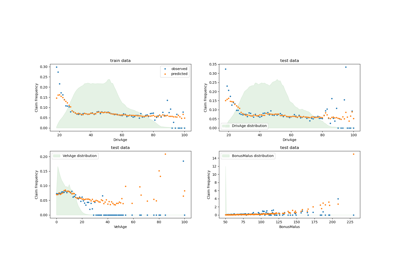
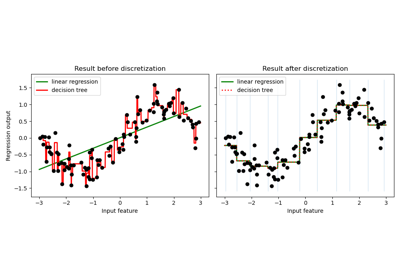
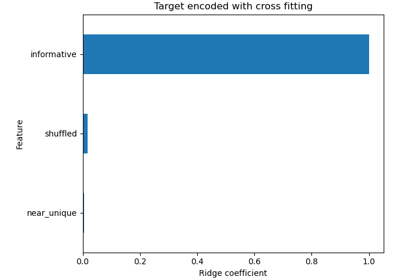
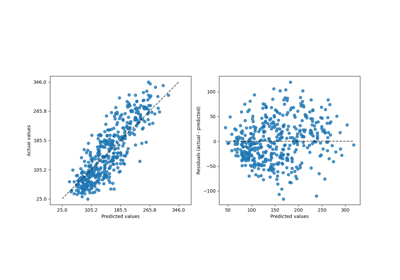
Using KBinsDiscretizer to discretize continuous features
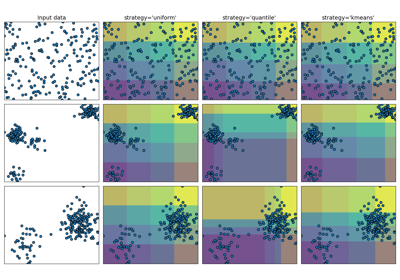
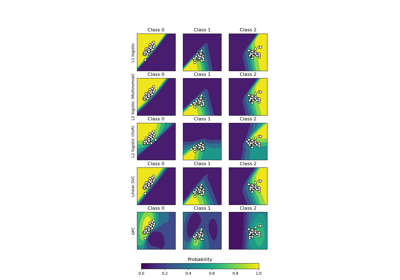
Demonstrating the different strategies of KBinsDiscretizer