
0.15.2¶
Bug fixes¶
- Fixed handling of the p parameter of the Minkowski distance that was previously ignored in nearest neighbors models. By Nikolay Mayorov.
- Fixed duplicated alphas in linear_model.LassoLars with early stopping on 32 bit Python. By Olivier Grisel and Fabian Pedregosa.
- Fixed the build under Windows when scikit-learn is built with MSVC while NumPy is built with MinGW. By Olivier Grisel and Federico Vaggi.
- Fixed an array index overflow bug in the coordinate descent solver. By Gael Varoquaux.
- Better handling of numpy 1.9 deprecation warnings. By Gael Varoquaux.
- Removed unnecessary data copy in cluster.KMeans. By Gael Varoquaux.
- Explicitly close open files to avoid ResourceWarnings under Python 3. By Calvin Giles.
- The transform of lda.LDA now projects the input on the most discriminant directions. By Martin Billinger.
- Fixed potential overflow in _tree.safe_realloc by Lars Buitinck.
- Performance optimization in istonic.IsotonicRegression. By Robert Bradshaw.
- nose is non-longer a runtime dependency to import sklearn, only for running the tests. By Joel Nothman.
- Many documentation and website fixes by Joel Nothman, Lars Buitinck and others.
0.15.1¶
Bug fixes¶
- Made cross_validation.cross_val_score use cross_validation.KFold instead of cross_validation.StratifiedKFold on multi-output classification problems. By Nikolay Mayorov.
- Support unseen labels preprocessing.LabelBinarizer to restore the default behavior of 0.14.1 for backward compatibility. By Hamzeh Alsalhi.
- Fixed the cluster.KMeans stopping criterion that prevented early convergence detection. By Edward Raff and Gael Varoquaux.
- Fixed the behavior of multiclass.OneVsOneClassifier. in case of ties at the per-class vote level by computing the correct per-class sum of prediction scores. By Andreas Müller.
- Made cross_validation.cross_val_score and grid_search.GridSearchCV accept Python lists as input data. This is especially useful for cross-validation and model selection of text processing pipelines. By Andreas Müller.
- Fixed data input checks of most estimators to accept input data that implements the NumPy __array__ protocol. This is the case for for pandas.Series and pandas.DataFrame in recent versions of pandas. By Gael Varoquaux.
- Fixed a regression for linear_model.SGDClassifier with class_weight="auto" on data with non-contiguous labels. By Olivier Grisel.
- Fix incomplete download of the dataset when datasets.download_20newsgroups is called. By Manoj Kumar.
- Various fixes to the Gaussian processes subpackage by Vincent Dubourg and Jan Hendrik Metzen.
- The transform of lda.LDA now projects the input on the most discriminant directions. By Martin Billinger.
- Nearest neighbors estimators now reliably work inside GridSearchCV, thanks to Nikolay Mayorov.
API changes summary¶
- Nearest neighbors estimators used to take arbitrary keyword arguments and pass these to their distance metric. This will no longer be supported in scikit-learn 0.18; use the metric_params argument instead.
0.15¶
Highlights¶
- Many speed and memory improvements all across the code
- Huge speed and memory improvements to random forests (and extra trees) that also benefit better from parallel computing.
- Incremental fit to BernoulliRBM
- Added cluster.AgglomerativeClustering for hierarchical agglomerative clustering with average linkage, complete linkage and ward strategies.
- Added linear_model.RANSACRegressor for robust regression models.
Changelog¶
New features¶
- Added ensemble.BaggingClassifier and ensemble.BaggingRegressor meta-estimators for ensembling any kind of base estimator. See the Bagging section of the user guide for details and examples. By Gilles Louppe.
- New unsupervised feature selection algorithm feature_selection.VarianceThreshold, by Lars Buitinck.
- Added linear_model.RANSACRegressor meta-estimator for the robust fitting of regression models. By Johannes Schönberger.
- Added cluster.AgglomerativeClustering for hierarchical agglomerative clustering with average linkage, complete linkage and ward strategies, by Nelle Varoquaux and Gael Varoquaux.
- Shorthand constructors pipeline.make_pipeline and pipeline.make_union were added by Lars Buitinck.
- Shuffle option for cross_validation.StratifiedKFold. By Jeffrey Blackburne.
- Incremental learning (partial_fit) for Gaussian Naive Bayes by Imran Haque.
- Added partial_fit to BernoulliRBM By Danny Sullivan.
- Added learning_curve utility to chart performance with respect to training size. See Plotting Learning Curves. By Alexander Fabisch.
- Add positive option in LassoCV and ElasticNetCV. By Brian Wignall and Alexandre Gramfort.
- Added linear_model.MultiTaskElasticNetCV and linear_model.MultiTaskLassoCV. By Manoj Kumar.
Enhancements¶
- Add sparse input support to ensemble.AdaBoostClassifier and ensemble.AdaBoostRegressor meta-estimators. By Hamzeh Alsalhi.
- Memory improvements of decision trees, by Arnaud Joly.
- Decision trees can now be built in best-first manner by using max_leaf_nodes as the stopping criteria. Refactored the tree code to use either a stack or a priority queue for tree building. By Peter Prettenhofer and Gilles Louppe.
- Decision trees can now be fitted on fortran- and c-style arrays, and non-continuous arrays without the need to make a copy. If the input array has a different dtype than np.float32, a fortran- style copy will be made since fortran-style memory layout has speed advantages. By Peter Prettenhofer and Gilles Louppe.
- Speed improvement of regression trees by optimizing the the computation of the mean square error criterion. This lead to speed improvement of the tree, forest and gradient boosting tree modules. By Arnaud Joly
- The img_to_graph and grid_tograph functions in sklearn.feature_extraction.image now return np.ndarray instead of np.matrix when return_as=np.ndarray. See the Notes section for more information on compatibility.
- Changed the internal storage of decision trees to use a struct array. This fixed some small bugs, while improving code and providing a small speed gain. By Joel Nothman.
- Reduce memory usage and overhead when fitting and predicting with forests of randomized trees in parallel with n_jobs != 1 by leveraging new threading backend of joblib 0.8 and releasing the GIL in the tree fitting Cython code. By Olivier Grisel and Gilles Louppe.
- Speed improvement of the sklearn.ensemble.gradient_boosting module. By Gilles Louppe and Peter Prettenhofer.
- Various enhancements to the sklearn.ensemble.gradient_boosting module: a warm_start argument to fit additional trees, a max_leaf_nodes argument to fit GBM style trees, a monitor fit argument to inspect the estimator during training, and refactoring of the verbose code. By Peter Prettenhofer.
- Faster sklearn.ensemble.ExtraTrees by caching feature values. By Arnaud Joly.
- Faster depth-based tree building algorithm such as decision tree, random forest, extra trees or gradient tree boosting (with depth based growing strategy) by avoiding trying to split on found constant features in the sample subset. By Arnaud Joly.
- Add min_weight_fraction_leaf pre-pruning parameter to tree-based methods: the minimum weighted fraction of the input samples required to be at a leaf node. By Noel Dawe.
- Added metrics.pairwise_distances_argmin_min, by Philippe Gervais.
- Added predict method to cluster.AffinityPropagation and cluster.MeanShift, by Mathieu Blondel.
- Vector and matrix multiplications have been optimised throughout the library by Denis Engemann, and Alexandre Gramfort. In particular, they should take less memory with older NumPy versions (prior to 1.7.2).
- Precision-recall and ROC examples now use train_test_split, and have more explanation of why these metrics are useful. By Kyle Kastner
- The training algorithm for decomposition.NMF is faster for sparse matrices and has much lower memory complexity, meaning it will scale up gracefully to large datasets. By Lars Buitinck.
- Added svd_method option with default value to “randomized” to decomposition.FactorAnalysis to save memory and significantly speedup computation by Denis Engemann, and Alexandre Gramfort.
- Changed cross_validation.StratifiedKFold to try and preserve as much of the original ordering of samples as possible so as not to hide overfitting on datasets with a non-negligible level of samples dependency. By Daniel Nouri and Olivier Grisel.
- Add multi-output support to gaussian_process.GaussianProcess by John Novak.
- Norm computations optimized for NumPy 1.6 and later versions by Lars Buitinck. In particular, the k-means algorithm no longer needs a temporary data structure the size of its input.
- dummy.DummyClassifier can now be used to predict a constant output value. By Manoj Kumar.
- dummy.DummyRegressor has now a strategy parameter which allows to predict the mean, the median of the training set or a constant output value. By Maheshakya Wijewardena.
- Multi-label classification output in multilabel indicator format is now supported by metrics.roc_auc_score and metrics.average_precision_score by Arnaud Joly.
- Significant performance improvements (more than 100x speedup for large problems) in isotonic.IsotonicRegression by Andrew Tulloch.
- Speed and memory usage improvements to the SGD algorithm for linear models: it now uses threads, not separate processes, when n_jobs>1. By Lars Buitinck.
- Grid search and cross validation allow NaNs in the input arrays so that preprocessors such as preprocessing.Imputer can be trained within the cross validation loop, avoiding potentially skewed results.
- Ridge regression can now deal with sample weights in feature space (only sample space until then). By Michael Eickenberg. Both solutions are provided by the Cholesky solver.
- Several classification and regression metrics now support weighted samples with the new sample_weight argument: metrics.accuracy_score, metrics.zero_one_loss, metrics.precision_score, metrics.average_precision_score, metrics.f1_score, metrics.fbeta_score, metrics.recall_score, metrics.roc_auc_score, metrics.explained_variance_score, metrics.mean_squared_error, metrics.mean_absolute_error, metrics.r2_score. By Noel Dawe.
- Speed up of the sample generator datasets.make_multilabel_classification. By Joel Nothman.
Documentation improvements¶
- The Working With Text Data tutorial has now been worked in to the main documentation’s tutorial section. Includes exercises and skeletons for tutorial presentation. Original tutorial created by several authors including Olivier Grisel, Lars Buitinck and many others. Tutorial integration into the scikit-learn documentation by Jaques Grobler
- Added Computational Performance documentation. Discussion and examples of prediction latency / throughput and different factors that have influence over speed. Additional tips for building faster models and choosing a relevant compromise between speed and predictive power. By Eustache Diemert.
Bug fixes¶
- Fixed bug in decomposition.MiniBatchDictionaryLearning : partial_fit was not working properly.
- Fixed bug in linear_model.stochastic_gradient : l1_ratio was used as (1.0 - l1_ratio) .
- Fixed bug in multiclass.OneVsOneClassifier with string labels
- Fixed a bug in LassoCV and ElasticNetCV: they would not pre-compute the Gram matrix with precompute=True or precompute="auto" and n_samples > n_features. By Manoj Kumar.
- Fixed incorrect estimation of the degrees of freedom in feature_selection.f_regression when variates are not centered. By Virgile Fritsch.
- Fixed a race condition in parallel processing with pre_dispatch != "all" (for instance in cross_val_score). By Olivier Grisel.
- Raise error in cluster.FeatureAgglomeration and cluster.WardAgglomeration when no samples are given, rather than returning meaningless clustering.
- Fixed bug in gradient_boosting.GradientBoostingRegressor with loss='huber': gamma might have not been initialized.
- Fixed feature importances as computed with a forest of randomized trees when fit with sample_weight != None and/or with bootstrap=True. By Gilles Louppe.
API changes summary¶
- sklearn.hmm is deprecated. Its removal is planned for the 0.17 release.
- Use of covariance.EllipticEnvelop has now been removed after deprecation. Please use covariance.EllipticEnvelope instead.
- cluster.Ward is deprecated. Use cluster.AgglomerativeClustering instead.
- cluster.WardClustering is deprecated. Use
- cluster.AgglomerativeClustering instead.
- cross_validation.Bootstrap is deprecated. cross_validation.KFold or cross_validation.ShuffleSplit are recommended instead.
- Direct support for the sequence of sequences (or list of lists) multilabel format is deprecated. To convert to and from the supported binary indicator matrix format, use MultiLabelBinarizer. By Joel Nothman.
- Add score method to PCA following the model of probabilistic PCA and deprecate ProbabilisticPCA model whose score implementation is not correct. The computation now also exploits the matrix inversion lemma for faster computation. By Alexandre Gramfort.
- The score method of FactorAnalysis now returns the average log-likelihood of the samples. Use score_samples to get log-likelihood of each sample. By Alexandre Gramfort.
- Generating boolean masks (the setting indices=False) from cross-validation generators is deprecated. Support for masks will be removed in 0.17. The generators have produced arrays of indices by default since 0.10. By Joel Nothman.
- 1-d arrays containing strings with dtype=object (as used in Pandas) are now considered valid classification targets. This fixes a regression from version 0.13 in some classifiers. By Joel Nothman.
- Fix wrong explained_variance_ratio_ attribute in RandomizedPCA. By Alexandre Gramfort.
- Fit alphas for each l1_ratio instead of mean_l1_ratio in linear_model.ElasticNetCV and linear_model.LassoCV. This changes the shape of alphas_ from (n_alphas,) to (n_l1_ratio, n_alphas) if the l1_ratio provided is a 1-D array like object of length greater than one. By Manoj Kumar.
- Fix linear_model.ElasticNetCV and linear_model.LassoCV when fitting intercept and input data is sparse. The automatic grid of alphas was not computed correctly and the scaling with normalize was wrong. By Manoj Kumar.
- Fix wrong maximal number of features drawn (max_features) at each split for decision trees, random forests and gradient tree boosting. Previously, the count for the number of drawn features started only after one non constant features in the split. This bug fix will affect computational and generalization performance of those algorithms in the presence of constant features. To get back previous generalization performance, you should modify the value of max_features. By Arnaud Joly.
- Fix wrong maximal number of features drawn (max_features) at each split for ensemble.ExtraTreesClassifier and ensemble.ExtraTreesRegressor. Previously, only non constant features in the split was counted as drawn. Now constant features are counted as drawn. Furthermore at least one feature must be non constant in order to make a valid split. This bug fix will affect computational and generalization performance of extra trees in the presence of constant features. To get back previous generalization performance, you should modify the value of max_features. By Arnaud Joly.
- Fix utils.compute_class_weight when class_weight=="auto". Previously it was broken for input of non-integer dtype and the weighted array that was returned was wrong. By Manoj Kumar.
- Fix cross_validation.Bootstrap to return ValueError when n_train + n_test > n. By Ronald Phlypo.
People¶
List of contributors for release 0.15 by number of commits.
- 312 Olivier Grisel
- 275 Lars Buitinck
- 221 Gael Varoquaux
- 148 Arnaud Joly
- 134 Johannes Schönberger
- 119 Gilles Louppe
- 113 Joel Nothman
- 111 Alexandre Gramfort
- 95 Jaques Grobler
- 89 Denis Engemann
- 83 Peter Prettenhofer
- 83 Alexander Fabisch
- 62 Mathieu Blondel
- 60 Eustache Diemert
- 60 Nelle Varoquaux
- 49 Michael Bommarito
- 45 Manoj-Kumar-S
- 28 Kyle Kastner
- 26 Andreas Mueller
- 22 Noel Dawe
- 21 Maheshakya Wijewardena
- 21 Brooke Osborn
- 21 Hamzeh Alsalhi
- 21 Jake VanderPlas
- 21 Philippe Gervais
- 19 Bala Subrahmanyam Varanasi
- 12 Ronald Phlypo
- 10 Mikhail Korobov
- 8 Thomas Unterthiner
- 8 Jeffrey Blackburne
- 8 eltermann
- 8 bwignall
- 7 Ankit Agrawal
- 7 CJ Carey
- 6 Daniel Nouri
- 6 Chen Liu
- 6 Michael Eickenberg
- 6 ugurthemaster
- 5 Aaron Schumacher
- 5 Baptiste Lagarde
- 5 Rajat Khanduja
- 5 Robert McGibbon
- 5 Sergio Pascual
- 4 Alexis Metaireau
- 4 Ignacio Rossi
- 4 Virgile Fritsch
- 4 Sebastian Saeger
- 4 Ilambharathi Kanniah
- 4 sdenton4
- 4 Robert Layton
- 4 Alyssa
- 4 Amos Waterland
- 3 Andrew Tulloch
- 3 murad
- 3 Steven Maude
- 3 Karol Pysniak
- 3 Jacques Kvam
- 3 cgohlke
- 3 cjlin
- 3 Michael Becker
- 3 hamzeh
- 3 Eric Jacobsen
- 3 john collins
- 3 kaushik94
- 3 Erwin Marsi
- 2 csytracy
- 2 LK
- 2 Vlad Niculae
- 2 Laurent Direr
- 2 Erik Shilts
- 2 Raul Garreta
- 2 Yoshiki Vázquez Baeza
- 2 Yung Siang Liau
- 2 abhishek thakur
- 2 James Yu
- 2 Rohit Sivaprasad
- 2 Roland Szabo
- 2 amormachine
- 2 Alexis Mignon
- 2 Oscar Carlsson
- 2 Nantas Nardelli
- 2 jess010
- 2 kowalski87
- 2 Andrew Clegg
- 2 Federico Vaggi
- 2 Simon Frid
- 2 Félix-Antoine Fortin
- 1 Ralf Gommers
- 1 t-aft
- 1 Ronan Amicel
- 1 Rupesh Kumar Srivastava
- 1 Ryan Wang
- 1 Samuel Charron
- 1 Samuel St-Jean
- 1 Fabian Pedregosa
- 1 Skipper Seabold
- 1 Stefan Walk
- 1 Stefan van der Walt
- 1 Stephan Hoyer
- 1 Allen Riddell
- 1 Valentin Haenel
- 1 Vijay Ramesh
- 1 Will Myers
- 1 Yaroslav Halchenko
- 1 Yoni Ben-Meshulam
- 1 Yury V. Zaytsev
- 1 adrinjalali
- 1 ai8rahim
- 1 alemagnani
- 1 alex
- 1 benjamin wilson
- 1 chalmerlowe
- 1 dzikie drożdże
- 1 jamestwebber
- 1 matrixorz
- 1 popo
- 1 samuela
- 1 François Boulogne
- 1 Alexander Measure
- 1 Ethan White
- 1 Guilherme Trein
- 1 Hendrik Heuer
- 1 IvicaJovic
- 1 Jan Hendrik Metzen
- 1 Jean Michel Rouly
- 1 Eduardo Ariño de la Rubia
- 1 Jelle Zijlstra
- 1 Eddy L O Jansson
- 1 Denis
- 1 John
- 1 John Schmidt
- 1 Jorge Cañardo Alastuey
- 1 Joseph Perla
- 1 Joshua Vredevoogd
- 1 José Ricardo
- 1 Julien Miotte
- 1 Kemal Eren
- 1 Kenta Sato
- 1 David Cournapeau
- 1 Kyle Kelley
- 1 Daniele Medri
- 1 Laurent Luce
- 1 Laurent Pierron
- 1 Luis Pedro Coelho
- 1 DanielWeitzenfeld
- 1 Craig Thompson
- 1 Chyi-Kwei Yau
- 1 Matthew Brett
- 1 Matthias Feurer
- 1 Max Linke
- 1 Chris Filo Gorgolewski
- 1 Charles Earl
- 1 Michael Hanke
- 1 Michele Orrù
- 1 Bryan Lunt
- 1 Brian Kearns
- 1 Paul Butler
- 1 Paweł Mandera
- 1 Peter
- 1 Andrew Ash
- 1 Pietro Zambelli
- 1 staubda
0.14¶
Changelog¶
- Missing values with sparse and dense matrices can be imputed with the transformer preprocessing.Imputer by Nicolas Trésegnie.
- The core implementation of decisions trees has been rewritten from scratch, allowing for faster tree induction and lower memory consumption in all tree-based estimators. By Gilles Louppe.
- Added ensemble.AdaBoostClassifier and ensemble.AdaBoostRegressor, by Noel Dawe and Gilles Louppe. See the AdaBoost section of the user guide for details and examples.
- Added grid_search.RandomizedSearchCV and grid_search.ParameterSampler for randomized hyperparameter optimization. By Andreas Müller.
- Added biclustering algorithms (sklearn.cluster.bicluster.SpectralCoclustering and sklearn.cluster.bicluster.SpectralBiclustering), data generation methods (sklearn.datasets.make_biclusters and sklearn.datasets.make_checkerboard), and scoring metrics (sklearn.metrics.consensus_score). By Kemal Eren.
- Added Restricted Boltzmann Machines (neural_network.BernoulliRBM). By Yann Dauphin.
- Python 3 support by Justin Vincent, Lars Buitinck, Subhodeep Moitra and Olivier Grisel. All tests now pass under Python 3.3.
- Ability to pass one penalty (alpha value) per target in linear_model.Ridge, by @eickenberg and Mathieu Blondel.
- Fixed sklearn.linear_model.stochastic_gradient.py L2 regularization issue (minor practical significance). By Norbert Crombach and Mathieu Blondel .
- Added an interactive version of Andreas Müller‘s Machine Learning Cheat Sheet (for scikit-learn) to the documentation. See Choosing the right estimator. By Jaques Grobler.
- grid_search.GridSearchCV and cross_validation.cross_val_score now support the use of advanced scoring function such as area under the ROC curve and f-beta scores. See The scoring parameter: defining model evaluation rules for details. By Andreas Müller and Lars Buitinck. Passing a function from sklearn.metrics as score_func is deprecated.
- Multi-label classification output is now supported by metrics.accuracy_score, metrics.zero_one_loss, metrics.f1_score, metrics.fbeta_score, metrics.classification_report, metrics.precision_score and metrics.recall_score by Arnaud Joly.
- Two new metrics metrics.hamming_loss and metrics.jaccard_similarity_score are added with multi-label support by Arnaud Joly.
- Speed and memory usage improvements in feature_extraction.text.CountVectorizer and feature_extraction.text.TfidfVectorizer, by Jochen Wersdörfer and Roman Sinayev.
- The min_df parameter in feature_extraction.text.CountVectorizer and feature_extraction.text.TfidfVectorizer, which used to be 2, has been reset to 1 to avoid unpleasant surprises (empty vocabularies) for novice users who try it out on tiny document collections. A value of at least 2 is still recommended for practical use.
- svm.LinearSVC, linear_model.SGDClassifier and linear_model.SGDRegressor now have a sparsify method that converts their coef_ into a sparse matrix, meaning stored models trained using these estimators can be made much more compact.
- linear_model.SGDClassifier now produces multiclass probability estimates when trained under log loss or modified Huber loss.
- Hyperlinks to documentation in example code on the website by Martin Luessi.
- Fixed bug in preprocessing.MinMaxScaler causing incorrect scaling of the features for non-default feature_range settings. By Andreas Müller.
- max_features in tree.DecisionTreeClassifier, tree.DecisionTreeRegressor and all derived ensemble estimators now supports percentage values. By Gilles Louppe.
- Performance improvements in isotonic.IsotonicRegression by Nelle Varoquaux.
- metrics.accuracy_score has an option normalize to return the fraction or the number of correctly classified sample by Arnaud Joly.
- Added metrics.log_loss that computes log loss, aka cross-entropy loss. By Jochen Wersdörfer and Lars Buitinck.
- A bug that caused ensemble.AdaBoostClassifier‘s to output incorrect probabilities has been fixed.
- Feature selectors now share a mixin providing consistent transform, inverse_transform and get_support methods. By Joel Nothman.
- A fitted grid_search.GridSearchCV or grid_search.RandomizedSearchCV can now generally be pickled. By Joel Nothman.
- Refactored and vectorized implementation of metrics.roc_curve and metrics.precision_recall_curve. By Joel Nothman.
- The new estimator sklearn.decomposition.TruncatedSVD performs dimensionality reduction using SVD on sparse matrices, and can be used for latent semantic analysis (LSA). By Lars Buitinck.
- Added self-contained example of out-of-core learning on text data Out-of-core classification of text documents. By Eustache Diemert.
- The default number of components for sklearn.decomposition.RandomizedPCA is now correctly documented to be n_features. This was the default behavior, so programs using it will continue to work as they did.
- sklearn.cluster.KMeans now fits several orders of magnitude faster on sparse data (the speedup depends on the sparsity). By Lars Buitinck.
- Reduce memory footprint of FastICA by Denis Engemann and Alexandre Gramfort.
- Verbose output in sklearn.ensemble.gradient_boosting now uses a column format and prints progress in decreasing frequency. It also shows the remaining time. By Peter Prettenhofer.
- sklearn.ensemble.gradient_boosting provides out-of-bag improvement oob_improvement_ rather than the OOB score for model selection. An example that shows how to use OOB estimates to select the number of trees was added. By Peter Prettenhofer.
- Most metrics now support string labels for multiclass classification by Arnaud Joly and Lars Buitinck.
- New OrthogonalMatchingPursuitCV class by Alexandre Gramfort and Vlad Niculae.
- Fixed a bug in sklearn.covariance.GraphLassoCV: the ‘alphas’ parameter now works as expected when given a list of values. By Philippe Gervais.
- Fixed an important bug in sklearn.covariance.GraphLassoCV that prevented all folds provided by a CV object to be used (only the first 3 were used). When providing a CV object, execution time may thus increase significantly compared to the previous version (bug results are correct now). By Philippe Gervais.
- cross_validation.cross_val_score and the grid_search module is now tested with multi-output data by Arnaud Joly.
- datasets.make_multilabel_classification can now return the output in label indicator multilabel format by Arnaud Joly.
- K-nearest neighbors, neighbors.KNeighborsRegressor and neighbors.RadiusNeighborsRegressor, and radius neighbors, neighbors.RadiusNeighborsRegressor and neighbors.RadiusNeighborsClassifier support multioutput data by Arnaud Joly.
- Random state in LibSVM-based estimators (svm.SVC, NuSVC, OneClassSVM, svm.SVR, svm.NuSVR) can now be controlled. This is useful to ensure consistency in the probability estimates for the classifiers trained with probability=True. By Vlad Niculae.
- Out-of-core learning support for discrete naive Bayes classifiers sklearn.naive_bayes.MultinomialNB and sklearn.naive_bayes.BernoulliNB by adding the partial_fit method by Olivier Grisel.
- New website design and navigation by Gilles Louppe, Nelle Varoquaux, Vincent Michel and Andreas Müller.
- Improved documentation on multi-class, multi-label and multi-output classification by Yannick Schwartz and Arnaud Joly.
- Better input and error handling in the metrics module by Arnaud Joly and Joel Nothman.
- Speed optimization of the hmm module by Mikhail Korobov
- Significant speed improvements for sklearn.cluster.DBSCAN by cleverless
API changes summary¶
- The auc_score was renamed roc_auc_score.
- Testing scikit-learn with sklearn.test() is deprecated. Use nosetests sklearn from the command line.
- Feature importances in tree.DecisionTreeClassifier, tree.DecisionTreeRegressor and all derived ensemble estimators are now computed on the fly when accessing the feature_importances_ attribute. Setting compute_importances=True is no longer required. By Gilles Louppe.
- linear_model.lasso_path and linear_model.enet_path can return its results in the same format as that of linear_model.lars_path. This is done by setting the return_models parameter to False. By Jaques Grobler and Alexandre Gramfort
- grid_search.IterGrid was renamed to grid_search.ParameterGrid.
- Fixed bug in KFold causing imperfect class balance in some cases. By Alexandre Gramfort and Tadej Janež.
- sklearn.neighbors.BallTree has been refactored, and a sklearn.neighbors.KDTree has been added which shares the same interface. The Ball Tree now works with a wide variety of distance metrics. Both classes have many new methods, including single-tree and dual-tree queries, breadth-first and depth-first searching, and more advanced queries such as kernel density estimation and 2-point correlation functions. By Jake Vanderplas
- Support for scipy.spatial.cKDTree within neighbors queries has been removed, and the functionality replaced with the new KDTree class.
- sklearn.neighbors.KernelDensity has been added, which performs efficient kernel density estimation with a variety of kernels.
- sklearn.decomposition.KernelPCA now always returns output with n_components components, unless the new parameter remove_zero_eig is set to True. This new behavior is consistent with the way kernel PCA was always documented; previously, the removal of components with zero eigenvalues was tacitly performed on all data.
- gcv_mode="auto" no longer tries to perform SVD on a densified sparse matrix in sklearn.linear_model.RidgeCV.
- Sparse matrix support in sklearn.decomposition.RandomizedPCA is now deprecated in favor of the new TruncatedSVD.
- cross_validation.KFold and cross_validation.StratifiedKFold now enforce n_folds >= 2 otherwise a ValueError is raised. By Olivier Grisel.
- datasets.load_files‘s charset and charset_errors parameters were renamed encoding and decode_errors.
- Attribute oob_score_ in sklearn.ensemble.GradientBoostingRegressor and sklearn.ensemble.GradientBoostingClassifier is deprecated and has been replaced by oob_improvement_ .
- Attributes in OrthogonalMatchingPursuit have been deprecated (copy_X, Gram, ...) and precompute_gram renamed precompute for consistency. See #2224.
- sklearn.preprocessing.StandardScaler now converts integer input to float, and raises a warning. Previously it rounded for dense integer input.
- sklearn.multiclass.OneVsRestClassifier now has a decision_function method. This will return the distance of each sample from the decision boundary for each class, as long as the underlying estimators implement the decision_function method. By Kyle Kastner.
- Better input validation, warning on unexpected shapes for y.
People¶
List of contributors for release 0.14 by number of commits.
- 277 Gilles Louppe
- 245 Lars Buitinck
- 187 Andreas Mueller
- 124 Arnaud Joly
- 112 Jaques Grobler
- 109 Gael Varoquaux
- 107 Olivier Grisel
- 102 Noel Dawe
- 99 Kemal Eren
- 79 Joel Nothman
- 75 Jake VanderPlas
- 73 Nelle Varoquaux
- 71 Vlad Niculae
- 65 Peter Prettenhofer
- 64 Alexandre Gramfort
- 54 Mathieu Blondel
- 38 Nicolas Trésegnie
- 35 eustache
- 27 Denis Engemann
- 25 Yann N. Dauphin
- 19 Justin Vincent
- 17 Robert Layton
- 15 Doug Coleman
- 14 Michael Eickenberg
- 13 Robert Marchman
- 11 Fabian Pedregosa
- 11 Philippe Gervais
- 10 Jim Holmström
- 10 Tadej Janež
- 10 syhw
- 9 Mikhail Korobov
- 9 Steven De Gryze
- 8 sergeyf
- 7 Ben Root
- 7 Hrishikesh Huilgolkar
- 6 Kyle Kastner
- 6 Martin Luessi
- 6 Rob Speer
- 5 Federico Vaggi
- 5 Raul Garreta
- 5 Rob Zinkov
- 4 Ken Geis
- 3 A. Flaxman
- 3 Denton Cockburn
- 3 Dougal Sutherland
- 3 Ian Ozsvald
- 3 Johannes Schönberger
- 3 Robert McGibbon
- 3 Roman Sinayev
- 3 Szabo Roland
- 2 Diego Molla
- 2 Imran Haque
- 2 Jochen Wersdörfer
- 2 Sergey Karayev
- 2 Yannick Schwartz
- 2 jamestwebber
- 1 Abhijeet Kolhe
- 1 Alexander Fabisch
- 1 Bastiaan van den Berg
- 1 Benjamin Peterson
- 1 Daniel Velkov
- 1 Fazlul Shahriar
- 1 Felix Brockherde
- 1 Félix-Antoine Fortin
- 1 Harikrishnan S
- 1 Jack Hale
- 1 JakeMick
- 1 James McDermott
- 1 John Benediktsson
- 1 John Zwinck
- 1 Joshua Vredevoogd
- 1 Justin Pati
- 1 Kevin Hughes
- 1 Kyle Kelley
- 1 Matthias Ekman
- 1 Miroslav Shubernetskiy
- 1 Naoki Orii
- 1 Norbert Crombach
- 1 Rafael Cunha de Almeida
- 1 Rolando Espinoza La fuente
- 1 Seamus Abshere
- 1 Sergey Feldman
- 1 Sergio Medina
- 1 Stefano Lattarini
- 1 Steve Koch
- 1 Sturla Molden
- 1 Thomas Jarosch
- 1 Yaroslav Halchenko
0.13.1¶
The 0.13.1 release only fixes some bugs and does not add any new functionality.
Changelog¶
- Fixed a testing error caused by the function cross_validation.train_test_split being interpreted as a test by Yaroslav Halchenko.
- Fixed a bug in the reassignment of small clusters in the cluster.MiniBatchKMeans by Gael Varoquaux.
- Fixed default value of gamma in decomposition.KernelPCA by Lars Buitinck.
- Updated joblib to 0.7.0d by Gael Varoquaux.
- Fixed scaling of the deviance in ensemble.GradientBoostingClassifier by Peter Prettenhofer.
- Better tie-breaking in multiclass.OneVsOneClassifier by Andreas Müller.
- Other small improvements to tests and documentation.
People¶
- List of contributors for release 0.13.1 by number of commits.
- 16 Lars Buitinck
- 12 Andreas Müller
- 8 Gael Varoquaux
- 5 Robert Marchman
- 3 Peter Prettenhofer
- 2 Hrishikesh Huilgolkar
- 1 Bastiaan van den Berg
- 1 Diego Molla
- 1 Gilles Louppe
- 1 Mathieu Blondel
- 1 Nelle Varoquaux
- 1 Rafael Cunha de Almeida
- 1 Rolando Espinoza La fuente
- 1 Vlad Niculae
- 1 Yaroslav Halchenko
0.13¶
New Estimator Classes¶
- dummy.DummyClassifier and dummy.DummyRegressor, two data-independent predictors by Mathieu Blondel. Useful to sanity-check your estimators. See Dummy estimators in the user guide. Multioutput support added by Arnaud Joly.
- decomposition.FactorAnalysis, a transformer implementing the classical factor analysis, by Christian Osendorfer and Alexandre Gramfort. See Factor Analysis in the user guide.
- feature_extraction.FeatureHasher, a transformer implementing the “hashing trick” for fast, low-memory feature extraction from string fields by Lars Buitinck and feature_extraction.text.HashingVectorizer for text documents by Olivier Grisel See Feature hashing and Vectorizing a large text corpus with the hashing trick for the documentation and sample usage.
- pipeline.FeatureUnion, a transformer that concatenates results of several other transformers by Andreas Müller. See FeatureUnion: Combining feature extractors in the user guide.
- random_projection.GaussianRandomProjection, random_projection.SparseRandomProjection and the function random_projection.johnson_lindenstrauss_min_dim. The first two are transformers implementing Gaussian and sparse random projection matrix by Olivier Grisel and Arnaud Joly. See Random Projection in the user guide.
- kernel_approximation.Nystroem, a transformer for approximating arbitrary kernels by Andreas Müller. See Nystroem Method for Kernel Approximation in the user guide.
- preprocessing.OneHotEncoder, a transformer that computes binary encodings of categorical features by Andreas Müller. See Encoding categorical features in the user guide.
- linear_model.PassiveAggressiveClassifier and linear_model.PassiveAggressiveRegressor, predictors implementing an efficient stochastic optimization for linear models by Rob Zinkov and Mathieu Blondel. See Passive Aggressive Algorithms in the user guide.
- ensemble.RandomTreesEmbedding, a transformer for creating high-dimensional sparse representations using ensembles of totally random trees by Andreas Müller. See Totally Random Trees Embedding in the user guide.
- manifold.SpectralEmbedding and function manifold.spectral_embedding, implementing the “laplacian eigenmaps” transformation for non-linear dimensionality reduction by Wei Li. See Spectral Embedding in the user guide.
- isotonic.IsotonicRegression by Fabian Pedregosa, Alexandre Gramfort and Nelle Varoquaux,
Changelog¶
- metrics.zero_one_loss (formerly metrics.zero_one) now has option for normalized output that reports the fraction of misclassifications, rather than the raw number of misclassifications. By Kyle Beauchamp.
- tree.DecisionTreeClassifier and all derived ensemble models now support sample weighting, by Noel Dawe and Gilles Louppe.
- Speedup improvement when using bootstrap samples in forests of randomized trees, by Peter Prettenhofer and Gilles Louppe.
- Partial dependence plots for Gradient Tree Boosting in ensemble.partial_dependence.partial_dependence by Peter Prettenhofer. See Partial Dependence Plots for an example.
- The table of contents on the website has now been made expandable by Jaques Grobler.
- feature_selection.SelectPercentile now breaks ties deterministically instead of returning all equally ranked features.
- feature_selection.SelectKBest and feature_selection.SelectPercentile are more numerically stable since they use scores, rather than p-values, to rank results. This means that they might sometimes select different features than they did previously.
- Ridge regression and ridge classification fitting with sparse_cg solver no longer has quadratic memory complexity, by Lars Buitinck and Fabian Pedregosa.
- Ridge regression and ridge classification now support a new fast solver called lsqr, by Mathieu Blondel.
- Speed up of metrics.precision_recall_curve by Conrad Lee.
- Added support for reading/writing svmlight files with pairwise preference attribute (qid in svmlight file format) in datasets.dump_svmlight_file and datasets.load_svmlight_file by Fabian Pedregosa.
- Faster and more robust metrics.confusion_matrix and Clustering performance evaluation by Wei Li.
- cross_validation.cross_val_score now works with precomputed kernels and affinity matrices, by Andreas Müller.
- LARS algorithm made more numerically stable with heuristics to drop regressors too correlated as well as to stop the path when numerical noise becomes predominant, by Gael Varoquaux.
- Faster implementation of metrics.precision_recall_curve by Conrad Lee.
- New kernel metrics.chi2_kernel by Andreas Müller, often used in computer vision applications.
- Fix of longstanding bug in naive_bayes.BernoulliNB fixed by Shaun Jackman.
- Implemented predict_proba in multiclass.OneVsRestClassifier, by Andrew Winterman.
- Improve consistency in gradient boosting: estimators ensemble.GradientBoostingRegressor and ensemble.GradientBoostingClassifier use the estimator tree.DecisionTreeRegressor instead of the tree._tree.Tree data structure by Arnaud Joly.
- Fixed a floating point exception in the decision trees module, by Seberg.
- Fix metrics.roc_curve fails when y_true has only one class by Wei Li.
- Add the metrics.mean_absolute_error function which computes the mean absolute error. The metrics.mean_squared_error, metrics.mean_absolute_error and metrics.r2_score metrics support multioutput by Arnaud Joly.
- Fixed class_weight support in svm.LinearSVC and linear_model.LogisticRegression by Andreas Müller. The meaning of class_weight was reversed as erroneously higher weight meant less positives of a given class in earlier releases.
- Improve narrative documentation and consistency in sklearn.metrics for regression and classification metrics by Arnaud Joly.
- Fixed a bug in sklearn.svm.SVC when using csr-matrices with unsorted indices by Xinfan Meng and Andreas Müller.
- MiniBatchKMeans: Add random reassignment of cluster centers with little observations attached to them, by Gael Varoquaux.
API changes summary¶
- Renamed all occurrences of n_atoms to n_components for consistency. This applies to decomposition.DictionaryLearning, decomposition.MiniBatchDictionaryLearning, decomposition.dict_learning, decomposition.dict_learning_online.
- Renamed all occurrences of max_iters to max_iter for consistency. This applies to semi_supervised.LabelPropagation and semi_supervised.label_propagation.LabelSpreading.
- Renamed all occurrences of learn_rate to learning_rate for consistency in ensemble.BaseGradientBoosting and ensemble.GradientBoostingRegressor.
- The module sklearn.linear_model.sparse is gone. Sparse matrix support was already integrated into the “regular” linear models.
- sklearn.metrics.mean_square_error, which incorrectly returned the accumulated error, was removed. Use mean_squared_error instead.
- Passing class_weight parameters to fit methods is no longer supported. Pass them to estimator constructors instead.
- GMMs no longer have decode and rvs methods. Use the score, predict or sample methods instead.
- The solver fit option in Ridge regression and classification is now deprecated and will be removed in v0.14. Use the constructor option instead.
- feature_extraction.text.DictVectorizer now returns sparse matrices in the CSR format, instead of COO.
- Renamed k in cross_validation.KFold and cross_validation.StratifiedKFold to n_folds, renamed n_bootstraps to n_iter in cross_validation.Bootstrap.
- Renamed all occurrences of n_iterations to n_iter for consistency. This applies to cross_validation.ShuffleSplit, cross_validation.StratifiedShuffleSplit, utils.randomized_range_finder and utils.randomized_svd.
- Replaced rho in linear_model.ElasticNet and linear_model.SGDClassifier by l1_ratio. The rho parameter had different meanings; l1_ratio was introduced to avoid confusion. It has the same meaning as previously rho in linear_model.ElasticNet and (1-rho) in linear_model.SGDClassifier.
- linear_model.LassoLars and linear_model.Lars now store a list of paths in the case of multiple targets, rather than an array of paths.
- The attribute gmm of hmm.GMMHMM was renamed to gmm_ to adhere more strictly with the API.
- cluster.spectral_embedding was moved to manifold.spectral_embedding.
- Renamed eig_tol in manifold.spectral_embedding, cluster.SpectralClustering to eigen_tol, renamed mode to eigen_solver.
- Renamed mode in manifold.spectral_embedding and cluster.SpectralClustering to eigen_solver.
- classes_ and n_classes_ attributes of tree.DecisionTreeClassifier and all derived ensemble models are now flat in case of single output problems and nested in case of multi-output problems.
- The estimators_ attribute of ensemble.gradient_boosting.GradientBoostingRegressor and ensemble.gradient_boosting.GradientBoostingClassifier is now an array of :class:’tree.DecisionTreeRegressor’.
- Renamed chunk_size to batch_size in decomposition.MiniBatchDictionaryLearning and decomposition.MiniBatchSparsePCA for consistency.
- svm.SVC and svm.NuSVC now provide a classes_ attribute and support arbitrary dtypes for labels y. Also, the dtype returned by predict now reflects the dtype of y during fit (used to be np.float).
- Changed default test_size in cross_validation.train_test_split to None, added possibility to infer test_size from train_size in cross_validation.ShuffleSplit and cross_validation.StratifiedShuffleSplit.
- Renamed function sklearn.metrics.zero_one to sklearn.metrics.zero_one_loss. Be aware that the default behavior in sklearn.metrics.zero_one_loss is different from sklearn.metrics.zero_one: normalize=False is changed to normalize=True.
- Renamed function metrics.zero_one_score to metrics.accuracy_score.
- datasets.make_circles now has the same number of inner and outer points.
- In the Naive Bayes classifiers, the class_prior parameter was moved from fit to __init__.
People¶
List of contributors for release 0.13 by number of commits.
- 364 Andreas Müller
- 143 Arnaud Joly
- 137 Peter Prettenhofer
- 131 Gael Varoquaux
- 117 Mathieu Blondel
- 108 Lars Buitinck
- 106 Wei Li
- 101 Olivier Grisel
- 65 Vlad Niculae
- 54 Gilles Louppe
- 40 Jaques Grobler
- 38 Alexandre Gramfort
- 30 Rob Zinkov
- 19 Aymeric Masurelle
- 18 Andrew Winterman
- 17 Fabian Pedregosa
- 17 Nelle Varoquaux
- 16 Christian Osendorfer
- 14 Daniel Nouri
- 13 Virgile Fritsch
- 13 syhw
- 12 Satrajit Ghosh
- 10 Corey Lynch
- 10 Kyle Beauchamp
- 9 Brian Cheung
- 9 Immanuel Bayer
- 9 mr.Shu
- 8 Conrad Lee
- 8 James Bergstra
- 7 Tadej Janež
- 6 Brian Cajes
- 6 Jake Vanderplas
- 6 Michael
- 6 Noel Dawe
- 6 Tiago Nunes
- 6 cow
- 5 Anze
- 5 Shiqiao Du
- 4 Christian Jauvin
- 4 Jacques Kvam
- 4 Richard T. Guy
- 4 Robert Layton
- 3 Alexandre Abraham
- 3 Doug Coleman
- 3 Scott Dickerson
- 2 ApproximateIdentity
- 2 John Benediktsson
- 2 Mark Veronda
- 2 Matti Lyra
- 2 Mikhail Korobov
- 2 Xinfan Meng
- 1 Alejandro Weinstein
- 1 Alexandre Passos
- 1 Christoph Deil
- 1 Eugene Nizhibitsky
- 1 Kenneth C. Arnold
- 1 Luis Pedro Coelho
- 1 Miroslav Batchkarov
- 1 Pavel
- 1 Sebastian Berg
- 1 Shaun Jackman
- 1 Subhodeep Moitra
- 1 bob
- 1 dengemann
- 1 emanuele
- 1 x006
0.12.1¶
The 0.12.1 release is a bug-fix release with no additional features, but is instead a set of bug fixes
Changelog¶
- Improved numerical stability in spectral embedding by Gael Varoquaux
- Doctest under windows 64bit by Gael Varoquaux
- Documentation fixes for elastic net by Andreas Müller and Alexandre Gramfort
- Proper behavior with fortran-ordered NumPy arrays by Gael Varoquaux
- Make GridSearchCV work with non-CSR sparse matrix by Lars Buitinck
- Fix parallel computing in MDS by Gael Varoquaux
- Fix Unicode support in count vectorizer by Andreas Müller
- Fix MinCovDet breaking with X.shape = (3, 1) by Virgile Fritsch
- Fix clone of SGD objects by Peter Prettenhofer
- Stabilize GMM by Virgile Fritsch
People¶
0.12¶
Changelog¶
- Various speed improvements of the decision trees module, by Gilles Louppe.
- ensemble.GradientBoostingRegressor and ensemble.GradientBoostingClassifier now support feature subsampling via the max_features argument, by Peter Prettenhofer.
- Added Huber and Quantile loss functions to ensemble.GradientBoostingRegressor, by Peter Prettenhofer.
- Decision trees and forests of randomized trees now support multi-output classification and regression problems, by Gilles Louppe.
- Added preprocessing.LabelEncoder, a simple utility class to normalize labels or transform non-numerical labels, by Mathieu Blondel.
- Added the epsilon-insensitive loss and the ability to make probabilistic predictions with the modified huber loss in Stochastic Gradient Descent, by Mathieu Blondel.
- Added Multi-dimensional Scaling (MDS), by Nelle Varoquaux.
- SVMlight file format loader now detects compressed (gzip/bzip2) files and decompresses them on the fly, by Lars Buitinck.
- SVMlight file format serializer now preserves double precision floating point values, by Olivier Grisel.
- A common testing framework for all estimators was added, by Andreas Müller.
- Understandable error messages for estimators that do not accept sparse input by Gael Varoquaux
- Speedups in hierarchical clustering by Gael Varoquaux. In particular building the tree now supports early stopping. This is useful when the number of clusters is not small compared to the number of samples.
- Add MultiTaskLasso and MultiTaskElasticNet for joint feature selection, by Alexandre Gramfort.
- Added metrics.auc_score and metrics.average_precision_score convenience functions by Andreas Müller.
- Improved sparse matrix support in the Feature selection module by Andreas Müller.
- New word boundaries-aware character n-gram analyzer for the Text feature extraction module by @kernc.
- Fixed bug in spectral clustering that led to single point clusters by Andreas Müller.
- In feature_extraction.text.CountVectorizer, added an option to ignore infrequent words, min_df by Andreas Müller.
- Add support for multiple targets in some linear models (ElasticNet, Lasso and OrthogonalMatchingPursuit) by Vlad Niculae and Alexandre Gramfort.
- Fixes in decomposition.ProbabilisticPCA score function by Wei Li.
- Fixed feature importance computation in Gradient Tree Boosting.
API changes summary¶
- The old scikits.learn package has disappeared; all code should import from sklearn instead, which was introduced in 0.9.
- In metrics.roc_curve, the thresholds array is now returned with it’s order reversed, in order to keep it consistent with the order of the returned fpr and tpr.
- In hmm objects, like hmm.GaussianHMM, hmm.MultinomialHMM, etc., all parameters must be passed to the object when initialising it and not through fit. Now fit will only accept the data as an input parameter.
- For all SVM classes, a faulty behavior of gamma was fixed. Previously, the default gamma value was only computed the first time fit was called and then stored. It is now recalculated on every call to fit.
- All Base classes are now abstract meta classes so that they can not be instantiated.
- cluster.ward_tree now also returns the parent array. This is necessary for early-stopping in which case the tree is not completely built.
- In feature_extraction.text.CountVectorizer the parameters min_n and max_n were joined to the parameter n_gram_range to enable grid-searching both at once.
- In feature_extraction.text.CountVectorizer, words that appear only in one document are now ignored by default. To reproduce the previous behavior, set min_df=1.
- Fixed API inconsistency: linear_model.SGDClassifier.predict_proba now returns 2d array when fit on two classes.
- Fixed API inconsistency: qda.QDA.decision_function and lda.LDA.decision_function now return 1d arrays when fit on two classes.
- Grid of alphas used for fitting linear_model.LassoCV and linear_model.ElasticNetCV is now stored in the attribute alphas_ rather than overriding the init parameter alphas.
- Linear models when alpha is estimated by cross-validation store the estimated value in the alpha_ attribute rather than just alpha or best_alpha.
- ensemble.GradientBoostingClassifier now supports ensemble.GradientBoostingClassifier.staged_predict_proba, and ensemble.GradientBoostingClassifier.staged_predict.
- svm.sparse.SVC and other sparse SVM classes are now deprecated. The all classes in the Support Vector Machines module now automatically select the sparse or dense representation base on the input.
- All clustering algorithms now interpret the array X given to fit as input data, in particular cluster.SpectralClustering and cluster.AffinityPropagation which previously expected affinity matrices.
- For clustering algorithms that take the desired number of clusters as a parameter, this parameter is now called n_clusters.
People¶
- 267 Andreas Müller
- 94 Gilles Louppe
- 89 Gael Varoquaux
- 79 Peter Prettenhofer
- 60 Mathieu Blondel
- 57 Alexandre Gramfort
- 52 Vlad Niculae
- 45 Lars Buitinck
- 44 Nelle Varoquaux
- 37 Jaques Grobler
- 30 Alexis Mignon
- 30 Immanuel Bayer
- 27 Olivier Grisel
- 16 Subhodeep Moitra
- 13 Yannick Schwartz
- 12 @kernc
- 11 Virgile Fritsch
- 9 Daniel Duckworth
- 9 Fabian Pedregosa
- 9 Robert Layton
- 8 John Benediktsson
- 7 Marko Burjek
- 5 Nicolas Pinto
- 4 Alexandre Abraham
- 4 Jake Vanderplas
- 3 Brian Holt
- 3 Edouard Duchesnay
- 3 Florian Hoenig
- 3 flyingimmidev
- 2 Francois Savard
- 2 Hannes Schulz
- 2 Peter Welinder
- 2 Yaroslav Halchenko
- 2 Wei Li
- 1 Alex Companioni
- 1 Brandyn A. White
- 1 Bussonnier Matthias
- 1 Charles-Pierre Astolfi
- 1 Dan O’Huiginn
- 1 David Cournapeau
- 1 Keith Goodman
- 1 Ludwig Schwardt
- 1 Olivier Hervieu
- 1 Sergio Medina
- 1 Shiqiao Du
- 1 Tim Sheerman-Chase
- 1 buguen
0.11¶
Changelog¶
Highlights¶
- Gradient boosted regression trees (Gradient Tree Boosting) for classification and regression by Peter Prettenhofer and Scott White .
- Simple dict-based feature loader with support for categorical variables (feature_extraction.DictVectorizer) by Lars Buitinck.
- Added Matthews correlation coefficient (metrics.matthews_corrcoef) and added macro and micro average options to metrics.precision_score, metrics.recall_score and metrics.f1_score by Satrajit Ghosh.
- Out of Bag Estimates of generalization error for Ensemble methods by Andreas Müller.
- Randomized sparse models: Randomized sparse linear models for feature selection, by Alexandre Gramfort and Gael Varoquaux
- Label Propagation for semi-supervised learning, by Clay Woolam. Note the semi-supervised API is still work in progress, and may change.
- Added BIC/AIC model selection to classical Gaussian mixture models and unified the API with the remainder of scikit-learn, by Bertrand Thirion
- Added sklearn.cross_validation.StratifiedShuffleSplit, which is a sklearn.cross_validation.ShuffleSplit with balanced splits, by Yannick Schwartz.
- sklearn.neighbors.NearestCentroid classifier added, along with a shrink_threshold parameter, which implements shrunken centroid classification, by Robert Layton.
Other changes¶
- Merged dense and sparse implementations of Stochastic Gradient Descent module and exposed utility extension types for sequential datasets seq_dataset and weight vectors weight_vector by Peter Prettenhofer.
- Added partial_fit (support for online/minibatch learning) and warm_start to the Stochastic Gradient Descent module by Mathieu Blondel.
- Dense and sparse implementations of Support Vector Machines classes and linear_model.LogisticRegression merged by Lars Buitinck.
- Regressors can now be used as base estimator in the Multiclass and multilabel algorithms module by Mathieu Blondel.
- Added n_jobs option to metrics.pairwise.pairwise_distances and metrics.pairwise.pairwise_kernels for parallel computation, by Mathieu Blondel.
- K-means can now be run in parallel, using the n_jobs argument to either K-means or KMeans, by Robert Layton.
- Improved Cross-validation: evaluating estimator performance and Grid Search: Searching for estimator parameters documentation and introduced the new cross_validation.train_test_split helper function by Olivier Grisel
- svm.SVC members coef_ and intercept_ changed sign for consistency with decision_function; for kernel==linear, coef_ was fixed in the the one-vs-one case, by Andreas Müller.
- Performance improvements to efficient leave-one-out cross-validated Ridge regression, esp. for the n_samples > n_features case, in linear_model.RidgeCV, by Reuben Fletcher-Costin.
- Refactoring and simplification of the Text feature extraction API and fixed a bug that caused possible negative IDF, by Olivier Grisel.
- Beam pruning option in _BaseHMM module has been removed since it is difficult to Cythonize. If you are interested in contributing a Cython version, you can use the python version in the git history as a reference.
- Classes in Nearest Neighbors now support arbitrary Minkowski metric for nearest neighbors searches. The metric can be specified by argument p.
API changes summary¶
covariance.EllipticEnvelop is now deprecated - Please use covariance.EllipticEnvelope instead.
NeighborsClassifier and NeighborsRegressor are gone in the module Nearest Neighbors. Use the classes KNeighborsClassifier, RadiusNeighborsClassifier, KNeighborsRegressor and/or RadiusNeighborsRegressor instead.
Sparse classes in the Stochastic Gradient Descent module are now deprecated.
In mixture.GMM, mixture.DPGMM and mixture.VBGMM, parameters must be passed to an object when initialising it and not through fit. Now fit will only accept the data as an input parameter.
methods rvs and decode in GMM module are now deprecated. sample and score or predict should be used instead.
attribute _scores and _pvalues in univariate feature selection objects are now deprecated. scores_ or pvalues_ should be used instead.
In LogisticRegression, LinearSVC, SVC and NuSVC, the class_weight parameter is now an initialization parameter, not a parameter to fit. This makes grid searches over this parameter possible.
LFW data is now always shape (n_samples, n_features) to be consistent with the Olivetti faces dataset. Use images and pairs attribute to access the natural images shapes instead.
In svm.LinearSVC, the meaning of the multi_class parameter changed. Options now are 'ovr' and 'crammer_singer', with 'ovr' being the default. This does not change the default behavior but hopefully is less confusing.
Class feature_selection.text.Vectorizer is deprecated and replaced by feature_selection.text.TfidfVectorizer.
The preprocessor / analyzer nested structure for text feature extraction has been removed. All those features are now directly passed as flat constructor arguments to feature_selection.text.TfidfVectorizer and feature_selection.text.CountVectorizer, in particular the following parameters are now used:
- analyzer can be 'word' or 'char' to switch the default analysis scheme, or use a specific python callable (as previously).
- tokenizer and preprocessor have been introduced to make it still possible to customize those steps with the new API.
- input explicitly control how to interpret the sequence passed to fit and predict: filenames, file objects or direct (byte or Unicode) strings.
- charset decoding is explicit and strict by default.
- the vocabulary, fitted or not is now stored in the vocabulary_ attribute to be consistent with the project conventions.
Class feature_selection.text.TfidfVectorizer now derives directly from feature_selection.text.CountVectorizer to make grid search trivial.
methods rvs in _BaseHMM module are now deprecated. sample should be used instead.
Beam pruning option in _BaseHMM module is removed since it is difficult to be Cythonized. If you are interested, you can look in the history codes by git.
The SVMlight format loader now supports files with both zero-based and one-based column indices, since both occur “in the wild”.
Arguments in class ShuffleSplit are now consistent with StratifiedShuffleSplit. Arguments test_fraction and train_fraction are deprecated and renamed to test_size and train_size and can accept both float and int.
Arguments in class Bootstrap are now consistent with StratifiedShuffleSplit. Arguments n_test and n_train are deprecated and renamed to test_size and train_size and can accept both float and int.
Argument p added to classes in Nearest Neighbors to specify an arbitrary Minkowski metric for nearest neighbors searches.
People¶
- 282 Andreas Müller
- 239 Peter Prettenhofer
- 198 Gael Varoquaux
- 129 Olivier Grisel
- 114 Mathieu Blondel
- 103 Clay Woolam
- 96 Lars Buitinck
- 88 Jaques Grobler
- 82 Alexandre Gramfort
- 50 Bertrand Thirion
- 42 Robert Layton
- 28 flyingimmidev
- 26 Jake Vanderplas
- 26 Shiqiao Du
- 21 Satrajit Ghosh
- 17 David Marek
- 17 Gilles Louppe
- 14 Vlad Niculae
- 11 Yannick Schwartz
- 10 Fabian Pedregosa
- 9 fcostin
- 7 Nick Wilson
- 5 Adrien Gaidon
- 5 Nicolas Pinto
- 4 David Warde-Farley
- 5 Nelle Varoquaux
- 5 Emmanuelle Gouillart
- 3 Joonas Sillanpää
- 3 Paolo Losi
- 2 Charles McCarthy
- 2 Roy Hyunjin Han
- 2 Scott White
- 2 ibayer
- 1 Brandyn White
- 1 Carlos Scheidegger
- 1 Claire Revillet
- 1 Conrad Lee
- 1 Edouard Duchesnay
- 1 Jan Hendrik Metzen
- 1 Meng Xinfan
- 1 Rob Zinkov
- 1 Shiqiao
- 1 Udi Weinsberg
- 1 Virgile Fritsch
- 1 Xinfan Meng
- 1 Yaroslav Halchenko
- 1 jansoe
- 1 Leon Palafox
0.10¶
Changelog¶
- Python 2.5 compatibility was dropped; the minimum Python version needed to use scikit-learn is now 2.6.
- Sparse inverse covariance estimation using the graph Lasso, with associated cross-validated estimator, by Gael Varoquaux
- New Tree module by Brian Holt, Peter Prettenhofer, Satrajit Ghosh and Gilles Louppe. The module comes with complete documentation and examples.
- Fixed a bug in the RFE module by Gilles Louppe (issue #378).
- Fixed a memory leak in in Support Vector Machines module by Brian Holt (issue #367).
- Faster tests by Fabian Pedregosa and others.
- Silhouette Coefficient cluster analysis evaluation metric added as sklearn.metrics.silhouette_score by Robert Layton.
- Fixed a bug in K-means in the handling of the n_init parameter: the clustering algorithm used to be run n_init times but the last solution was retained instead of the best solution by Olivier Grisel.
- Minor refactoring in Stochastic Gradient Descent module; consolidated dense and sparse predict methods; Enhanced test time performance by converting model parameters to fortran-style arrays after fitting (only multi-class).
- Adjusted Mutual Information metric added as sklearn.metrics.adjusted_mutual_info_score by Robert Layton.
- Models like SVC/SVR/LinearSVC/LogisticRegression from libsvm/liblinear now support scaling of C regularization parameter by the number of samples by Alexandre Gramfort.
- New Ensemble Methods module by Gilles Louppe and Brian Holt. The module comes with the random forest algorithm and the extra-trees method, along with documentation and examples.
- Novelty and Outlier Detection: outlier and novelty detection, by Virgile Fritsch.
- Kernel Approximation: a transform implementing kernel approximation for fast SGD on non-linear kernels by Andreas Müller.
- Fixed a bug due to atom swapping in Orthogonal Matching Pursuit (OMP) by Vlad Niculae.
- Sparse coding with a precomputed dictionary by Vlad Niculae.
- Mini Batch K-Means performance improvements by Olivier Grisel.
- K-means support for sparse matrices by Mathieu Blondel.
- Improved documentation for developers and for the sklearn.utils module, by Jake Vanderplas.
- Vectorized 20newsgroups dataset loader (sklearn.datasets.fetch_20newsgroups_vectorized) by Mathieu Blondel.
- Multiclass and multilabel algorithms by Lars Buitinck.
- Utilities for fast computation of mean and variance for sparse matrices by Mathieu Blondel.
- Make sklearn.preprocessing.scale and sklearn.preprocessing.Scaler work on sparse matrices by Olivier Grisel
- Feature importances using decision trees and/or forest of trees, by Gilles Louppe.
- Parallel implementation of forests of randomized trees by Gilles Louppe.
- sklearn.cross_validation.ShuffleSplit can subsample the train sets as well as the test sets by Olivier Grisel.
- Errors in the build of the documentation fixed by Andreas Müller.
API changes summary¶
Here are the code migration instructions when upgrading from scikit-learn version 0.9:
Some estimators that may overwrite their inputs to save memory previously had overwrite_ parameters; these have been replaced with copy_ parameters with exactly the opposite meaning.
This particularly affects some of the estimators in linear_model. The default behavior is still to copy everything passed in.
The SVMlight dataset loader sklearn.datasets.load_svmlight_file no longer supports loading two files at once; use load_svmlight_files instead. Also, the (unused) buffer_mb parameter is gone.
Sparse estimators in the Stochastic Gradient Descent module use dense parameter vector coef_ instead of sparse_coef_. This significantly improves test time performance.
The Covariance estimation module now has a robust estimator of covariance, the Minimum Covariance Determinant estimator.
Cluster evaluation metrics in metrics.cluster have been refactored but the changes are backwards compatible. They have been moved to the metrics.cluster.supervised, along with metrics.cluster.unsupervised which contains the Silhouette Coefficient.
The permutation_test_score function now behaves the same way as cross_val_score (i.e. uses the mean score across the folds.)
Cross Validation generators now use integer indices (indices=True) by default instead of boolean masks. This make it more intuitive to use with sparse matrix data.
The functions used for sparse coding, sparse_encode and sparse_encode_parallel have been combined into sklearn.decomposition.sparse_encode, and the shapes of the arrays have been transposed for consistency with the matrix factorization setting, as opposed to the regression setting.
Fixed an off-by-one error in the SVMlight/LibSVM file format handling; files generated using sklearn.datasets.dump_svmlight_file should be re-generated. (They should continue to work, but accidentally had one extra column of zeros prepended.)
BaseDictionaryLearning class replaced by SparseCodingMixin.
sklearn.utils.extmath.fast_svd has been renamed sklearn.utils.extmath.randomized_svd and the default oversampling is now fixed to 10 additional random vectors instead of doubling the number of components to extract. The new behavior follows the reference paper.
People¶
The following people contributed to scikit-learn since last release:
- 246 Andreas Müller
- 242 Olivier Grisel
- 220 Gilles Louppe
- 183 Brian Holt
- 166 Gael Varoquaux
- 144 Lars Buitinck
- 73 Vlad Niculae
- 65 Peter Prettenhofer
- 64 Fabian Pedregosa
- 60 Robert Layton
- 55 Mathieu Blondel
- 52 Jake Vanderplas
- 44 Noel Dawe
- 38 Alexandre Gramfort
- 24 Virgile Fritsch
- 23 Satrajit Ghosh
- 3 Jan Hendrik Metzen
- 3 Kenneth C. Arnold
- 3 Shiqiao Du
- 3 Tim Sheerman-Chase
- 3 Yaroslav Halchenko
- 2 Bala Subrahmanyam Varanasi
- 2 DraXus
- 2 Michael Eickenberg
- 1 Bogdan Trach
- 1 Félix-Antoine Fortin
- 1 Juan Manuel Caicedo Carvajal
- 1 Nelle Varoquaux
- 1 Nicolas Pinto
- 1 Tiziano Zito
- 1 Xinfan Meng
0.9¶
scikit-learn 0.9 was released on September 2011, three months after the 0.8 release and includes the new modules Manifold learning, The Dirichlet Process as well as several new algorithms and documentation improvements.
This release also includes the dictionary-learning work developed by Vlad Niculae as part of the Google Summer of Code program.
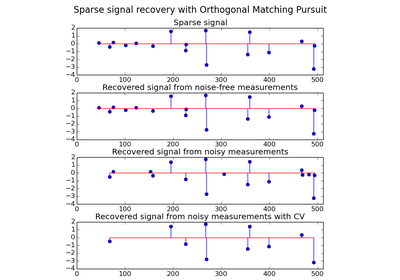

Changelog¶
- New Manifold learning module by Jake Vanderplas and Fabian Pedregosa.
- New Dirichlet Process Gaussian Mixture Model by Alexandre Passos
- Nearest Neighbors module refactoring by Jake Vanderplas : general refactoring, support for sparse matrices in input, speed and documentation improvements. See the next section for a full list of API changes.
- Improvements on the Feature selection module by Gilles Louppe : refactoring of the RFE classes, documentation rewrite, increased efficiency and minor API changes.
- Sparse principal components analysis (SparsePCA and MiniBatchSparsePCA) by Vlad Niculae, Gael Varoquaux and Alexandre Gramfort
- Printing an estimator now behaves independently of architectures and Python version thanks to Jean Kossaifi.
- Loader for libsvm/svmlight format by Mathieu Blondel and Lars Buitinck
- Documentation improvements: thumbnails in example gallery by Fabian Pedregosa.
- Important bugfixes in Support Vector Machines module (segfaults, bad performance) by Fabian Pedregosa.
- Added Multinomial Naive Bayes and Bernoulli Naive Bayes by Lars Buitinck
- Text feature extraction optimizations by Lars Buitinck
- Chi-Square feature selection (feature_selection.univariate_selection.chi2) by Lars Buitinck.
- Sample generators module refactoring by Gilles Louppe
- Multiclass and multilabel algorithms by Mathieu Blondel
- Ball tree rewrite by Jake Vanderplas
- Implementation of DBSCAN algorithm by Robert Layton
- Kmeans predict and transform by Robert Layton
- Preprocessing module refactoring by Olivier Grisel
- Faster mean shift by Conrad Lee
- New Bootstrap, Random permutations cross-validation a.k.a. Shuffle & Split and various other improvements in cross validation schemes by Olivier Grisel and Gael Varoquaux
- Adjusted Rand index and V-Measure clustering evaluation metrics by Olivier Grisel
- Added Orthogonal Matching Pursuit by Vlad Niculae
- Added 2D-patch extractor utilities in the Feature extraction module by Vlad Niculae
- Implementation of linear_model.LassoLarsCV (cross-validated Lasso solver using the Lars algorithm) and linear_model.LassoLarsIC (BIC/AIC model selection in Lars) by Gael Varoquaux and Alexandre Gramfort
- Scalability improvements to metrics.roc_curve by Olivier Hervieu
- Distance helper functions metrics.pairwise.pairwise_distances and metrics.pairwise.pairwise_kernels by Robert Layton
- Mini-Batch K-Means by Nelle Varoquaux and Peter Prettenhofer.
- Downloading datasets from the mldata.org repository utilities by Pietro Berkes.
- The Olivetti faces dataset by David Warde-Farley.
API changes summary¶
Here are the code migration instructions when upgrading from scikit-learn version 0.8:
The scikits.learn package was renamed sklearn. There is still a scikits.learn package alias for backward compatibility.
Third-party projects with a dependency on scikit-learn 0.9+ should upgrade their codebase. For instance under Linux / MacOSX just run (make a backup first!):
find -name "*.py" | xargs sed -i 's/\bscikits.learn\b/sklearn/g'Estimators no longer accept model parameters as fit arguments: instead all parameters must be only be passed as constructor arguments or using the now public set_params method inherited from base.BaseEstimator.
Some estimators can still accept keyword arguments on the fit but this is restricted to data-dependent values (e.g. a Gram matrix or an affinity matrix that are precomputed from the X data matrix.
The cross_val package has been renamed to cross_validation although there is also a cross_val package alias in place for backward compatibility.
Third-party projects with a dependency on scikit-learn 0.9+ should upgrade their codebase. For instance under Linux / MacOSX just run (make a backup first!):
find -name "*.py" | xargs sed -i 's/\bcross_val\b/cross_validation/g'The score_func argument of the sklearn.cross_validation.cross_val_score function is now expected to accept y_test and y_predicted as only arguments for classification and regression tasks or X_test for unsupervised estimators.
gamma parameter for support vector machine algorithms is set to 1 / n_features by default, instead of 1 / n_samples.
The sklearn.hmm has been marked as orphaned: it will be removed from scikit-learn in version 0.11 unless someone steps up to contribute documentation, examples and fix lurking numerical stability issues.
sklearn.neighbors has been made into a submodule. The two previously available estimators, NeighborsClassifier and NeighborsRegressor have been marked as deprecated. Their functionality has been divided among five new classes: NearestNeighbors for unsupervised neighbors searches, KNeighborsClassifier & RadiusNeighborsClassifier for supervised classification problems, and KNeighborsRegressor & RadiusNeighborsRegressor for supervised regression problems.
sklearn.ball_tree.BallTree has been moved to sklearn.neighbors.BallTree. Using the former will generate a warning.
sklearn.linear_model.LARS() and related classes (LassoLARS, LassoLARSCV, etc.) have been renamed to sklearn.linear_model.Lars().
All distance metrics and kernels in sklearn.metrics.pairwise now have a Y parameter, which by default is None. If not given, the result is the distance (or kernel similarity) between each sample in Y. If given, the result is the pairwise distance (or kernel similarity) between samples in X to Y.
sklearn.metrics.pairwise.l1_distance is now called manhattan_distance, and by default returns the pairwise distance. For the component wise distance, set the parameter sum_over_features to False.
Backward compatibility package aliases and other deprecated classes and functions will be removed in version 0.11.
People¶
38 people contributed to this release.
- 387 Vlad Niculae
- 320 Olivier Grisel
- 192 Lars Buitinck
- 179 Gael Varoquaux
- 168 Fabian Pedregosa (INRIA, Parietal Team)
- 127 Jake Vanderplas
- 120 Mathieu Blondel
- 85 Alexandre Passos
- 67 Alexandre Gramfort
- 57 Peter Prettenhofer
- 56 Gilles Louppe
- 42 Robert Layton
- 38 Nelle Varoquaux
- 32 Jean Kossaifi
- 30 Conrad Lee
- 22 Pietro Berkes
- 18 andy
- 17 David Warde-Farley
- 12 Brian Holt
- 11 Robert
- 8 Amit Aides
- 8 Virgile Fritsch
- 7 Yaroslav Halchenko
- 6 Salvatore Masecchia
- 5 Paolo Losi
- 4 Vincent Schut
- 3 Alexis Metaireau
- 3 Bryan Silverthorn
- 3 Andreas Müller
- 2 Minwoo Jake Lee
- 1 Emmanuelle Gouillart
- 1 Keith Goodman
- 1 Lucas Wiman
- 1 Nicolas Pinto
- 1 Thouis (Ray) Jones
- 1 Tim Sheerman-Chase
0.8¶
scikit-learn 0.8 was released on May 2011, one month after the first “international” scikit-learn coding sprint and is marked by the inclusion of important modules: Hierarchical clustering, Cross decomposition, Non-negative matrix factorization (NMF or NNMF), initial support for Python 3 and by important enhancements and bug fixes.
Changelog¶
Several new modules where introduced during this release:
- New Hierarchical clustering module by Vincent Michel, Bertrand Thirion, Alexandre Gramfort and Gael Varoquaux.
- Kernel PCA implementation by Mathieu Blondel
- The Labeled Faces in the Wild face recognition dataset by Olivier Grisel.
- New Cross decomposition module by Edouard Duchesnay.
- Non-negative matrix factorization (NMF or NNMF) module Vlad Niculae
- Implementation of the Oracle Approximating Shrinkage algorithm by Virgile Fritsch in the Covariance estimation module.
Some other modules benefited from significant improvements or cleanups.
- Initial support for Python 3: builds and imports cleanly, some modules are usable while others have failing tests by Fabian Pedregosa.
- decomposition.PCA is now usable from the Pipeline object by Olivier Grisel.
- Guide How to optimize for speed by Olivier Grisel.
- Fixes for memory leaks in libsvm bindings, 64-bit safer BallTree by Lars Buitinck.
- bug and style fixing in K-means algorithm by Jan Schlüter.
- Add attribute converged to Gaussian Mixture Models by Vincent Schut.
- Implemented transform, predict_log_proba in lda.LDA By Mathieu Blondel.
- Refactoring in the Support Vector Machines module and bug fixes by Fabian Pedregosa, Gael Varoquaux and Amit Aides.
- Refactored SGD module (removed code duplication, better variable naming), added interface for sample weight by Peter Prettenhofer.
- Wrapped BallTree with Cython by Thouis (Ray) Jones.
- Added function svm.l1_min_c by Paolo Losi.
- Typos, doc style, etc. by Yaroslav Halchenko, Gael Varoquaux, Olivier Grisel, Yann Malet, Nicolas Pinto, Lars Buitinck and Fabian Pedregosa.
People¶
People that made this release possible preceded by number of commits:
- 159 Olivier Grisel
- 96 Gael Varoquaux
- 96 Vlad Niculae
- 94 Fabian Pedregosa
- 36 Alexandre Gramfort
- 32 Paolo Losi
- 31 Edouard Duchesnay
- 30 Mathieu Blondel
- 25 Peter Prettenhofer
- 22 Nicolas Pinto
- 11 Virgile Fritsch
- 7 Lars Buitinck
- 6 Vincent Michel
- 5 Bertrand Thirion
- 4 Thouis (Ray) Jones
- 4 Vincent Schut
- 3 Jan Schlüter
- 2 Julien Miotte
- 2 Matthieu Perrot
- 2 Yann Malet
- 2 Yaroslav Halchenko
- 1 Amit Aides
- 1 Andreas Müller
- 1 Feth Arezki
- 1 Meng Xinfan
0.7¶
scikit-learn 0.7 was released in March 2011, roughly three months after the 0.6 release. This release is marked by the speed improvements in existing algorithms like k-Nearest Neighbors and K-Means algorithm and by the inclusion of an efficient algorithm for computing the Ridge Generalized Cross Validation solution. Unlike the preceding release, no new modules where added to this release.
Changelog¶
- Performance improvements for Gaussian Mixture Model sampling [Jan Schlüter].
- Implementation of efficient leave-one-out cross-validated Ridge in linear_model.RidgeCV [Mathieu Blondel]
- Better handling of collinearity and early stopping in linear_model.lars_path [Alexandre Gramfort and Fabian Pedregosa].
- Fixes for liblinear ordering of labels and sign of coefficients [Dan Yamins, Paolo Losi, Mathieu Blondel and Fabian Pedregosa].
- Performance improvements for Nearest Neighbors algorithm in high-dimensional spaces [Fabian Pedregosa].
- Performance improvements for cluster.KMeans [Gael Varoquaux and James Bergstra].
- Sanity checks for SVM-based classes [Mathieu Blondel].
- Refactoring of neighbors.NeighborsClassifier and neighbors.kneighbors_graph: added different algorithms for the k-Nearest Neighbor Search and implemented a more stable algorithm for finding barycenter weights. Also added some developer documentation for this module, see notes_neighbors for more information [Fabian Pedregosa].
- Documentation improvements: Added pca.RandomizedPCA and linear_model.LogisticRegression to the class reference. Also added references of matrices used for clustering and other fixes [Gael Varoquaux, Fabian Pedregosa, Mathieu Blondel, Olivier Grisel, Virgile Fritsch , Emmanuelle Gouillart]
- Binded decision_function in classes that make use of liblinear, dense and sparse variants, like svm.LinearSVC or linear_model.LogisticRegression [Fabian Pedregosa].
- Performance and API improvements to metrics.euclidean_distances and to pca.RandomizedPCA [James Bergstra].
- Fix compilation issues under NetBSD [Kamel Ibn Hassen Derouiche]
- Allow input sequences of different lengths in hmm.GaussianHMM [Ron Weiss].
- Fix bug in affinity propagation caused by incorrect indexing [Xinfan Meng]
People¶
People that made this release possible preceded by number of commits:
- 85 Fabian Pedregosa
- 67 Mathieu Blondel
- 20 Alexandre Gramfort
- 19 James Bergstra
- 14 Dan Yamins
- 13 Olivier Grisel
- 12 Gael Varoquaux
- 4 Edouard Duchesnay
- 4 Ron Weiss
- 2 Satrajit Ghosh
- 2 Vincent Dubourg
- 1 Emmanuelle Gouillart
- 1 Kamel Ibn Hassen Derouiche
- 1 Paolo Losi
- 1 VirgileFritsch
- 1 Yaroslav Halchenko
- 1 Xinfan Meng
0.6¶
scikit-learn 0.6 was released on December 2010. It is marked by the inclusion of several new modules and a general renaming of old ones. It is also marked by the inclusion of new example, including applications to real-world datasets.
Changelog¶
- New stochastic gradient descent module by Peter Prettenhofer. The module comes with complete documentation and examples.
- Improved svm module: memory consumption has been reduced by 50%, heuristic to automatically set class weights, possibility to assign weights to samples (see SVM: Weighted samples for an example).
- New Gaussian Processes module by Vincent Dubourg. This module also has great documentation and some very neat examples. See Gaussian Processes regression: basic introductory example or Gaussian Processes classification example: exploiting the probabilistic output for a taste of what can be done.
- It is now possible to use liblinear’s Multi-class SVC (option multi_class in svm.LinearSVC)
- New features and performance improvements of text feature extraction.
- Improved sparse matrix support, both in main classes (grid_search.GridSearchCV) as in modules sklearn.svm.sparse and sklearn.linear_model.sparse.
- Lots of cool new examples and a new section that uses real-world datasets was created. These include: Faces recognition example using eigenfaces and SVMs, Species distribution modeling, Libsvm GUI, Wikipedia principal eigenvector and others.
- Faster Least Angle Regression algorithm. It is now 2x faster than the R version on worst case and up to 10x times faster on some cases.
- Faster coordinate descent algorithm. In particular, the full path version of lasso (linear_model.lasso_path) is more than 200x times faster than before.
- It is now possible to get probability estimates from a linear_model.LogisticRegression model.
- module renaming: the glm module has been renamed to linear_model, the gmm module has been included into the more general mixture model and the sgd module has been included in linear_model.
- Lots of bug fixes and documentation improvements.
People¶
People that made this release possible preceded by number of commits:
- 207 Olivier Grisel
- 167 Fabian Pedregosa
- 97 Peter Prettenhofer
- 68 Alexandre Gramfort
- 59 Mathieu Blondel
- 55 Gael Varoquaux
- 33 Vincent Dubourg
- 21 Ron Weiss
- 9 Bertrand Thirion
- 3 Alexandre Passos
- 3 Anne-Laure Fouque
- 2 Ronan Amicel
- 1 Christian Osendorfer
0.5¶
Changelog¶
New classes¶
- Support for sparse matrices in some classifiers of modules svm and linear_model (see svm.sparse.SVC, svm.sparse.SVR, svm.sparse.LinearSVC, linear_model.sparse.Lasso, linear_model.sparse.ElasticNet)
- New pipeline.Pipeline object to compose different estimators.
- Recursive Feature Elimination routines in module Feature selection.
- Addition of various classes capable of cross validation in the linear_model module (linear_model.LassoCV, linear_model.ElasticNetCV, etc.).
- New, more efficient LARS algorithm implementation. The Lasso variant of the algorithm is also implemented. See linear_model.lars_path, linear_model.Lars and linear_model.LassoLars.
- New Hidden Markov Models module (see classes hmm.GaussianHMM, hmm.MultinomialHMM, hmm.GMMHMM)
- New module feature_extraction (see class reference)
- New FastICA algorithm in module sklearn.fastica
Documentation¶
- Improved documentation for many modules, now separating narrative documentation from the class reference. As an example, see documentation for the SVM module and the complete class reference.
Fixes¶
- API changes: adhere variable names to PEP-8, give more meaningful names.
- Fixes for svm module to run on a shared memory context (multiprocessing).
- It is again possible to generate latex (and thus PDF) from the sphinx docs.
Examples¶
- new examples using some of the mlcomp datasets: example_mlcomp_sparse_document_classification.py (since removed) and Classification of text documents using sparse features
- Many more examples. See here the full list of examples.
External dependencies¶
- Joblib is now a dependency of this package, although it is shipped with (sklearn.externals.joblib).
Removed modules¶
- Module ann (Artificial Neural Networks) has been removed from the distribution. Users wanting this sort of algorithms should take a look into pybrain.
Misc¶
- New sphinx theme for the web page.
Authors¶
The following is a list of authors for this release, preceded by number of commits:
- 262 Fabian Pedregosa
- 240 Gael Varoquaux
- 149 Alexandre Gramfort
- 116 Olivier Grisel
- 40 Vincent Michel
- 38 Ron Weiss
- 23 Matthieu Perrot
- 10 Bertrand Thirion
- 7 Yaroslav Halchenko
- 9 VirgileFritsch
- 6 Edouard Duchesnay
- 4 Mathieu Blondel
- 1 Ariel Rokem
- 1 Matthieu Brucher
0.4¶
Changelog¶
Major changes in this release include:
- Coordinate Descent algorithm (Lasso, ElasticNet) refactoring & speed improvements (roughly 100x times faster).
- Coordinate Descent Refactoring (and bug fixing) for consistency with R’s package GLMNET.
- New metrics module.
- New GMM module contributed by Ron Weiss.
- Implementation of the LARS algorithm (without Lasso variant for now).
- feature_selection module redesign.
- Migration to GIT as version control system.
- Removal of obsolete attrselect module.
- Rename of private compiled extensions (added underscore).
- Removal of legacy unmaintained code.
- Documentation improvements (both docstring and rst).
- Improvement of the build system to (optionally) link with MKL. Also, provide a lite BLAS implementation in case no system-wide BLAS is found.
- Lots of new examples.
- Many, many bug fixes ...
Authors¶
The committer list for this release is the following (preceded by number of commits):
- 143 Fabian Pedregosa
- 35 Alexandre Gramfort
- 34 Olivier Grisel
- 11 Gael Varoquaux
- 5 Yaroslav Halchenko
- 2 Vincent Michel
- 1 Chris Filo Gorgolewski
Earlier versions¶
Earlier versions included contributions by Fred Mailhot, David Cooke, David Huard, Dave Morrill, Ed Schofield, Travis Oliphant, Pearu Peterson.