sklearn.datasets.make_biclusters¶
- sklearn.datasets.make_biclusters(shape, n_clusters, noise=0.0, minval=10, maxval=100, shuffle=True, random_state=None)¶
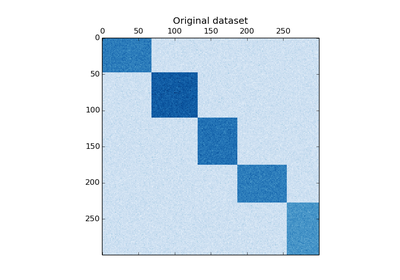
Generate an array with constant block diagonal structure for biclustering.
Parameters: shape : iterable (n_rows, n_cols)
The shape of the result.
n_clusters : integer
The number of biclusters.
noise : float, optional (default=0.0)
The standard deviation of the gaussian noise.
minval : int, optional (default=10)
Minimum value of a bicluster.
maxval : int, optional (default=100)
Maximum value of a bicluster.
shuffle : boolean, optional (default=True)
Shuffle the samples.
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
Returns: X : array of shape shape
The generated array.
rows : array of shape (n_clusters, X.shape[0],)
The indicators for cluster membership of each row.
cols : array of shape (n_clusters, X.shape[1],)
The indicators for cluster membership of each column.
References
[R13] Dhillon, I. S. (2001, August). Co-clustering documents and words using bipartite spectral graph partitioning. In Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 269-274). ACM.