sklearn.lda.LDA¶
- class sklearn.lda.LDA(n_components=None, priors=None)¶
Linear Discriminant Analysis (LDA)
A classifier with a linear decision boundary, generated by fitting class conditional densities to the data and using Bayes’ rule.
The model fits a Gaussian density to each class, assuming that all classes share the same covariance matrix.
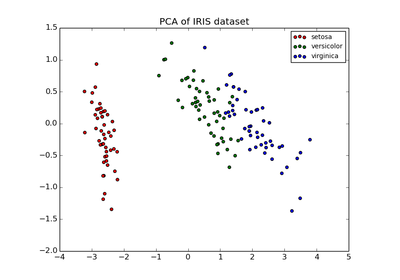
The fitted model can also be used to reduce the dimensionality of the input, by projecting it to the most discriminative directions.
Parameters: n_components: int :
Number of components (< n_classes - 1) for dimensionality reduction
priors : array, optional, shape = [n_classes]
Priors on classes
Attributes: `coef_` : array-like, shape = [rank, n_classes - 1]
Coefficients of the features in the linear decision function. rank is min(rank_features, n_classes) where rank_features is the dimensionality of the spaces spanned by the features (i.e. n_features excluding redundant features).
`covariance_` : array-like, shape = [n_features, n_features]
Covariance matrix (shared by all classes).
`means_` : array-like, shape = [n_classes, n_features]
Class means.
`priors_` : array-like, shape = [n_classes]
Class priors (sum to 1).
`scalings_` : array-like, shape = [rank, n_classes - 1]
Scaling of the features in the space spanned by the class centroids.
`xbar_` : float, shape = [n_features]
Overall mean.
See also
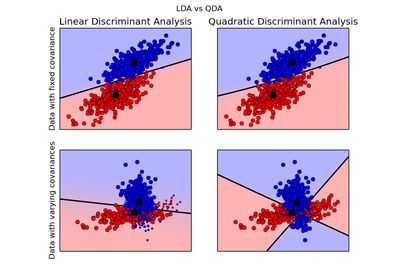
- sklearn.qda.QDA
- Quadratic discriminant analysis
Examples
>>> import numpy as np >>> from sklearn.lda import LDA >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = LDA() >>> clf.fit(X, y) LDA(n_components=None, priors=None) >>> print(clf.predict([[-0.8, -1]])) [1]
Methods
decision_function(X) This function returns the decision function values related to each class on an array of test vectors X. fit(X, y[, store_covariance, tol]) Fit the LDA model according to the given training data and parameters. fit_transform(X[, y]) Fit to data, then transform it. get_params([deep]) Get parameters for this estimator. predict(X) This function does classification on an array of test vectors X. predict_log_proba(X) This function returns posterior log-probabilities of classification according to each class on an array of test vectors X. predict_proba(X) This function returns posterior probabilities of classification according to each class on an array of test vectors X. score(X, y[, sample_weight]) Returns the mean accuracy on the given test data and labels. set_params(**params) Set the parameters of this estimator. transform(X) Project the data so as to maximize class separation (large separation between projected class means and small variance within each class). - __init__(n_components=None, priors=None)¶
- decision_function(X)¶
This function returns the decision function values related to each class on an array of test vectors X.
Parameters: X : array-like, shape = [n_samples, n_features]
Returns: C : array, shape = [n_samples, n_classes] or [n_samples,]
Decision function values related to each class, per sample. In the two-class case, the shape is [n_samples,], giving the log likelihood ratio of the positive class.
- fit(X, y, store_covariance=False, tol=0.0001)¶
Fit the LDA model according to the given training data and parameters.
Parameters: X : array-like, shape = [n_samples, n_features]
Training vector, where n_samples in the number of samples and n_features is the number of features.
y : array, shape = [n_samples]
Target values (integers)
store_covariance : boolean
If True the covariance matrix (shared by all classes) is computed and stored in self.covariance_ attribute.
- fit_transform(X, y=None, **fit_params)¶
Fit to data, then transform it.
Fits transformer to X and y with optional parameters fit_params and returns a transformed version of X.
Parameters: X : numpy array of shape [n_samples, n_features]
Training set.
y : numpy array of shape [n_samples]
Target values.
Returns: X_new : numpy array of shape [n_samples, n_features_new]
Transformed array.
- get_params(deep=True)¶
Get parameters for this estimator.
Parameters: deep: boolean, optional :
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns: params : mapping of string to any
Parameter names mapped to their values.
- predict(X)¶
This function does classification on an array of test vectors X.
The predicted class C for each sample in X is returned.
Parameters: X : array-like, shape = [n_samples, n_features] Returns: C : array, shape = [n_samples]
- predict_log_proba(X)¶
This function returns posterior log-probabilities of classification according to each class on an array of test vectors X.
Parameters: X : array-like, shape = [n_samples, n_features] Returns: C : array, shape = [n_samples, n_classes]
- predict_proba(X)¶
This function returns posterior probabilities of classification according to each class on an array of test vectors X.
Parameters: X : array-like, shape = [n_samples, n_features] Returns: C : array, shape = [n_samples, n_classes]
- score(X, y, sample_weight=None)¶
Returns the mean accuracy on the given test data and labels.
Parameters: X : array-like, shape = (n_samples, n_features)
Test samples.
y : array-like, shape = (n_samples,)
True labels for X.
sample_weight : array-like, shape = [n_samples], optional
Sample weights.
Returns: score : float
Mean accuracy of self.predict(X) wrt. y.
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The former have parameters of the form <component>__<parameter> so that it’s possible to update each component of a nested object.
Returns: self :
- transform(X)¶
Project the data so as to maximize class separation (large separation between projected class means and small variance within each class).
Parameters: X : array-like, shape = [n_samples, n_features] Returns: X_new : array, shape = [n_samples, n_components]