10.1. Strategies to scale computationally: bigger data#
For some applications the amount of examples, features (or both) and/or the speed at which they need to be processed are challenging for traditional approaches. In these cases scikit-learn has a number of options you can consider to make your system scale.
10.1.1. Scaling with instances using out-of-core learning#
Out-of-core (or “external memory”) learning is a technique used to learn from data that cannot fit in a computer’s main memory (RAM).
Here is a sketch of a system designed to achieve this goal:
a way to stream instances
a way to extract features from instances
an incremental algorithm
10.1.1.1. Streaming instances#
Basically, 1. may be a reader that yields instances from files on a hard drive, a database, from a network stream etc. However, details on how to achieve this are beyond the scope of this documentation.
10.1.1.2. Extracting features#
2. could be any relevant way to extract features among the
different feature extraction methods supported by
scikit-learn. However, when working with data that needs vectorization and
where the set of features or values is not known in advance one should take
explicit care. A good example is text classification where unknown terms are
likely to be found during training. It is possible to use a stateful
vectorizer if making multiple passes over the data is reasonable from an
application point of view. Otherwise, one can turn up the difficulty by using
a stateless feature extractor. Currently the preferred way to do this is to
use the so-called hashing trick as implemented by
sklearn.feature_extraction.FeatureHasher for datasets with categorical
variables represented as list of Python dicts or
sklearn.feature_extraction.text.HashingVectorizer for text documents.
10.1.1.3. Incremental learning#
Finally, for 3. we have a number of options inside scikit-learn. Although not
all algorithms can learn incrementally (i.e. without seeing all the instances
at once), all estimators implementing the partial_fit API are candidates.
Actually, the ability to learn incrementally from a mini-batch of instances
(sometimes called “online learning”) is key to out-of-core learning as it
guarantees that at any given time there will be only a small amount of
instances in the main memory. Choosing a good size for the mini-batch that
balances relevancy and memory footprint could involve some tuning [1].
Here is a list of incremental estimators for different tasks:
For classification, a somewhat important thing to note is that although a
stateless feature extraction routine may be able to cope with new/unseen
attributes, the incremental learner itself may be unable to cope with
new/unseen targets classes. In this case you have to pass all the possible
classes to the first partial_fit call using the classes= parameter.
Another aspect to consider when choosing a proper algorithm is that not all of
them put the same importance on each example over time. Namely, the
Perceptron is still sensitive to badly labeled examples even after many
examples whereas the SGD* family is more
robust to this kind of artifacts. Conversely, the latter also tend to give less
importance to remarkably different, yet properly labeled examples when they
come late in the stream as their learning rate decreases over time.
10.1.1.4. Examples#
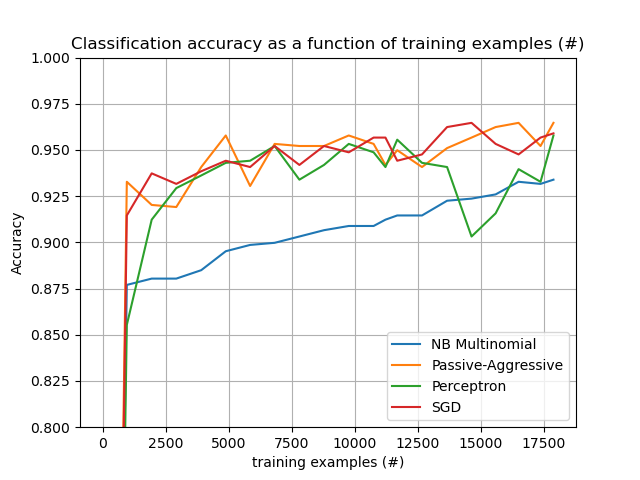
Finally, we have a full-fledged example of Out-of-core classification of text documents. It is aimed at providing a starting point for people wanting to build out-of-core learning systems and demonstrates most of the notions discussed above.
Furthermore, it also shows the evolution of the performance of different algorithms with the number of processed examples.
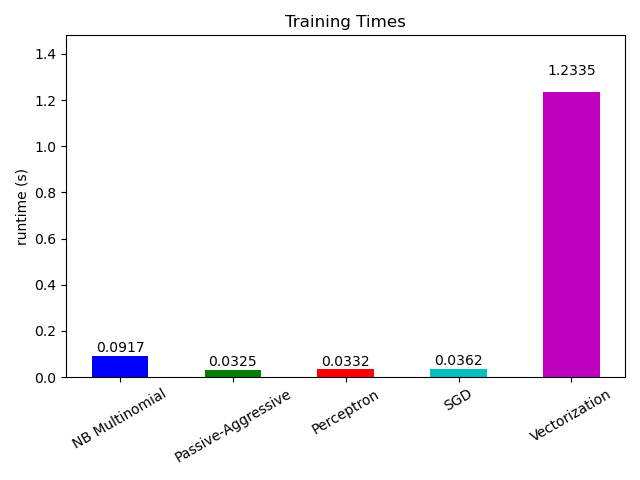
Now looking at the computation time of the different parts, we see that the
vectorization is much more expensive than learning itself. From the different
algorithms, MultinomialNB is the most expensive, but its overhead can be
mitigated by increasing the size of the mini-batches (exercise: change
minibatch_size to 100 and 10000 in the program and compare).