NearestCentroid#
- class sklearn.neighbors.NearestCentroid(metric='euclidean', *, shrink_threshold=None, priors='uniform')[source]#
Nearest centroid classifier.
Each class is represented by its centroid, with test samples classified to the class with the nearest centroid.
Read more in the User Guide.
- Parameters:
- metric{“euclidean”, “manhattan”}, default=”euclidean”
Metric to use for distance computation.
If
metric="euclidean", the centroid for the samples corresponding to each class is the arithmetic mean, which minimizes the sum of squared L1 distances. Ifmetric="manhattan", the centroid is the feature-wise median, which minimizes the sum of L1 distances.Changed in version 1.5: All metrics but
"euclidean"and"manhattan"were deprecated and now raise an error.Changed in version 0.19:
metric='precomputed'was deprecated and now raises an error- shrink_thresholdfloat, default=None
Threshold for shrinking centroids to remove features.
- priors{“uniform”, “empirical”} or array-like of shape (n_classes,), default=”uniform”
The class prior probabilities. By default, the class proportions are inferred from the training data.
Added in version 1.6.
- Attributes:
- centroids_array-like of shape (n_classes, n_features)
Centroid of each class.
- classes_array of shape (n_classes,)
The unique classes labels.
- n_features_in_int
Number of features seen during fit.
Added in version 0.24.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Defined only when
Xhas feature names that are all strings.Added in version 1.0.
- deviations_ndarray of shape (n_classes, n_features)
Deviations (or shrinkages) of the centroids of each class from the overall centroid. Equal to eq. (18.4) if
shrink_threshold=None, else (18.5) p. 653 of [2]. Can be used to identify features used for classification.Added in version 1.6.
- within_class_std_dev_ndarray of shape (n_features,)
Pooled or within-class standard deviation of input data.
Added in version 1.6.
- class_prior_ndarray of shape (n_classes,)
The class prior probabilities.
Added in version 1.6.
See also
KNeighborsClassifierNearest neighbors classifier.
Notes
When used for text classification with tf-idf vectors, this classifier is also known as the Rocchio classifier.
References
[1] Tibshirani, R., Hastie, T., Narasimhan, B., & Chu, G. (2002). Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proceedings of the National Academy of Sciences of the United States of America, 99(10), 6567-6572. The National Academy of Sciences.
[2] Hastie, T., Tibshirani, R., Friedman, J. (2009). The Elements of Statistical Learning Data Mining, Inference, and Prediction. 2nd Edition. New York, Springer.
Examples
>>> from sklearn.neighbors import NearestCentroid >>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = NearestCentroid() >>> clf.fit(X, y) NearestCentroid() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[source]#
Apply decision function to an array of samples.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
Array of samples (test vectors).
- Returns:
- y_scoresndarray of shape (n_samples,) or (n_samples, n_classes)
Decision function values related to each class, per sample. In the two-class case, the shape is
(n_samples,), giving the log likelihood ratio of the positive class.
- fit(X, y)[source]#
Fit the NearestCentroid model according to the given training data.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
Training vector, where
n_samplesis the number of samples andn_featuresis the number of features. Note that centroid shrinking cannot be used with sparse matrices.- yarray-like of shape (n_samples,)
Target values.
- Returns:
- selfobject
Fitted estimator.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- predict(X)[source]#
Perform classification on an array of test vectors
X.The predicted class
Cfor each sample inXis returned.- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
Input data.
- Returns:
- y_predndarray of shape (n_samples,)
The predicted classes.
- predict_log_proba(X)[source]#
Estimate log class probabilities.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
Input data.
- Returns:
- y_log_probandarray of shape (n_samples, n_classes)
Estimated log probabilities.
- predict_proba(X)[source]#
Estimate class probabilities.
- Parameters:
- X{array-like, sparse matrix} of shape (n_samples, n_features)
Input data.
- Returns:
- y_probandarray of shape (n_samples, n_classes)
Probability estimate of the sample for each class in the model, where classes are ordered as they are in
self.classes_.
- score(X, y, sample_weight=None)[source]#
Return the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True labels for
X.- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
Mean accuracy of
self.predict(X)w.r.t.y.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') NearestCentroid[source]#
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
Gallery examples#
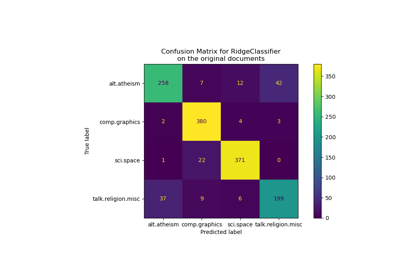
Classification of text documents using sparse features