ValidationCurveDisplay#
- class sklearn.model_selection.ValidationCurveDisplay(*, param_name, param_range, train_scores, test_scores, score_name=None)[source]#
Validation Curve visualization.
It is recommended to use
from_estimatorto create aValidationCurveDisplayinstance. All parameters are stored as attributes.Read more in the User Guide for general information about the visualization API and detailed documentation regarding the validation curve visualization.
Added in version 1.3.
- Parameters:
- param_namestr
Name of the parameter that has been varied.
- param_rangearray-like of shape (n_ticks,)
The values of the parameter that have been evaluated.
- train_scoresndarray of shape (n_ticks, n_cv_folds)
Scores on training sets.
- test_scoresndarray of shape (n_ticks, n_cv_folds)
Scores on test set.
- score_namestr, default=None
The name of the score used in
validation_curve. It will override the name inferred from thescoringparameter. IfscoreisNone, we use"Score"ifnegate_scoreisFalseand"Negative score"otherwise. Ifscoringis a string or a callable, we infer the name. We replace_by spaces and capitalize the first letter. We removeneg_and replace it by"Negative"ifnegate_scoreisFalseor just remove it otherwise.
- Attributes:
- ax_matplotlib Axes
Axes with the validation curve.
- figure_matplotlib Figure
Figure containing the validation curve.
- errorbar_list of matplotlib Artist or None
When the
std_display_styleis"errorbar", this is a list ofmatplotlib.container.ErrorbarContainerobjects. If another style is used,errorbar_isNone.- lines_list of matplotlib Artist or None
When the
std_display_styleis"fill_between", this is a list ofmatplotlib.lines.Line2Dobjects corresponding to the mean train and test scores. If another style is used,line_isNone.- fill_between_list of matplotlib Artist or None
When the
std_display_styleis"fill_between", this is a list ofmatplotlib.collections.PolyCollectionobjects. If another style is used,fill_between_isNone.
See also
sklearn.model_selection.validation_curveCompute the validation curve.
Examples
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import ValidationCurveDisplay, validation_curve >>> from sklearn.linear_model import LogisticRegression >>> X, y = make_classification(n_samples=1_000, random_state=0) >>> logistic_regression = LogisticRegression() >>> param_name, param_range = "C", np.logspace(-8, 3, 10) >>> train_scores, test_scores = validation_curve( ... logistic_regression, X, y, param_name=param_name, param_range=param_range ... ) >>> display = ValidationCurveDisplay( ... param_name=param_name, param_range=param_range, ... train_scores=train_scores, test_scores=test_scores, score_name="Score" ... ) >>> display.plot() <...> >>> plt.show()
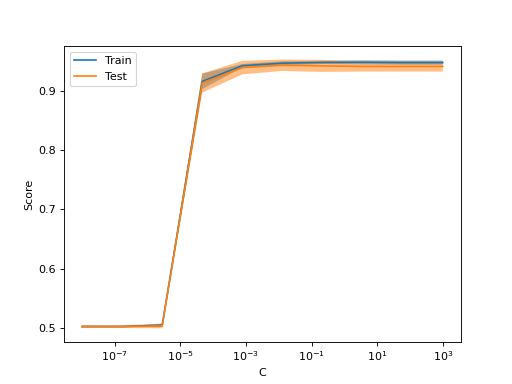
- classmethod from_estimator(estimator, X, y, *, param_name, param_range, groups=None, cv=None, scoring=None, n_jobs=None, pre_dispatch='all', verbose=0, error_score=nan, fit_params=None, ax=None, negate_score=False, score_name=None, score_type='both', std_display_style='fill_between', line_kw=None, fill_between_kw=None, errorbar_kw=None)[source]#
Create a validation curve display from an estimator.
Read more in the User Guide for general information about the visualization API and detailed documentation regarding the validation curve visualization.
- Parameters:
- estimatorobject type that implements the “fit” and “predict” methods
An object of that type which is cloned for each validation.
- Xarray-like of shape (n_samples, n_features)
Training data, where
n_samplesis the number of samples andn_featuresis the number of features.- yarray-like of shape (n_samples,) or (n_samples, n_outputs) or None
Target relative to X for classification or regression; None for unsupervised learning.
- param_namestr
Name of the parameter that will be varied.
- param_rangearray-like of shape (n_values,)
The values of the parameter that will be evaluated.
- groupsarray-like of shape (n_samples,), default=None
Group labels for the samples used while splitting the dataset into train/test set. Only used in conjunction with a “Group” cv instance (e.g.,
GroupKFold).- cvint, cross-validation generator or an iterable, default=None
Determines the cross-validation splitting strategy. Possible inputs for cv are:
None, to use the default 5-fold cross validation,
int, to specify the number of folds in a
(Stratified)KFold,An iterable yielding (train, test) splits as arrays of indices.
For int/None inputs, if the estimator is a classifier and
yis either binary or multiclass,StratifiedKFoldis used. In all other cases,KFoldis used. These splitters are instantiated withshuffle=Falseso the splits will be the same across calls.Refer User Guide for the various cross-validation strategies that can be used here.
- scoringstr or callable, default=None
A string (see The scoring parameter: defining model evaluation rules) or a scorer callable object / function with signature
scorer(estimator, X, y)(see Callable scorers).- n_jobsint, default=None
Number of jobs to run in parallel. Training the estimator and computing the score are parallelized over the different training and test sets.
Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors. See Glossary for more details.- pre_dispatchint or str, default=’all’
Number of predispatched jobs for parallel execution (default is all). The option can reduce the allocated memory. The str can be an expression like ‘2*n_jobs’.
- verboseint, default=0
Controls the verbosity: the higher, the more messages.
- error_score‘raise’ or numeric, default=np.nan
Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised. If a numeric value is given, FitFailedWarning is raised.
- fit_paramsdict, default=None
Parameters to pass to the fit method of the estimator.
- axmatplotlib Axes, default=None
Axes object to plot on. If
None, a new figure and axes is created.- negate_scorebool, default=False
Whether or not to negate the scores obtained through
validation_curve. This is particularly useful when using the error denoted byneg_*inscikit-learn.- score_namestr, default=None
The name of the score used to decorate the y-axis of the plot. It will override the name inferred from the
scoringparameter. IfscoreisNone, we use"Score"ifnegate_scoreisFalseand"Negative score"otherwise. Ifscoringis a string or a callable, we infer the name. We replace_by spaces and capitalize the first letter. We removeneg_and replace it by"Negative"ifnegate_scoreisFalseor just remove it otherwise.- score_type{“test”, “train”, “both”}, default=”both”
The type of score to plot. Can be one of
"test","train", or"both".- std_display_style{“errorbar”, “fill_between”} or None, default=”fill_between”
The style used to display the score standard deviation around the mean score. If
None, no representation of the standard deviation is displayed.- line_kwdict, default=None
Additional keyword arguments passed to the
plt.plotused to draw the mean score.- fill_between_kwdict, default=None
Additional keyword arguments passed to the
plt.fill_betweenused to draw the score standard deviation.- errorbar_kwdict, default=None
Additional keyword arguments passed to the
plt.errorbarused to draw mean score and standard deviation score.
- Returns:
- display
ValidationCurveDisplay Object that stores computed values.
- display
Examples
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import ValidationCurveDisplay >>> from sklearn.linear_model import LogisticRegression >>> X, y = make_classification(n_samples=1_000, random_state=0) >>> logistic_regression = LogisticRegression() >>> param_name, param_range = "C", np.logspace(-8, 3, 10) >>> ValidationCurveDisplay.from_estimator( ... logistic_regression, X, y, param_name=param_name, ... param_range=param_range, ... ) <...> >>> plt.show()
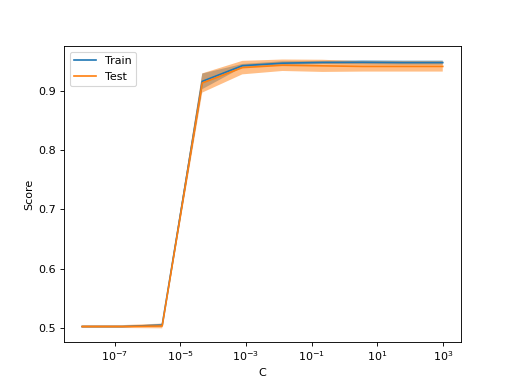
- plot(ax=None, *, negate_score=False, score_name=None, score_type='both', std_display_style='fill_between', line_kw=None, fill_between_kw=None, errorbar_kw=None)[source]#
Plot visualization.
- Parameters:
- axmatplotlib Axes, default=None
Axes object to plot on. If
None, a new figure and axes is created.- negate_scorebool, default=False
Whether or not to negate the scores obtained through
validation_curve. This is particularly useful when using the error denoted byneg_*inscikit-learn.- score_namestr, default=None
The name of the score used to decorate the y-axis of the plot. It will override the name inferred from the
scoringparameter. IfscoreisNone, we use"Score"ifnegate_scoreisFalseand"Negative score"otherwise. Ifscoringis a string or a callable, we infer the name. We replace_by spaces and capitalize the first letter. We removeneg_and replace it by"Negative"ifnegate_scoreisFalseor just remove it otherwise.- score_type{“test”, “train”, “both”}, default=”both”
The type of score to plot. Can be one of
"test","train", or"both".- std_display_style{“errorbar”, “fill_between”} or None, default=”fill_between”
The style used to display the score standard deviation around the mean score. If None, no standard deviation representation is displayed.
- line_kwdict, default=None
Additional keyword arguments passed to the
plt.plotused to draw the mean score.- fill_between_kwdict, default=None
Additional keyword arguments passed to the
plt.fill_betweenused to draw the score standard deviation.- errorbar_kwdict, default=None
Additional keyword arguments passed to the
plt.errorbarused to draw mean score and standard deviation score.
- Returns:
- display
ValidationCurveDisplay Object that stores computed values.
- display
Gallery examples#
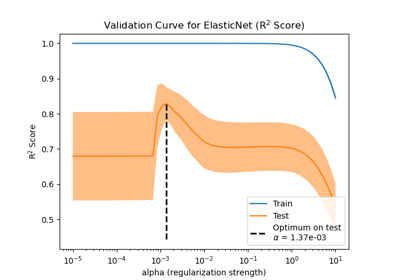
Effect of model regularization on training and test error
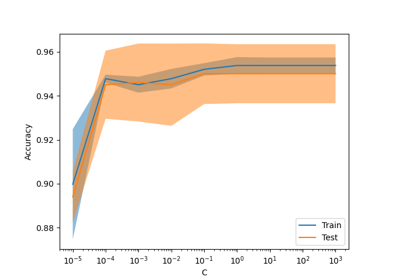
Effect of model regularization on training and test error