Approximate nearest neighbors in TSNE#
This example presents how to chain KNeighborsTransformer and TSNE in a pipeline.
It also shows how to wrap the packages nmslib and pynndescent to replace
KNeighborsTransformer and perform approximate nearest neighbors. These packages
can be installed with pip install nmslib pynndescent.
Note: In KNeighborsTransformer we use the definition which includes each
training point as its own neighbor in the count of n_neighbors, and for
compatibility reasons, one extra neighbor is computed when mode == 'distance'.
Please note that we do the same in the proposed nmslib wrapper.
# Author: Tom Dupre la Tour
# License: BSD 3 clause
First we try to import the packages and warn the user in case they are missing.
We define a wrapper class for implementing the scikit-learn API to the
nmslib, as well as a loading function.
import joblib
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
class NMSlibTransformer(TransformerMixin, BaseEstimator):
"""Wrapper for using nmslib as sklearn's KNeighborsTransformer"""
def __init__(self, n_neighbors=5, metric="euclidean", method="sw-graph", n_jobs=-1):
self.n_neighbors = n_neighbors
self.method = method
self.metric = metric
self.n_jobs = n_jobs
def fit(self, X):
self.n_samples_fit_ = X.shape[0]
# see more metric in the manual
# https://github.com/nmslib/nmslib/tree/master/manual
space = {
"euclidean": "l2",
"cosine": "cosinesimil",
"l1": "l1",
"l2": "l2",
}[self.metric]
self.nmslib_ = nmslib.init(method=self.method, space=space)
self.nmslib_.addDataPointBatch(X.copy())
self.nmslib_.createIndex()
return self
def transform(self, X):
n_samples_transform = X.shape[0]
# For compatibility reasons, as each sample is considered as its own
# neighbor, one extra neighbor will be computed.
n_neighbors = self.n_neighbors + 1
if self.n_jobs < 0:
# Same handling as done in joblib for negative values of n_jobs:
# in particular, `n_jobs == -1` means "as many threads as CPUs".
num_threads = joblib.cpu_count() + self.n_jobs + 1
else:
num_threads = self.n_jobs
results = self.nmslib_.knnQueryBatch(
X.copy(), k=n_neighbors, num_threads=num_threads
)
indices, distances = zip(*results)
indices, distances = np.vstack(indices), np.vstack(distances)
indptr = np.arange(0, n_samples_transform * n_neighbors + 1, n_neighbors)
kneighbors_graph = csr_matrix(
(distances.ravel(), indices.ravel(), indptr),
shape=(n_samples_transform, self.n_samples_fit_),
)
return kneighbors_graph
def load_mnist(n_samples):
"""Load MNIST, shuffle the data, and return only n_samples."""
mnist = fetch_openml("mnist_784", as_frame=False)
X, y = shuffle(mnist.data, mnist.target, random_state=2)
return X[:n_samples] / 255, y[:n_samples]
We benchmark the different exact/approximate nearest neighbors transformers.
import time
from sklearn.manifold import TSNE
from sklearn.neighbors import KNeighborsTransformer
from sklearn.pipeline import make_pipeline
datasets = [
("MNIST_10000", load_mnist(n_samples=10_000)),
("MNIST_20000", load_mnist(n_samples=20_000)),
]
n_iter = 500
perplexity = 30
metric = "euclidean"
# TSNE requires a certain number of neighbors which depends on the
# perplexity parameter.
# Add one since we include each sample as its own neighbor.
n_neighbors = int(3.0 * perplexity + 1) + 1
tsne_params = dict(
init="random", # pca not supported for sparse matrices
perplexity=perplexity,
method="barnes_hut",
random_state=42,
n_iter=n_iter,
learning_rate="auto",
)
transformers = [
(
"KNeighborsTransformer",
KNeighborsTransformer(n_neighbors=n_neighbors, mode="distance", metric=metric),
),
(
"NMSlibTransformer",
NMSlibTransformer(n_neighbors=n_neighbors, metric=metric),
),
(
"PyNNDescentTransformer",
PyNNDescentTransformer(
n_neighbors=n_neighbors, metric=metric, parallel_batch_queries=True
),
),
]
for dataset_name, (X, y) in datasets:
msg = f"Benchmarking on {dataset_name}:"
print(f"\n{msg}\n" + str("-" * len(msg)))
for transformer_name, transformer in transformers:
longest = np.max([len(name) for name, model in transformers])
start = time.time()
transformer.fit(X)
fit_duration = time.time() - start
print(f"{transformer_name:<{longest}} {fit_duration:.3f} sec (fit)")
start = time.time()
Xt = transformer.transform(X)
transform_duration = time.time() - start
print(f"{transformer_name:<{longest}} {transform_duration:.3f} sec (transform)")
if transformer_name == "PyNNDescentTransformer":
start = time.time()
Xt = transformer.transform(X)
transform_duration = time.time() - start
print(
f"{transformer_name:<{longest}} {transform_duration:.3f} sec"
" (transform)"
)
Sample output:
Benchmarking on MNIST_10000:
----------------------------
KNeighborsTransformer 0.007 sec (fit)
KNeighborsTransformer 1.139 sec (transform)
NMSlibTransformer 0.208 sec (fit)
NMSlibTransformer 0.315 sec (transform)
PyNNDescentTransformer 4.823 sec (fit)
PyNNDescentTransformer 4.884 sec (transform)
PyNNDescentTransformer 0.744 sec (transform)
Benchmarking on MNIST_20000:
----------------------------
KNeighborsTransformer 0.011 sec (fit)
KNeighborsTransformer 5.769 sec (transform)
NMSlibTransformer 0.733 sec (fit)
NMSlibTransformer 1.077 sec (transform)
PyNNDescentTransformer 14.448 sec (fit)
PyNNDescentTransformer 7.103 sec (transform)
PyNNDescentTransformer 1.759 sec (transform)
Notice that the PyNNDescentTransformer takes more time during the first
fit and the first transform due to the overhead of the numba just in time
compiler. But after the first call, the compiled Python code is kept in a
cache by numba and subsequent calls do not suffer from this initial overhead.
Both KNeighborsTransformer and NMSlibTransformer
are only run once here as they would show more stable fit and transform
times (they don’t have the cold start problem of PyNNDescentTransformer).
import matplotlib.pyplot as plt
from matplotlib.ticker import NullFormatter
transformers = [
("TSNE with internal NearestNeighbors", TSNE(metric=metric, **tsne_params)),
(
"TSNE with KNeighborsTransformer",
make_pipeline(
KNeighborsTransformer(
n_neighbors=n_neighbors, mode="distance", metric=metric
),
TSNE(metric="precomputed", **tsne_params),
),
),
(
"TSNE with NMSlibTransformer",
make_pipeline(
NMSlibTransformer(n_neighbors=n_neighbors, metric=metric),
TSNE(metric="precomputed", **tsne_params),
),
),
]
# init the plot
nrows = len(datasets)
ncols = np.sum([1 for name, model in transformers if "TSNE" in name])
fig, axes = plt.subplots(
nrows=nrows, ncols=ncols, squeeze=False, figsize=(5 * ncols, 4 * nrows)
)
axes = axes.ravel()
i_ax = 0
for dataset_name, (X, y) in datasets:
msg = f"Benchmarking on {dataset_name}:"
print(f"\n{msg}\n" + str("-" * len(msg)))
for transformer_name, transformer in transformers:
longest = np.max([len(name) for name, model in transformers])
start = time.time()
Xt = transformer.fit_transform(X)
transform_duration = time.time() - start
print(
f"{transformer_name:<{longest}} {transform_duration:.3f} sec"
" (fit_transform)"
)
# plot TSNE embedding which should be very similar across methods
axes[i_ax].set_title(transformer_name + "\non " + dataset_name)
axes[i_ax].scatter(
Xt[:, 0],
Xt[:, 1],
c=y.astype(np.int32),
alpha=0.2,
cmap=plt.cm.viridis,
)
axes[i_ax].xaxis.set_major_formatter(NullFormatter())
axes[i_ax].yaxis.set_major_formatter(NullFormatter())
axes[i_ax].axis("tight")
i_ax += 1
fig.tight_layout()
plt.show()
Sample output:
Benchmarking on MNIST_10000:
----------------------------
TSNE with internal NearestNeighbors 24.828 sec (fit_transform)
TSNE with KNeighborsTransformer 20.111 sec (fit_transform)
TSNE with NMSlibTransformer 21.757 sec (fit_transform)
Benchmarking on MNIST_20000:
----------------------------
TSNE with internal NearestNeighbors 51.955 sec (fit_transform)
TSNE with KNeighborsTransformer 50.994 sec (fit_transform)
TSNE with NMSlibTransformer 43.536 sec (fit_transform)
We can observe that the default TSNE estimator with
its internal NearestNeighbors implementation is
roughly equivalent to the pipeline with TSNE and
KNeighborsTransformer in terms of performance.
This is expected because both pipelines rely internally on the same
NearestNeighbors implementation that performs
exacts neighbors search. The approximate NMSlibTransformer is already
slightly faster than the exact search on the smallest dataset but this speed
difference is expected to become more significant on datasets with a larger
number of samples.
Notice however that not all approximate search methods are guaranteed to
improve the speed of the default exact search method: indeed the exact search
implementation significantly improved since scikit-learn 1.1. Furthermore, the
brute-force exact search method does not require building an index at fit
time. So, to get an overall performance improvement in the context of the
TSNE pipeline, the gains of the approximate search
at transform need to be larger than the extra time spent to build the
approximate search index at fit time.
Finally, the TSNE algorithm itself is also computationally intensive, irrespective of the nearest neighbors search. So speeding-up the nearest neighbors search step by a factor of 5 would not result in a speed up by a factor of 5 for the overall pipeline.
Related examples

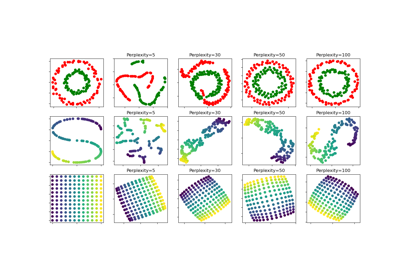
t-SNE: The effect of various perplexity values on the shape