7.3. Generated datasets#
In addition, scikit-learn includes various random sample generators that can be used to build artificial datasets of controlled size and complexity.
7.3.1. Generators for classification and clustering#
These generators produce a matrix of features and corresponding discrete targets.
7.3.1.1. Single label#
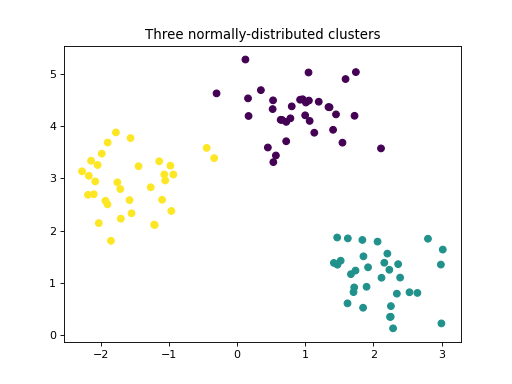
make_blobs creates a multiclass dataset by allocating each class to one
normally-distributed cluster of points. It provides control over the centers and
standard deviations of each cluster. This dataset is used to demonstrate clustering.
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=3, cluster_std=0.5, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title("Three normally-distributed clusters")
plt.show()
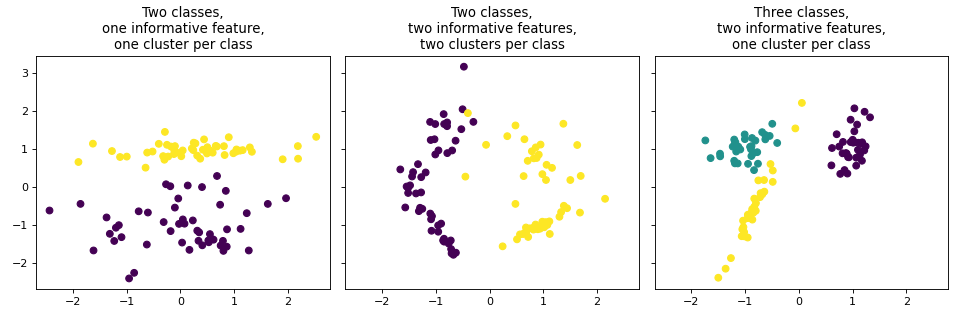
make_classification also creates multiclass datasets but specializes in
introducing noise by way of: correlated, redundant and uninformative features; multiple
Gaussian clusters per class; and linear transformations of the feature space.
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True, sharex=True)
titles = ["Two classes,\none informative feature,\none cluster per class",
"Two classes,\ntwo informative features,\ntwo clusters per class",
"Three classes,\ntwo informative features,\none cluster per class"]
params = [
{"n_informative": 1, "n_clusters_per_class": 1, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 2, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 1, "n_classes": 3}
]
for i, param in enumerate(params):
X, Y = make_classification(n_features=2, n_redundant=0, random_state=1, **param)
axs[i].scatter(X[:, 0], X[:, 1], c=Y)
axs[i].set_title(titles[i])
plt.tight_layout()
plt.show()
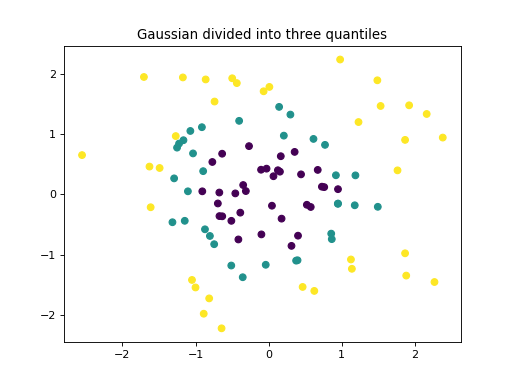
make_gaussian_quantiles divides a single Gaussian cluster into
near-equal-size classes separated by concentric hyperspheres.
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
X, Y = make_gaussian_quantiles(n_features=2, n_classes=3, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.title("Gaussian divided into three quantiles")
plt.show()
make_hastie_10_2 generates a similar binary, 10-dimensional problem.
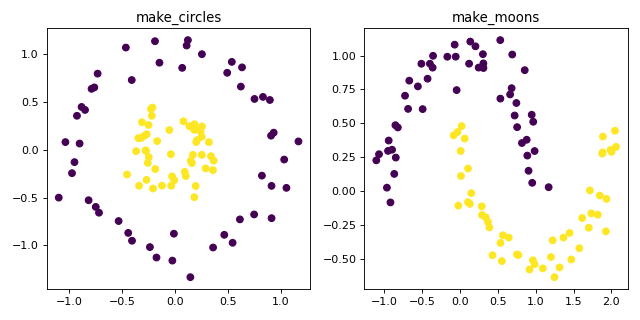
make_circles and make_moons generate 2D binary classification
datasets that are challenging to certain algorithms (e.g., centroid-based
clustering or linear classification), including optional Gaussian noise.
They are useful for visualization. make_circles produces Gaussian data
with a spherical decision boundary for binary classification, while
make_moons produces two interleaving half-circles.
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_moons
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
X, Y = make_circles(noise=0.1, factor=0.3, random_state=0)
ax1.scatter(X[:, 0], X[:, 1], c=Y)
ax1.set_title("make_circles")
X, Y = make_moons(noise=0.1, random_state=0)
ax2.scatter(X[:, 0], X[:, 1], c=Y)
ax2.set_title("make_moons")
plt.tight_layout()
plt.show()
7.3.1.2. Multilabel#
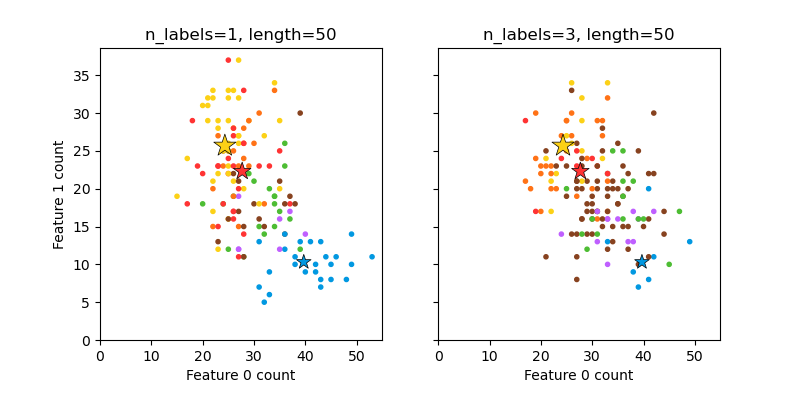
make_multilabel_classification generates random samples with multiple
labels, reflecting a bag of words drawn from a mixture of topics. The number of
topics for each document is drawn from a Poisson distribution, and the topics
themselves are drawn from a fixed random distribution. Similarly, the number of
words is drawn from Poisson, with words drawn from a multinomial, where each
topic defines a probability distribution over words. Simplifications with
respect to true bag-of-words mixtures include:
Per-topic word distributions are independently drawn, where in reality all would be affected by a sparse base distribution, and would be correlated.
For a document generated from multiple topics, all topics are weighted equally in generating its bag of words.
Documents without labels words at random, rather than from a base distribution.
7.3.1.3. Biclustering#
|
Generate a constant block diagonal structure array for biclustering. |
|
Generate an array with block checkerboard structure for biclustering. |
7.3.2. Generators for regression#
make_regression produces regression targets as an optionally-sparse
random linear combination of random features, with noise. Its informative
features may be uncorrelated, or low rank (few features account for most of the
variance).
Other regression generators generate functions deterministically from
randomized features. make_sparse_uncorrelated produces a target as a
linear combination of four features with fixed coefficients.
Others encode explicitly non-linear relations:
make_friedman1 is related by polynomial and sine transforms;
make_friedman2 includes feature multiplication and reciprocation; and
make_friedman3 is similar with an arctan transformation on the target.
7.3.3. Generators for manifold learning#
|
Generate an S curve dataset. |
|
Generate a swiss roll dataset. |
7.3.4. Generators for decomposition#
|
Generate a mostly low rank matrix with bell-shaped singular values. |
|
Generate a signal as a sparse combination of dictionary elements. |
|
Generate a random symmetric, positive-definite matrix. |
|
Generate a sparse symmetric definite positive matrix. |