Note
Click here to download the full example code or to run this example in your browser via Binder
Importance of Feature Scaling¶
Feature scaling through standardization (or Z-score normalization) can be an important preprocessing step for many machine learning algorithms. Standardization involves rescaling the features such that they have the properties of a standard normal distribution with a mean of zero and a standard deviation of one.
While many algorithms (such as SVM, K-nearest neighbors, and logistic regression) require features to be normalized, intuitively we can think of Principle Component Analysis (PCA) as being a prime example of when normalization is important. In PCA we are interested in the components that maximize the variance. If one component (e.g. human height) varies less than another (e.g. weight) because of their respective scales (meters vs. kilos), PCA might determine that the direction of maximal variance more closely corresponds with the ‘weight’ axis, if those features are not scaled. As a change in height of one meter can be considered much more important than the change in weight of one kilogram, this is clearly incorrect.
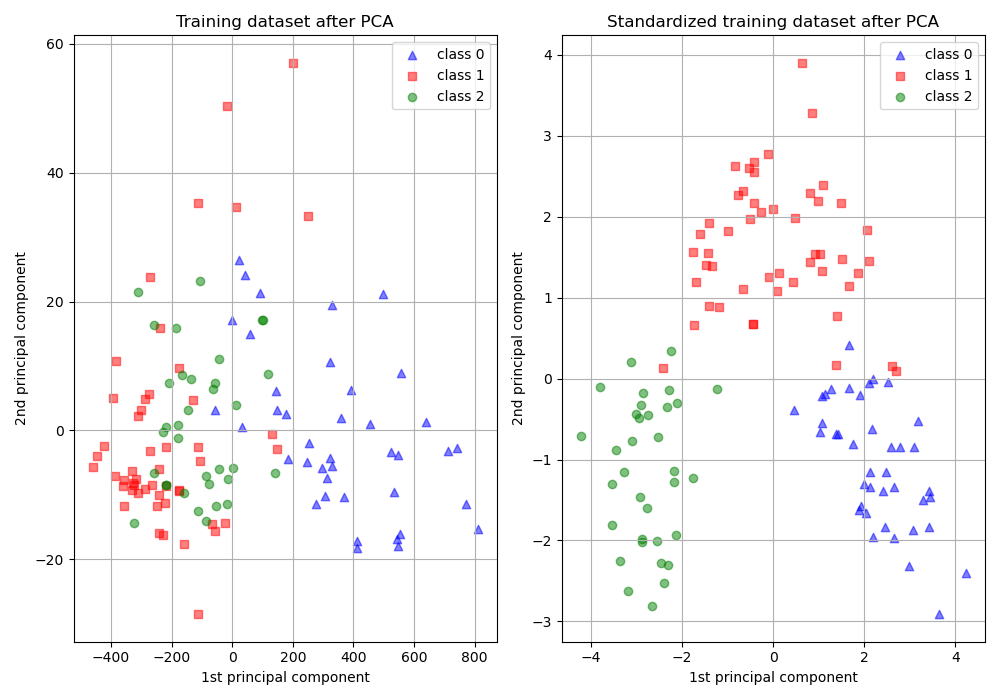
To illustrate this, PCA is performed comparing the use of data with
StandardScaler applied,
to unscaled data. The results are visualized and a clear difference noted.
The 1st principal component in the unscaled set can be seen. It can be seen
that feature #13 dominates the direction, being a whole two orders of
magnitude above the other features. This is contrasted when observing
the principal component for the scaled version of the data. In the scaled
version, the orders of magnitude are roughly the same across all the features.
The dataset used is the Wine Dataset available at UCI. This dataset has continuous features that are heterogeneous in scale due to differing properties that they measure (i.e alcohol content, and malic acid).
The transformed data is then used to train a naive Bayes classifier, and a clear difference in prediction accuracies is observed wherein the dataset which is scaled before PCA vastly outperforms the unscaled version.
Out:
Prediction accuracy for the normal test dataset with PCA
81.48%
Prediction accuracy for the standardized test dataset with PCA
98.15%
PC 1 without scaling:
[ 1.76e-03 -8.36e-04 1.55e-04 -5.31e-03 2.02e-02 1.02e-03 1.53e-03
-1.12e-04 6.31e-04 2.33e-03 1.54e-04 7.43e-04 1.00e+00]
PC 1 with scaling:
[ 0.13 -0.26 -0.01 -0.23 0.16 0.39 0.42 -0.28 0.33 -0.11 0.3 0.38
0.28]
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.pipeline import make_pipeline
print(__doc__)
# Code source: Tyler Lanigan <tylerlanigan@gmail.com>
# Sebastian Raschka <mail@sebastianraschka.com>
# License: BSD 3 clause
RANDOM_STATE = 42
FIG_SIZE = (10, 7)
features, target = load_wine(return_X_y=True)
# Make a train/test split using 30% test size
X_train, X_test, y_train, y_test = train_test_split(features, target,
test_size=0.30,
random_state=RANDOM_STATE)
# Fit to data and predict using pipelined GNB and PCA.
unscaled_clf = make_pipeline(PCA(n_components=2), GaussianNB())
unscaled_clf.fit(X_train, y_train)
pred_test = unscaled_clf.predict(X_test)
# Fit to data and predict using pipelined scaling, GNB and PCA.
std_clf = make_pipeline(StandardScaler(), PCA(n_components=2), GaussianNB())
std_clf.fit(X_train, y_train)
pred_test_std = std_clf.predict(X_test)
# Show prediction accuracies in scaled and unscaled data.
print('\nPrediction accuracy for the normal test dataset with PCA')
print('{:.2%}\n'.format(metrics.accuracy_score(y_test, pred_test)))
print('\nPrediction accuracy for the standardized test dataset with PCA')
print('{:.2%}\n'.format(metrics.accuracy_score(y_test, pred_test_std)))
# Extract PCA from pipeline
pca = unscaled_clf.named_steps['pca']
pca_std = std_clf.named_steps['pca']
# Show first principal components
print('\nPC 1 without scaling:\n', pca.components_[0])
print('\nPC 1 with scaling:\n', pca_std.components_[0])
# Use PCA without and with scale on X_train data for visualization.
X_train_transformed = pca.transform(X_train)
scaler = std_clf.named_steps['standardscaler']
X_train_std_transformed = pca_std.transform(scaler.transform(X_train))
# visualize standardized vs. untouched dataset with PCA performed
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=FIG_SIZE)
for l, c, m in zip(range(0, 3), ('blue', 'red', 'green'), ('^', 's', 'o')):
ax1.scatter(X_train_transformed[y_train == l, 0],
X_train_transformed[y_train == l, 1],
color=c,
label='class %s' % l,
alpha=0.5,
marker=m
)
for l, c, m in zip(range(0, 3), ('blue', 'red', 'green'), ('^', 's', 'o')):
ax2.scatter(X_train_std_transformed[y_train == l, 0],
X_train_std_transformed[y_train == l, 1],
color=c,
label='class %s' % l,
alpha=0.5,
marker=m
)
ax1.set_title('Training dataset after PCA')
ax2.set_title('Standardized training dataset after PCA')
for ax in (ax1, ax2):
ax.set_xlabel('1st principal component')
ax.set_ylabel('2nd principal component')
ax.legend(loc='upper right')
ax.grid()
plt.tight_layout()
plt.show()
Total running time of the script: ( 0 minutes 0.322 seconds)