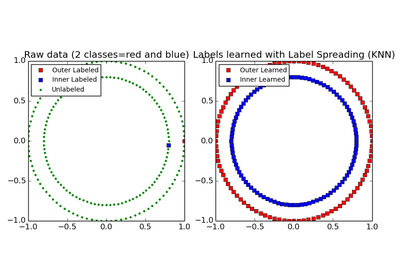
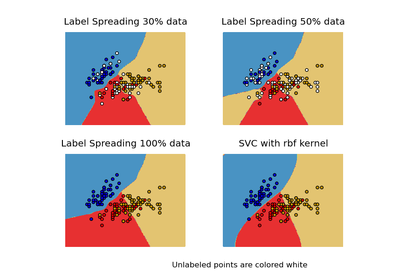
sklearn.semi_supervised.LabelSpreading¶
- class sklearn.semi_supervised.LabelSpreading(kernel='rbf', gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001)¶
LabelSpreading model for semi-supervised learning
This model is similar to the basic Label Propgation algorithm, but uses affinity matrix based on the normalized graph Laplacian and soft clamping across the labels.
Parameters: kernel : {‘knn’, ‘rbf’}
String identifier for kernel function to use. Only ‘rbf’ and ‘knn’ kernels are currently supported.
gamma : float
parameter for rbf kernel
n_neighbors : integer > 0
parameter for knn kernel
alpha : float
clamping factor
max_iter : float
maximum number of iterations allowed
tol : float
Convergence tolerance: threshold to consider the system at steady state
Attributes: `X_` : array, shape = [n_samples, n_features]
Input array.
`classes_` : array, shape = [n_classes]
The distinct labels used in classifying instances.
`label_distributions_` : array, shape = [n_samples, n_classes]
Categorical distribution for each item.
`transduction_` : array, shape = [n_samples]
Label assigned to each item via the transduction.
See also
- LabelPropagation
- Unregularized graph based semi-supervised learning
References
Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, Bernhard Schoelkopf. Learning with local and global consistency (2004) http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.115.3219
Examples
>>> from sklearn import datasets >>> from sklearn.semi_supervised import LabelSpreading >>> label_prop_model = LabelSpreading() >>> iris = datasets.load_iris() >>> random_unlabeled_points = np.where(np.random.random_integers(0, 1, ... size=len(iris.target))) >>> labels = np.copy(iris.target) >>> labels[random_unlabeled_points] = -1 >>> label_prop_model.fit(iris.data, labels) ... LabelSpreading(...)
Methods
fit(X, y) Fit a semi-supervised label propagation model based get_params([deep]) Get parameters for this estimator. predict(X) Performs inductive inference across the model. predict_proba(X) Predict probability for each possible outcome. score(X, y[, sample_weight]) Returns the mean accuracy on the given test data and labels. set_params(**params) Set the parameters of this estimator. - __init__(kernel='rbf', gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001)¶
- fit(X, y)¶
Fit a semi-supervised label propagation model based
All the input data is provided matrix X (labeled and unlabeled) and corresponding label matrix y with a dedicated marker value for unlabeled samples.
Parameters: X : array-like, shape = [n_samples, n_features]
A {n_samples by n_samples} size matrix will be created from this
y : array_like, shape = [n_samples]
n_labeled_samples (unlabeled points are marked as -1) All unlabeled samples will be transductively assigned labels
Returns: self : returns an instance of self.
- get_params(deep=True)¶
Get parameters for this estimator.
Parameters: deep: boolean, optional :
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns: params : mapping of string to any
Parameter names mapped to their values.
- predict(X)¶
Performs inductive inference across the model.
Parameters: X : array_like, shape = [n_samples, n_features]
Returns: y : array_like, shape = [n_samples]
Predictions for input data
- predict_proba(X)¶
Predict probability for each possible outcome.
Compute the probability estimates for each single sample in X and each possible outcome seen during training (categorical distribution).
Parameters: X : array_like, shape = [n_samples, n_features]
Returns: probabilities : array, shape = [n_samples, n_classes]
Normalized probability distributions across class labels
- score(X, y, sample_weight=None)¶
Returns the mean accuracy on the given test data and labels.
Parameters: X : array-like, shape = (n_samples, n_features)
Test samples.
y : array-like, shape = (n_samples,)
True labels for X.
sample_weight : array-like, shape = [n_samples], optional
Sample weights.
Returns: score : float
Mean accuracy of self.predict(X) wrt. y.
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The former have parameters of the form <component>__<parameter> so that it’s possible to update each component of a nested object.
Returns: self :