sklearn.feature_extraction.text.HashingVectorizer¶
- class sklearn.feature_extraction.text.HashingVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern='(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), analyzer='word', n_features=1048576, binary=False, norm='l2', alternate_sign=True, dtype=<class 'numpy.float64'>)[source]¶
Convert a collection of text documents to a matrix of token occurrences.
It turns a collection of text documents into a scipy.sparse matrix holding token occurrence counts (or binary occurrence information), possibly normalized as token frequencies if norm=’l1’ or projected on the euclidean unit sphere if norm=’l2’.
This text vectorizer implementation uses the hashing trick to find the token string name to feature integer index mapping.
This strategy has several advantages:
it is very low memory scalable to large datasets as there is no need to store a vocabulary dictionary in memory.
it is fast to pickle and un-pickle as it holds no state besides the constructor parameters.
it can be used in a streaming (partial fit) or parallel pipeline as there is no state computed during fit.
There are also a couple of cons (vs using a CountVectorizer with an in-memory vocabulary):
there is no way to compute the inverse transform (from feature indices to string feature names) which can be a problem when trying to introspect which features are most important to a model.
there can be collisions: distinct tokens can be mapped to the same feature index. However in practice this is rarely an issue if n_features is large enough (e.g. 2 ** 18 for text classification problems).
no IDF weighting as this would render the transformer stateful.
The hash function employed is the signed 32-bit version of Murmurhash3.
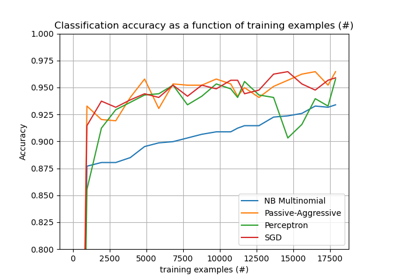
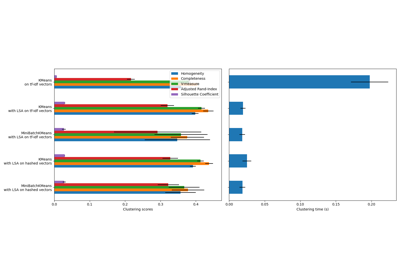
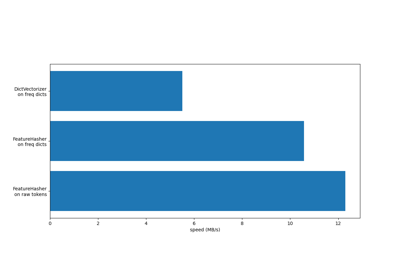
For an efficiency comparision of the different feature extractors, see FeatureHasher and DictVectorizer Comparison.
Read more in the User Guide.
- Parameters:
- input{‘filename’, ‘file’, ‘content’}, default=’content’
If
'filename', the sequence passed as an argument to fit is expected to be a list of filenames that need reading to fetch the raw content to analyze.If
'file', the sequence items must have a ‘read’ method (file-like object) that is called to fetch the bytes in memory.If
'content', the input is expected to be a sequence of items that can be of type string or byte.
- encodingstr, default=’utf-8’
If bytes or files are given to analyze, this encoding is used to decode.
- decode_error{‘strict’, ‘ignore’, ‘replace’}, default=’strict’
Instruction on what to do if a byte sequence is given to analyze that contains characters not of the given
encoding. By default, it is ‘strict’, meaning that a UnicodeDecodeError will be raised. Other values are ‘ignore’ and ‘replace’.- strip_accents{‘ascii’, ‘unicode’} or callable, default=None
Remove accents and perform other character normalization during the preprocessing step. ‘ascii’ is a fast method that only works on characters that have a direct ASCII mapping. ‘unicode’ is a slightly slower method that works on any character. None (default) means no character normalization is performed.
Both ‘ascii’ and ‘unicode’ use NFKD normalization from
unicodedata.normalize.- lowercasebool, default=True
Convert all characters to lowercase before tokenizing.
- preprocessorcallable, default=None
Override the preprocessing (string transformation) stage while preserving the tokenizing and n-grams generation steps. Only applies if
analyzeris not callable.- tokenizercallable, default=None
Override the string tokenization step while preserving the preprocessing and n-grams generation steps. Only applies if
analyzer == 'word'.- stop_words{‘english’}, list, default=None
If ‘english’, a built-in stop word list for English is used. There are several known issues with ‘english’ and you should consider an alternative (see Using stop words).
If a list, that list is assumed to contain stop words, all of which will be removed from the resulting tokens. Only applies if
analyzer == 'word'.- token_patternstr or None, default=r”(?u)\b\w\w+\b”
Regular expression denoting what constitutes a “token”, only used if
analyzer == 'word'. The default regexp selects tokens of 2 or more alphanumeric characters (punctuation is completely ignored and always treated as a token separator).If there is a capturing group in token_pattern then the captured group content, not the entire match, becomes the token. At most one capturing group is permitted.
- ngram_rangetuple (min_n, max_n), default=(1, 1)
The lower and upper boundary of the range of n-values for different n-grams to be extracted. All values of n such that min_n <= n <= max_n will be used. For example an
ngram_rangeof(1, 1)means only unigrams,(1, 2)means unigrams and bigrams, and(2, 2)means only bigrams. Only applies ifanalyzeris not callable.- analyzer{‘word’, ‘char’, ‘char_wb’} or callable, default=’word’
Whether the feature should be made of word or character n-grams. Option ‘char_wb’ creates character n-grams only from text inside word boundaries; n-grams at the edges of words are padded with space.
If a callable is passed it is used to extract the sequence of features out of the raw, unprocessed input.
Changed in version 0.21: Since v0.21, if
inputis'filename'or'file', the data is first read from the file and then passed to the given callable analyzer.- n_featuresint, default=(2 ** 20)
The number of features (columns) in the output matrices. Small numbers of features are likely to cause hash collisions, but large numbers will cause larger coefficient dimensions in linear learners.
- binarybool, default=False
If True, all non zero counts are set to 1. This is useful for discrete probabilistic models that model binary events rather than integer counts.
- norm{‘l1’, ‘l2’}, default=’l2’
Norm used to normalize term vectors. None for no normalization.
- alternate_signbool, default=True
When True, an alternating sign is added to the features as to approximately conserve the inner product in the hashed space even for small n_features. This approach is similar to sparse random projection.
New in version 0.19.
- dtypetype, default=np.float64
Type of the matrix returned by fit_transform() or transform().
See also
CountVectorizerConvert a collection of text documents to a matrix of token counts.
TfidfVectorizerConvert a collection of raw documents to a matrix of TF-IDF features.
Notes
This estimator is stateless and does not need to be fitted. However, we recommend to call
fit_transforminstead oftransform, as parameter validation is only performed infit.Examples
>>> from sklearn.feature_extraction.text import HashingVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = HashingVectorizer(n_features=2**4) >>> X = vectorizer.fit_transform(corpus) >>> print(X.shape) (4, 16)
Methods
Return a callable to process input data.
Return a function to preprocess the text before tokenization.
Return a function that splits a string into a sequence of tokens.
decode(doc)Decode the input into a string of unicode symbols.
fit(X[, y])Only validates estimator's parameters.
fit_transform(X[, y])Transform a sequence of documents to a document-term matrix.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
Build or fetch the effective stop words list.
partial_fit(X[, y])Only validates estimator's parameters.
set_output(*[, transform])Set output container.
set_params(**params)Set the parameters of this estimator.
transform(X)Transform a sequence of documents to a document-term matrix.
- build_analyzer()[source]¶
Return a callable to process input data.
The callable handles preprocessing, tokenization, and n-grams generation.
- Returns:
- analyzer: callable
A function to handle preprocessing, tokenization and n-grams generation.
- build_preprocessor()[source]¶
Return a function to preprocess the text before tokenization.
- Returns:
- preprocessor: callable
A function to preprocess the text before tokenization.
- build_tokenizer()[source]¶
Return a function that splits a string into a sequence of tokens.
- Returns:
- tokenizer: callable
A function to split a string into a sequence of tokens.
- decode(doc)[source]¶
Decode the input into a string of unicode symbols.
The decoding strategy depends on the vectorizer parameters.
- Parameters:
- docbytes or str
The string to decode.
- Returns:
- doc: str
A string of unicode symbols.
- fit(X, y=None)[source]¶
Only validates estimator’s parameters.
This method allows to: (i) validate the estimator’s parameters and (ii) be consistent with the scikit-learn transformer API.
- Parameters:
- Xndarray of shape [n_samples, n_features]
Training data.
- yIgnored
Not used, present for API consistency by convention.
- Returns:
- selfobject
HashingVectorizer instance.
- fit_transform(X, y=None)[source]¶
Transform a sequence of documents to a document-term matrix.
- Parameters:
- Xiterable over raw text documents, length = n_samples
Samples. Each sample must be a text document (either bytes or unicode strings, file name or file object depending on the constructor argument) which will be tokenized and hashed.
- yany
Ignored. This parameter exists only for compatibility with sklearn.pipeline.Pipeline.
- Returns:
- Xsparse matrix of shape (n_samples, n_features)
Document-term matrix.
- get_metadata_routing()[source]¶
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]¶
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- get_stop_words()[source]¶
Build or fetch the effective stop words list.
- Returns:
- stop_words: list or None
A list of stop words.
- partial_fit(X, y=None)[source]¶
Only validates estimator’s parameters.
This method allows to: (i) validate the estimator’s parameters and (ii) be consistent with the scikit-learn transformer API.
- Parameters:
- Xndarray of shape [n_samples, n_features]
Training data.
- yIgnored
Not used, present for API consistency by convention.
- Returns:
- selfobject
HashingVectorizer instance.
- set_output(*, transform=None)[source]¶
Set output container.
See Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame outputNone: Transform configuration is unchanged
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- transform(X)[source]¶
Transform a sequence of documents to a document-term matrix.
- Parameters:
- Xiterable over raw text documents, length = n_samples
Samples. Each sample must be a text document (either bytes or unicode strings, file name or file object depending on the constructor argument) which will be tokenized and hashed.
- Returns:
- Xsparse matrix of shape (n_samples, n_features)
Document-term matrix.