sklearn.dummy.DummyClassifier¶
- class sklearn.dummy.DummyClassifier(*, strategy='prior', random_state=None, constant=None)[source]¶
DummyClassifier makes predictions that ignore the input features.
This classifier serves as a simple baseline to compare against other more complex classifiers.
The specific behavior of the baseline is selected with the
strategyparameter.All strategies make predictions that ignore the input feature values passed as the
Xargument tofitandpredict. The predictions, however, typically depend on values observed in theyparameter passed tofit.Note that the “stratified” and “uniform” strategies lead to non-deterministic predictions that can be rendered deterministic by setting the
random_stateparameter if needed. The other strategies are naturally deterministic and, once fit, always return the same constant prediction for any value ofX.Read more in the User Guide.
New in version 0.13.
- Parameters:
- strategy{“most_frequent”, “prior”, “stratified”, “uniform”, “constant”}, default=”prior”
Strategy to use to generate predictions.
“most_frequent”: the
predictmethod always returns the most frequent class label in the observedyargument passed tofit. Thepredict_probamethod returns the matching one-hot encoded vector.“prior”: the
predictmethod always returns the most frequent class label in the observedyargument passed tofit(like “most_frequent”).predict_probaalways returns the empirical class distribution ofyalso known as the empirical class prior distribution.“stratified”: the
predict_probamethod randomly samples one-hot vectors from a multinomial distribution parametrized by the empirical class prior probabilities. Thepredictmethod returns the class label which got probability one in the one-hot vector ofpredict_proba. Each sampled row of both methods is therefore independent and identically distributed.“uniform”: generates predictions uniformly at random from the list of unique classes observed in
y, i.e. each class has equal probability.“constant”: always predicts a constant label that is provided by the user. This is useful for metrics that evaluate a non-majority class.
Changed in version 0.24: The default value of
strategyhas changed to “prior” in version 0.24.
- random_stateint, RandomState instance or None, default=None
Controls the randomness to generate the predictions when
strategy='stratified'orstrategy='uniform'. Pass an int for reproducible output across multiple function calls. See Glossary.- constantint or str or array-like of shape (n_outputs,), default=None
The explicit constant as predicted by the “constant” strategy. This parameter is useful only for the “constant” strategy.
- Attributes:
- classes_ndarray of shape (n_classes,) or list of such arrays
Unique class labels observed in
y. For multi-output classification problems, this attribute is a list of arrays as each output has an independent set of possible classes.- n_classes_int or list of int
Number of label for each output.
- class_prior_ndarray of shape (n_classes,) or list of such arrays
Frequency of each class observed in
y. For multioutput classification problems, this is computed independently for each output.- n_outputs_int
Number of outputs.
- sparse_output_bool
True if the array returned from predict is to be in sparse CSC format. Is automatically set to True if the input
yis passed in sparse format.
See also
DummyRegressorRegressor that makes predictions using simple rules.
Examples
>>> import numpy as np >>> from sklearn.dummy import DummyClassifier >>> X = np.array([-1, 1, 1, 1]) >>> y = np.array([0, 1, 1, 1]) >>> dummy_clf = DummyClassifier(strategy="most_frequent") >>> dummy_clf.fit(X, y) DummyClassifier(strategy='most_frequent') >>> dummy_clf.predict(X) array([1, 1, 1, 1]) >>> dummy_clf.score(X, y) 0.75
Methods
fit(X, y[, sample_weight])Fit the baseline classifier.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
predict(X)Perform classification on test vectors X.
Return log probability estimates for the test vectors X.
Return probability estimates for the test vectors X.
score(X, y[, sample_weight])Return the mean accuracy on the given test data and labels.
set_fit_request(*[, sample_weight])Request metadata passed to the
fitmethod.set_params(**params)Set the parameters of this estimator.
set_score_request(*[, sample_weight])Request metadata passed to the
scoremethod.- fit(X, y, sample_weight=None)[source]¶
Fit the baseline classifier.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Training data.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
Target values.
- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- selfobject
Returns the instance itself.
- get_metadata_routing()[source]¶
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]¶
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- predict(X)[source]¶
Perform classification on test vectors X.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test data.
- Returns:
- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
Predicted target values for X.
- predict_log_proba(X)[source]¶
Return log probability estimates for the test vectors X.
- Parameters:
- X{array-like, object with finite length or shape}
Training data.
- Returns:
- Pndarray of shape (n_samples, n_classes) or list of such arrays
Returns the log probability of the sample for each class in the model, where classes are ordered arithmetically for each output.
- predict_proba(X)[source]¶
Return probability estimates for the test vectors X.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test data.
- Returns:
- Pndarray of shape (n_samples, n_classes) or list of such arrays
Returns the probability of the sample for each class in the model, where classes are ordered arithmetically, for each output.
- score(X, y, sample_weight=None)[source]¶
Return the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
- Parameters:
- XNone or array-like of shape (n_samples, n_features)
Test samples. Passing None as test samples gives the same result as passing real test samples, since DummyClassifier operates independently of the sampled observations.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True labels for X.
- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
Mean accuracy of self.predict(X) w.r.t. y.
- set_fit_request(*, sample_weight: Union[bool, None, str] = '$UNCHANGED$') DummyClassifier[source]¶
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
- Returns:
- selfobject
The updated object.
- set_params(**params)[source]¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_score_request(*, sample_weight: Union[bool, None, str] = '$UNCHANGED$') DummyClassifier[source]¶
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.New in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
Examples using sklearn.dummy.DummyClassifier¶
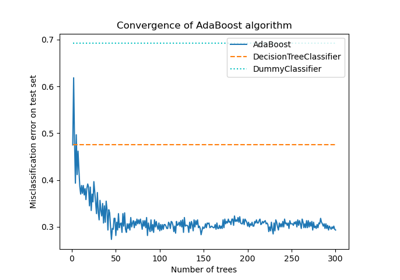
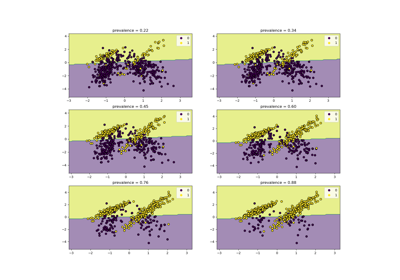
Class Likelihood Ratios to measure classification performance