sklearn.datasets.fetch_species_distributions¶
-
sklearn.datasets.fetch_species_distributions(data_home=None, download_if_missing=True)[source]¶ Loader for species distribution dataset from Phillips et. al. (2006)
Read more in the User Guide.
- Parameters
- data_homeoptional, default: None
Specify another download and cache folder for the datasets. By default all scikit-learn data is stored in ‘~/scikit_learn_data’ subfolders.
- download_if_missingoptional, True by default
If False, raise a IOError if the data is not locally available instead of trying to download the data from the source site.
- Returns
- The data is returned as a Bunch object with the following attributes:
- coveragesarray, shape = [14, 1592, 1212]
These represent the 14 features measured at each point of the map grid. The latitude/longitude values for the grid are discussed below. Missing data is represented by the value -9999.
- trainrecord array, shape = (1624,)
The training points for the data. Each point has three fields:
train[‘species’] is the species name
train[‘dd long’] is the longitude, in degrees
train[‘dd lat’] is the latitude, in degrees
- testrecord array, shape = (620,)
The test points for the data. Same format as the training data.
- Nx, Nyintegers
The number of longitudes (x) and latitudes (y) in the grid
- x_left_lower_corner, y_left_lower_cornerfloats
The (x,y) position of the lower-left corner, in degrees
- grid_sizefloat
The spacing between points of the grid, in degrees
Notes
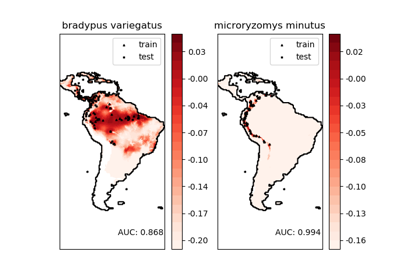
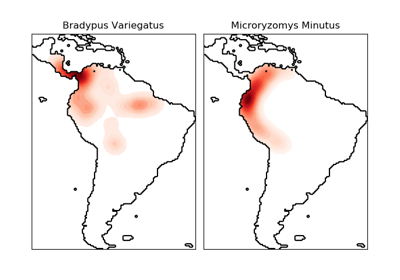
This dataset represents the geographic distribution of species. The dataset is provided by Phillips et. al. (2006).
The two species are:
“Bradypus variegatus” , the Brown-throated Sloth.
“Microryzomys minutus” , also known as the Forest Small Rice Rat, a rodent that lives in Peru, Colombia, Ecuador, Peru, and Venezuela.
For an example of using this dataset with scikit-learn, see examples/applications/plot_species_distribution_modeling.py.
References
“Maximum entropy modeling of species geographic distributions” S. J. Phillips, R. P. Anderson, R. E. Schapire - Ecological Modelling, 190:231-259, 2006.