Note
Click here to download the full example code or to run this example in your browser via Binder
Cross-validation on Digits Dataset Exercise¶
A tutorial exercise using Cross-validation with an SVM on the Digits dataset.
This exercise is used in the Cross-validation generators part of the Model selection: choosing estimators and their parameters section of the A tutorial on statistical-learning for scientific data processing.
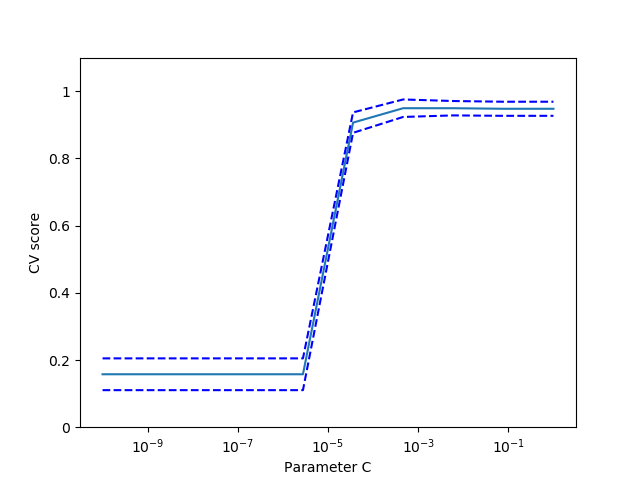
print(__doc__)
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn import datasets, svm
X, y = datasets.load_digits(return_X_y=True)
svc = svm.SVC(kernel='linear')
C_s = np.logspace(-10, 0, 10)
scores = list()
scores_std = list()
for C in C_s:
svc.C = C
this_scores = cross_val_score(svc, X, y, n_jobs=1)
scores.append(np.mean(this_scores))
scores_std.append(np.std(this_scores))
# Do the plotting
import matplotlib.pyplot as plt
plt.figure()
plt.semilogx(C_s, scores)
plt.semilogx(C_s, np.array(scores) + np.array(scores_std), 'b--')
plt.semilogx(C_s, np.array(scores) - np.array(scores_std), 'b--')
locs, labels = plt.yticks()
plt.yticks(locs, list(map(lambda x: "%g" % x, locs)))
plt.ylabel('CV score')
plt.xlabel('Parameter C')
plt.ylim(0, 1.1)
plt.show()
Total running time of the script: ( 0 minutes 8.988 seconds)
Estimated memory usage: 8 MB