
Contributing¶
This project is a community effort, and everyone is welcome to contribute.
The project is hosted on https://github.com/scikit-learn/scikit-learn
Scikit-learn is somewhat selective when it comes to adding new algorithms, and the best way to contribute and to help the project is to start working on known issues. See Issues for New Contributors to get started.
Our community, our values
We are a community based on openness and friendly, didactic, discussions.
We aspire to treat everybody equally, and value their contributions.
Decisions are made based on technical merit and consensus.
Code is not the only way to help the project. Reviewing pull requests, answering questions to help others on mailing lists or issues, organizing and teaching tutorials, working on the website, improving the documentation, are all priceless contributions.
We abide by the principles of openness, respect, and consideration of others of the Python Software Foundation: https://www.python.org/psf/codeofconduct/
Submitting a bug report¶
In case you experience issues using this package, do not hesitate to submit a ticket to the Bug Tracker. You are also welcome to post feature requests or pull requests.
Ways to contribute¶
There are many ways to contribute to scikit-learn, with the most common ones being contribution of code or documentation to the project. Improving the documentation is no less important than improving the library itself. If you find a typo in the documentation, or have made improvements, do not hesitate to send an email to the mailing list or preferably submit a GitHub pull request. Full documentation can be found under the doc/ directory.
But there are many other ways to help. In particular answering queries on the issue tracker, investigating bugs, and reviewing other developers’ pull requests are very valuable contributions that decrease the burden on the project maintainers.
Another way to contribute is to report issues you’re facing, and give a “thumbs up” on issues that others reported and that are relevant to you. It also helps us if you spread the word: reference the project from your blog and articles, link to it from your website, or simply say “I use it”:
Retrieving the latest code¶
We use Git for version control and GitHub for hosting our main repository.
You can check out the latest sources with the command:
git clone git://github.com/scikit-learn/scikit-learn.git
or if you have write privileges:
git clone git@github.com:scikit-learn/scikit-learn.git
If you run the development version, it is cumbersome to reinstall the
package each time you update the sources. It is thus preferred that
you add the scikit-learn directory to your PYTHONPATH and build the
extension in place:
python setup.py build_ext --inplace
Another option is to install the package in editable mode if you change your code a lot and do not want to have to reinstall every time. This basically builds the extension in place and creates a link to the development directory (see the pip docs):
pip install --editable .
Note
This is fundamentally similar to using the command python setup.py develop (see the setuptool docs). It is however preferred to use pip.
Note
If you decide to do an editable install you have to rerun:
python setup.py build_ext --inplace
every time the source code of a compiled extension is changed (for instance when switching branches or pulling changes from upstream).
On Unix-like systems, you can simply type make in the top-level folder to
build in-place and launch all the tests. Have a look at the Makefile for
additional utilities.
Contributing code¶
Note
To avoid duplicating work, it is highly advised that you contact the developers on the mailing list before starting work on a non-trivial feature.
How to contribute¶
The preferred way to contribute to scikit-learn is to fork the main repository on GitHub, then submit a “pull request” (PR):
Create an account on GitHub if you do not already have one.
Fork the project repository: click on the ‘Fork’ button near the top of the page. This creates a copy of the code under your account on the GitHub server. For more details on how to fork a repository see this guide.
Clone this copy to your local disk:
$ git clone git@github.com:YourLogin/scikit-learn.gitCreate a branch to hold your changes:
$ git checkout -b my-featureand start making changes. Never work in the
masterbranch!Work on this copy, on your computer, using Git to do the version control. When you’re done editing, do:
$ git add modified_files $ git committo record your changes in Git, then push them to GitHub with:
$ git push -u origin my-feature
Finally, follow these instructions to create a pull request from your fork. This will send an email to the committers. You may want to consider sending an email to the mailing list for more visibility.
Note
In the above setup, your origin remote repository points to
YourLogin/scikit-learn.git. If you wish to fetch/merge from the main
repository instead of your forked one, you will need to add another remote
to use instead of origin. If we choose the name upstream for it, the
command will be:
$ git remote add upstream https://github.com/scikit-learn/scikit-learn.git
If any of the above seems like magic to you, then look up the Git documentation and the Git development workflow on the web.
If some conflicts arise between your branch and the master branch, you need
to merge master. The command will be:
$ git merge master
with master being synchronized with the upstream.
Subsequently, you need to solve the conflicts. You can refer to the Git documentation related to resolving merge conflict using the command line.
Note
In the past, the policy to resolve conflicts was to rebase your branch on
master. GitHub interface deals with merging master better than in
the past.
Contributing pull requests¶
It is recommended to check that your contribution complies with the following rules before submitting a pull request:
Follow the coding-guidelines (see below). To make sure that your PR does not add PEP8 violations you can run ./build_tools/travis/flake8_diff.sh or make flake8-diff on a Unix-like system.
When applicable, use the validation tools and other code in the
sklearn.utilssubmodule. A list of utility routines available for developers can be found in the Utilities for Developers page.Give your pull request a helpful title that summarises what your contribution does. In some cases “Fix <ISSUE TITLE>” is enough. “Fix #<ISSUE NUMBER>” is not enough.
Often pull requests resolve one or more other issues (or pull requests). If merging your pull request means that some other issues/PRs should be closed, you should use keywords to create link to them (e.g.,
Fixes #1234; multiple issues/PRs are allowed as long as each one is preceded by a keyword). Upon merging, those issues/PRs will automatically be closed by GitHub. If your pull request is simply related to some other issues/PRs, create a link to them without using the keywords (e.g.,See also #1234).All public methods should have informative docstrings with sample usage presented as doctests when appropriate.
Please prefix the title of your pull request with
[MRG]if the contribution is complete and should be subjected to a detailed review. Two core developers will review your code and change the prefix of the pull request to[MRG + 1]and[MRG + 2]on approval, making it eligible for merging. An incomplete contribution – where you expect to do more work before receiving a full review – should be prefixed[WIP](to indicate a work in progress) and changed to[MRG]when it matures. WIPs may be useful to: indicate you are working on something to avoid duplicated work, request broad review of functionality or API, or seek collaborators. WIPs often benefit from the inclusion of a task list in the PR description.All other tests pass when everything is rebuilt from scratch. On Unix-like systems, check with (from the toplevel source folder):
$ makeWhen adding additional functionality, provide at least one example script in the
examples/folder. Have a look at other examples for reference. Examples should demonstrate why the new functionality is useful in practice and, if possible, compare it to other methods available in scikit-learn.Documentation and high-coverage tests are necessary for enhancements to be accepted. Bug-fixes or new features should be provided with non-regression tests. These tests verify the correct behavior of the fix or feature. In this manner, further modifications on the code base are granted to be consistent with the desired behavior. For the case of bug fixes, at the time of the PR, the non-regression tests should fail for the code base in the master branch and pass for the PR code.
At least one paragraph of narrative documentation with links to references in the literature (with PDF links when possible) and the example. For more details on writing and building the documentation, see the Documentation section.
You can also check for common programming errors with the following tools:
Code with a good unittest coverage (at least 90%, better 100%), check with:
$ pip install nose coverage $ nosetests --with-coverage path/to/tests_for_packagesee also Testing and improving test coverage
No pyflakes warnings, check with:
$ pip install pyflakes $ pyflakes path/to/module.pyNo PEP8 warnings, check with:
$ pip install pep8 $ pep8 path/to/module.pyAutoPEP8 can help you fix some of the easy redundant errors:
$ pip install autopep8 $ autopep8 path/to/pep8.py
Bonus points for contributions that include a performance analysis with a benchmark script and profiling output (please report on the mailing list or on the GitHub wiki).
Also check out the How to optimize for speed guide for more details on profiling and Cython optimizations.
Note
The current state of the scikit-learn code base is not compliant with all of those guidelines, but we expect that enforcing those constraints on all new contributions will get the overall code base quality in the right direction.
Note
For two very well documented and more detailed guides on development workflow, please pay a visit to the Scipy Development Workflow - and the Astropy Workflow for Developers sections.
Continuous Integration (CI)
- Travis is used for testing on Linux platforms
- Appveyor is used for testing on Windows platforms
- CircleCI is used to build the docs for viewing
Please note that if one of the following markers appear in the latest commit message, the following actions are taken.
Commit Message Marker Action Taken by CI [ci skip] CI is skipped completely [doc skip] Docs are not built [doc quick] Docs built, but excludes example gallery plots [doc build] Docs built including example gallery plots
Filing Bugs¶
We use Github issues to track all bugs and feature requests; feel free to open an issue if you have found a bug or wish to see a feature implemented.
It is recommended to check that your issue complies with the following rules before submitting:
Verify that your issue is not being currently addressed by other issues or pull requests.
If you are submitting an algorithm or feature request, please verify that the algorithm fulfills our new algorithm requirements.
Please ensure all code snippets and error messages are formatted in appropriate code blocks. See Creating and highlighting code blocks.
Please include your operating system type and version number, as well as your Python, scikit-learn, numpy, and scipy versions. This information can be found by running the following code snippet:
import platform; print(platform.platform()) import sys; print("Python", sys.version) import numpy; print("NumPy", numpy.__version__) import scipy; print("SciPy", scipy.__version__) import sklearn; print("Scikit-Learn", sklearn.__version__)
Please be specific about what estimators and/or functions are involved and the shape of the data, as appropriate; please include a reproducible code snippet or link to a gist. If an exception is raised, please provide the traceback.
Issues for New Contributors¶
New contributors should look for the following tags when looking for issues. We strongly recommend that new contributors tackle “easy” issues first: this helps the contributor become familiar with the contribution workflow, and for the core devs to become acquainted with the contributor; besides which, we frequently underestimate how easy an issue is to solve!
good first issue tag
A great way to start contributing to scikit-learn is to pick an item from the list of good first issues in the issue tracker. Resolving these issues allow you to start contributing to the project without much prior knowledge. If you have already contributed to scikit-learn, you should look at Easy issues instead.
Easy tag
Another great way to contribute to scikit-learn is to pick an item from the list of Easy issues in the issue tracker. Your assistance in this area will be greatly appreciated by the more experienced developers as it helps free up their time to concentrate on other issues.
help wanted tag
We often use the help wanted tag to mark issues regardless of difficulty. Additionally, we use the help wanted tag to mark Pull Requests which have been abandoned by their original contributor and are available for someone to pick up where the original contributor left off. The list of issues with the help wanted tag can be found here .
Note that not all issues which need contributors will have this tag.
Documentation¶
We are glad to accept any sort of documentation: function docstrings, reStructuredText documents (like this one), tutorials, etc. reStructuredText documents live in the source code repository under the doc/ directory.
You can edit the documentation using any text editor, and then generate the
HTML output by typing make html from the doc/ directory. Alternatively,
make html-noplot can be used to quickly generate the documentation without
the example gallery. The resulting HTML files will be placed in _build/html/
and are viewable in a web browser. See the README file in the doc/ directory
for more information.
For building the documentation, you will need sphinx, matplotlib and pillow.
When you are writing documentation, it is important to keep a good compromise between mathematical and algorithmic details, and give intuition to the reader on what the algorithm does.
Basically, to elaborate on the above, it is best to always
start with a small paragraph with a hand-waving explanation of what the
method does to the data. Then, it is very helpful
to point out why the feature is useful and when it should be used -
the latter also including “big O”
(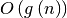 )
complexities of the algorithm, as opposed to just rules of thumb,
as the latter can be very machine-dependent.
If those complexities are not available, then rules of thumb
may be provided instead.
)
complexities of the algorithm, as opposed to just rules of thumb,
as the latter can be very machine-dependent.
If those complexities are not available, then rules of thumb
may be provided instead.
Secondly, a generated figure from an example (as mentioned in the previous paragraph) should then be included to further provide some intuition.
Next, one or two small code examples to show its use can be added.
Next, any math and equations, followed by references, can be added to further the documentation. Not starting the documentation with the maths makes it more friendly towards users that are just interested in what the feature will do, as opposed to how it works “under the hood”.
You may also be asked to show your changes when it’s built. When you create a pull request or make changes in an existing one modifying the docs, CircleCI automatically builds them. Thus, you can easily view your changes in the built artifacts using the following URL:
http://scikit-learn.org/circle?{BUILD_NUMBER}
We attempt to assemble a more precise set of changed files in the documentation at:
http://scikit-learn.org/circle?{BUILD_NUMBER}/_changed.html
Note: When you visit the details page of the CircleCI tests, you can find your BUILD_NUMBER mentioned as ‘build #’ which is different from your pull request number, which is presented as ‘pull/#’.
Finally, follow the formatting rules below to make it consistently good:
Add “See also” in docstrings for related classes/functions.
“See also” in docstrings should be one line per reference, with a colon and an explanation, for example:
See also -------- SelectKBest : Select features based on the k highest scores. SelectFpr : Select features based on a false positive rate test.For unwritten formatting rules, try to follow existing good works:
- For “References” in docstrings, see the Silhouette Coefficient (
sklearn.metrics.silhouette_score).
Warning
Sphinx version
While we do our best to have the documentation build under as many version of Sphinx as possible, the different versions tend to behave slightly differently. To get the best results, you should use version 1.0.
Testing and improving test coverage¶
High-quality unit testing is a corner-stone of the scikit-learn development process. For this purpose, we use the nose package. The tests are functions appropriately named, located in tests subdirectories, that check the validity of the algorithms and the different options of the code.
The full scikit-learn tests can be run using ‘make’ in the root folder. Alternatively, running ‘nosetests’ in a folder will run all the tests of the corresponding subpackages.
We expect code coverage of new features to be at least around 90%.
Note
Workflow to improve test coverage
To test code coverage, you need to install the coverage package in addition to nose.
- Run ‘make test-coverage’. The output lists for each file the line numbers that are not tested.
- Find a low hanging fruit, looking at which lines are not tested, write or adapt a test specifically for these lines.
- Loop.
Developers web site¶
More information can be found on the developer’s wiki.
Issue Tracker Tags¶
All issues and pull requests on the Github issue tracker should have (at least) one of the following tags:
| Bug / Crash: | Something is happening that clearly shouldn’t happen. Wrong results as well as unexpected errors from estimators go here. |
|---|---|
| Cleanup / Enhancement: | |
| Improving performance, usability, consistency. | |
| Documentation: | Missing, incorrect or sub-standard documentations and examples. |
| New Feature: | Feature requests and pull requests implementing a new feature. |
There are four other tags to help new contributors:
| good first issue: | |
|---|---|
| This issue is ideal for a first contribution to scikit-learn. Ask for help if the formulation is unclear. If you have already contributed to scikit-learn, look at Easy issues instead. | |
| Easy: | This issue can be tackled without much prior experience. |
| Moderate: | Might need some knowledge of machine learning or the package, but is still approachable for someone new to the project. |
| help wanted: | This tag marks an issue which currently lacks a contributor or a PR that needs another contributor to take over the work. These issues can range in difficulty, and may not be approachable for new contributors. Note that not all issues which need contributors will have this tag. |
Coding guidelines¶
The following are some guidelines on how new code should be written. Of course, there are special cases and there will be exceptions to these rules. However, following these rules when submitting new code makes the review easier so new code can be integrated in less time.
Uniformly formatted code makes it easier to share code ownership. The scikit-learn project tries to closely follow the official Python guidelines detailed in PEP8 that detail how code should be formatted and indented. Please read it and follow it.
In addition, we add the following guidelines:
- Use underscores to separate words in non class names:
n_samplesrather thannsamples.- Avoid multiple statements on one line. Prefer a line return after a control flow statement (
if/for).- Use relative imports for references inside scikit-learn.
- Unit tests are an exception to the previous rule; they should use absolute imports, exactly as client code would. A corollary is that, if
sklearn.fooexports a class or function that is implemented insklearn.foo.bar.baz, the test should import it fromsklearn.foo.- Please don’t use
import *in any case. It is considered harmful by the official Python recommendations. It makes the code harder to read as the origin of symbols is no longer explicitly referenced, but most important, it prevents using a static analysis tool like pyflakes to automatically find bugs in scikit-learn.- Use the numpy docstring standard in all your docstrings.
A good example of code that we like can be found here.
Input validation¶
The module sklearn.utils contains various functions for doing input
validation and conversion. Sometimes, np.asarray suffices for validation;
do not use np.asanyarray or np.atleast_2d, since those let NumPy’s
np.matrix through, which has a different API
(e.g., * means dot product on np.matrix,
but Hadamard product on np.ndarray).
In other cases, be sure to call check_array on any array-like argument
passed to a scikit-learn API function. The exact parameters to use depends
mainly on whether and which scipy.sparse matrices must be accepted.
For more information, refer to the Utilities for Developers page.
Random Numbers¶
If your code depends on a random number generator, do not use
numpy.random.random() or similar routines. To ensure
repeatability in error checking, the routine should accept a keyword
random_state and use this to construct a
numpy.random.RandomState object.
See sklearn.utils.check_random_state in Utilities for Developers.
Here’s a simple example of code using some of the above guidelines:
from sklearn.utils import check_array, check_random_state
def choose_random_sample(X, random_state=0):
"""
Choose a random point from X
Parameters
----------
X : array-like, shape = (n_samples, n_features)
array representing the data
random_state : RandomState or an int seed (0 by default)
A random number generator instance to define the state of the
random permutations generator.
Returns
-------
x : numpy array, shape = (n_features,)
A random point selected from X
"""
X = check_array(X)
random_state = check_random_state(random_state)
i = random_state.randint(X.shape[0])
return X[i]
If you use randomness in an estimator instead of a freestanding function, some additional guidelines apply.
First off, the estimator should take a random_state argument to its
__init__ with a default value of None.
It should store that argument’s value, unmodified,
in an attribute random_state.
fit can call check_random_state on that attribute
to get an actual random number generator.
If, for some reason, randomness is needed after fit,
the RNG should be stored in an attribute random_state_.
The following example should make this clear:
class GaussianNoise(BaseEstimator, TransformerMixin):
"""This estimator ignores its input and returns random Gaussian noise.
It also does not adhere to all scikit-learn conventions,
but showcases how to handle randomness.
"""
def __init__(self, n_components=100, random_state=None):
self.random_state = random_state
# the arguments are ignored anyway, so we make them optional
def fit(self, X=None, y=None):
self.random_state_ = check_random_state(self.random_state)
def transform(self, X):
n_samples = X.shape[0]
return self.random_state_.randn(n_samples, n_components)
The reason for this setup is reproducibility:
when an estimator is fit twice to the same data,
it should produce an identical model both times,
hence the validation in fit, not __init__.
Deprecation¶
If any publicly accessible method, function, attribute or parameter
is renamed, we still support the old one for two releases and issue
a deprecation warning when it is called/passed/accessed.
E.g., if the function zero_one is renamed to zero_one_loss,
we add the decorator deprecated (from sklearn.utils)
to zero_one and call zero_one_loss from that function:
from ..utils import deprecated
def zero_one_loss(y_true, y_pred, normalize=True):
# actual implementation
pass
@deprecated("Function 'zero_one' was renamed to 'zero_one_loss' "
"in version 0.13 and will be removed in release 0.15. "
"Default behavior is changed from 'normalize=False' to "
"'normalize=True'")
def zero_one(y_true, y_pred, normalize=False):
return zero_one_loss(y_true, y_pred, normalize)
If an attribute is to be deprecated,
use the decorator deprecated on a property.
E.g., renaming an attribute labels_ to classes_ can be done as:
@property
@deprecated("Attribute labels_ was deprecated in version 0.13 and "
"will be removed in 0.15. Use 'classes_' instead")
def labels_(self):
return self.classes_
If a parameter has to be deprecated, use DeprecationWarning appropriately.
In the following example, k is deprecated and renamed to n_clusters:
import warnings
def example_function(n_clusters=8, k=None):
if k is not None:
warnings.warn("'k' was renamed to n_clusters in version 0.13 and "
"will be removed in 0.15.", DeprecationWarning)
n_clusters = k
As in these examples, the warning message should always give both the version in which the deprecation happened and the version in which the old behavior will be removed. If the deprecation happened in version 0.x-dev, the message should say deprecation occurred in version 0.x and the removal will be in 0.(x+2). For example, if the deprecation happened in version 0.18-dev, the message should say it happened in version 0.18 and the old behavior will be removed in version 0.20.
In addition, a deprecation note should be added in the docstring, recalling the
same information as the deprecation warning as explained above. Use the
.. deprecated:: directive:
.. deprecated:: 0.13
``k`` was renamed to ``n_clusters`` in version 0.13 and will be removed
in 0.15.
Python versions supported¶
All scikit-learn code should work unchanged in both Python 2.7 and 3.4 or newer. Since Python 3.x is not backwards compatible, that may require changes to code and it certainly requires testing on both 2.7 and 3.4 or newer.
For most numerical algorithms, Python 3.x support is easy:
just remember that print is a function and
integer division is written //.
String handling has been overhauled, though, as have parts of
the Python standard library.
The six package helps with
cross-compatibility and is included in scikit-learn as
sklearn.externals.six.
Code Review Guidelines¶
Reviewing code contributed to the project as PRs is a crucial component of scikit-learn development. We encourage anyone to start reviewing code of other developers. The code review process is often highly educational for everybody involved. This is particularly appropriate if it is a feature you would like to use, and so can respond critically about whether the PR meets your needs. While each pull request needs to be signed off by two core developers, you can speed up this process by providing your feedback.
Here are a few important aspects that need to be covered in any code review, from high-level questions to a more detailed check-list.
- Do we want this in the library? Is it likely to be used? Do you, as a scikit-learn user, like the change and intend to use it? Is it in the scope of scikit-learn? Will the cost of maintaining a new feature be worth its benefits?
- Is the code consistent with the API of scikit-learn? Are public functions/classes/parameters well named and intuitively designed?
- Are all public functions/classes and their parameters, return types, and stored attributes named according to scikit-learn conventions and documented clearly?
- Is any new functionality described in the user-guide and illustrated with examples?
- Is every public function/class tested? Are a reasonable set of parameters, their values, value types, and combinations tested? Do the tests validate that the code is correct, i.e. doing what the documentation says it does? If the change is a bug-fix, is a non-regression test included? Look at this to get started with testing in Python.
- Do the tests pass in the continuous integration build? If appropriate, help the contributor understand why tests failed.
- Do the tests cover every line of code (see the coverage report in the build log)? If not, are the lines missing coverage good exceptions?
- Is the code easy to read and low on redundancy? Should variable names be improved for clarity or consistency? Should comments be added? Should comments be removed as unhelpful or extraneous?
- Could the code easily be rewritten to run much more efficiently for relevant settings?
- Is the code backwards compatible with previous versions? (or is a deprecation cycle necessary?)
- Will the new code add any dependencies on other libraries? (this is unlikely to be accepted)
- Does the documentation render properly (see the Documentation section for more details), and are the plots instructive?
APIs of scikit-learn objects¶
To have a uniform API, we try to have a common basic API for all the objects. In addition, to avoid the proliferation of framework code, we try to adopt simple conventions and limit to a minimum the number of methods an object must implement.
Different objects¶
The main objects in scikit-learn are (one class can implement multiple interfaces):
| Estimator: | The base object, implements a estimator = obj.fit(data, targets)
or: estimator = obj.fit(data)
|
|---|---|
| Predictor: | For supervised learning, or some unsupervised problems, implements: prediction = obj.predict(data)
Classification algorithms usually also offer a way to quantify certainty
of a prediction, either using probability = obj.predict_proba(data)
|
| Transformer: | For filtering or modifying the data, in a supervised or unsupervised way, implements: new_data = obj.transform(data)
When fitting and transforming can be performed much more efficiently together than separately, implements: new_data = obj.fit_transform(data)
|
| Model: | A model that can give a goodness of fit measure or a likelihood of unseen data, implements (higher is better): score = obj.score(data)
|
Estimators¶
The API has one predominant object: the estimator. A estimator is an object that fits a model based on some training data and is capable of inferring some properties on new data. It can be, for instance, a classifier or a regressor. All estimators implement the fit method:
estimator.fit(X, y)
All built-in estimators also have a set_params method, which sets
data-independent parameters (overriding previous parameter values passed
to __init__).
All estimators in the main scikit-learn codebase should inherit from
sklearn.base.BaseEstimator.
Instantiation¶
This concerns the creation of an object. The object’s __init__ method
might accept constants as arguments that determine the estimator’s behavior
(like the C constant in SVMs). It should not, however, take the actual training
data as an argument, as this is left to the fit() method:
clf2 = SVC(C=2.3)
clf3 = SVC([[1, 2], [2, 3]], [-1, 1]) # WRONG!
The arguments accepted by __init__ should all be keyword arguments
with a default value. In other words, a user should be able to instantiate
an estimator without passing any arguments to it. The arguments should all
correspond to hyperparameters describing the model or the optimisation
problem the estimator tries to solve. These initial arguments (or parameters)
are always remembered by the estimator.
Also note that they should not be documented under the “Attributes” section,
but rather under the “Parameters” section for that estimator.
In addition, every keyword argument accepted by __init__ should
correspond to an attribute on the instance. Scikit-learn relies on this to
find the relevant attributes to set on an estimator when doing model selection.
To summarize, an __init__ should look like:
def __init__(self, param1=1, param2=2):
self.param1 = param1
self.param2 = param2
There should be no logic, not even input validation,
and the parameters should not be changed.
The corresponding logic should be put where the parameters are used,
typically in fit.
The following is wrong:
def __init__(self, param1=1, param2=2, param3=3):
# WRONG: parameters should not be modified
if param1 > 1:
param2 += 1
self.param1 = param1
# WRONG: the object's attributes should have exactly the name of
# the argument in the constructor
self.param3 = param2
The reason for postponing the validation is that the same validation
would have to be performed in set_params,
which is used in algorithms like GridSearchCV.
Fitting¶
The next thing you will probably want to do is to estimate some
parameters in the model. This is implemented in the fit() method.
The fit() method takes the training data as arguments, which can be one
array in the case of unsupervised learning, or two arrays in the case
of supervised learning.
Note that the model is fitted using X and y, but the object holds no reference to X and y. There are, however, some exceptions to this, as in the case of precomputed kernels where this data must be stored for use by the predict method.
| Parameters | |
|---|---|
| X | array-like, with shape = [N, D], where N is the number of samples and D is the number of features. |
| y | array, with shape = [N], where N is the number of samples. |
| kwargs | optional data-dependent parameters. |
X.shape[0] should be the same as y.shape[0]. If this requisite
is not met, an exception of type ValueError should be raised.
y might be ignored in the case of unsupervised learning. However, to
make it possible to use the estimator as part of a pipeline that can
mix both supervised and unsupervised transformers, even unsupervised
estimators need to accept a y=None keyword argument in
the second position that is just ignored by the estimator.
For the same reason, fit_predict, fit_transform, score
and partial_fit methods need to accept a y argument in
the second place if they are implemented.
The method should return the object (self). This pattern is useful
to be able to implement quick one liners in an IPython session such as:
y_predicted = SVC(C=100).fit(X_train, y_train).predict(X_test)
Depending on the nature of the algorithm, fit can sometimes also
accept additional keywords arguments. However, any parameter that can
have a value assigned prior to having access to the data should be an
__init__ keyword argument. fit parameters should be restricted
to directly data dependent variables. For instance a Gram matrix or
an affinity matrix which are precomputed from the data matrix X are
data dependent. A tolerance stopping criterion tol is not directly
data dependent (although the optimal value according to some scoring
function probably is).
Estimated Attributes¶
Attributes that have been estimated from the data must always have a name
ending with trailing underscore, for example the coefficients of
some regression estimator would be stored in a coef_ attribute after
fit has been called.
The last-mentioned attributes are expected to be overridden when
you call fit a second time without taking any previous value into
account: fit should be idempotent.
Optional Arguments¶
In iterative algorithms, the number of iterations should be specified by
an integer called n_iter.
Rolling your own estimator¶
If you want to implement a new estimator that is scikit-learn-compatible,
whether it is just for you or for contributing it to scikit-learn, there are
several internals of scikit-learn that you should be aware of in addition to
the scikit-learn API outlined above. You can check whether your estimator
adheres to the scikit-learn interface and standards by running
utils.estimator_checks.check_estimator on the class:
>>> from sklearn.utils.estimator_checks import check_estimator
>>> from sklearn.svm import LinearSVC
>>> check_estimator(LinearSVC) # passes
The main motivation to make a class compatible to the scikit-learn estimator
interface might be that you want to use it together with model evaluation and
selection tools such as model_selection.GridSearchCV and
pipeline.Pipeline.
Before detailing the required interface below, we describe two ways to achieve the correct interface more easily.
Project template:
We provide a project template which helps in the creation of Python packages containing scikit-learn compatible estimators. It provides:
- an initial git repository with Python package directory structure
- a template of a scikit-learn estimator
- an initial test suite including use of
check_estimator - directory structures and scripts to compile documentation and example galleries
- scripts to manage continuous integration (testing on Linux and Windows)
- instructions from getting started to publishing on PyPi
BaseEstimator and mixins:
We tend to use use “duck typing”, so building an estimator which follows the API suffices for compatibility, without needing to inherit from or even import any scikit-learn classes.
However, if a dependency on scikit-learn is acceptable in your code,
you can prevent a lot of boilerplate code
by deriving a class from BaseEstimator
and optionally the mixin classes in sklearn.base.
For example, below is a custom classifier, with more examples included
in the scikit-learn-contrib
project template.
>>> import numpy as np
>>> from sklearn.base import BaseEstimator, ClassifierMixin
>>> from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
>>> from sklearn.utils.multiclass import unique_labels
>>> from sklearn.metrics import euclidean_distances
>>> class TemplateClassifier(BaseEstimator, ClassifierMixin):
...
... def __init__(self, demo_param='demo'):
... self.demo_param = demo_param
...
... def fit(self, X, y):
...
... # Check that X and y have correct shape
... X, y = check_X_y(X, y)
... # Store the classes seen during fit
... self.classes_ = unique_labels(y)
...
... self.X_ = X
... self.y_ = y
... # Return the classifier
... return self
...
... def predict(self, X):
...
... # Check is fit had been called
... check_is_fitted(self, ['X_', 'y_'])
...
... # Input validation
... X = check_array(X)
...
... closest = np.argmin(euclidean_distances(X, self.X_), axis=1)
... return self.y_[closest]
get_params and set_params¶
All scikit-learn estimators have get_params and set_params functions.
The get_params function takes no arguments and returns a dict of the
__init__ parameters of the estimator, together with their values.
It must take one keyword argument, deep,
which receives a boolean value that determines
whether the method should return the parameters of sub-estimators
(for most estimators, this can be ignored).
The default value for deep should be true.
The set_params on the other hand takes as input a dict of the form
'parameter': value and sets the parameter of the estimator using this dict.
Return value must be estimator itself.
While the get_params mechanism is not essential (see Cloning below),
the set_params function is necessary as it is used to set parameters during
grid searches.
The easiest way to implement these functions, and to get a sensible
__repr__ method, is to inherit from sklearn.base.BaseEstimator. If you
do not want to make your code dependent on scikit-learn, the easiest way to
implement the interface is:
def get_params(self, deep=True):
# suppose this estimator has parameters "alpha" and "recursive"
return {"alpha": self.alpha, "recursive": self.recursive}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
Parameters and init¶
As model_selection.GridSearchCV uses set_params
to apply parameter setting to estimators,
it is essential that calling set_params has the same effect
as setting parameters using the __init__ method.
The easiest and recommended way to accomplish this is to
not do any parameter validation in __init__.
All logic behind estimator parameters,
like translating string arguments into functions, should be done in fit.
Also it is expected that parameters with trailing _ are not to be set
inside the __init__ method. All and only the public attributes set by
fit have a trailing _. As a result the existence of parameters with
trailing _ is used to check if the estimator has been fitted.
Cloning¶
For use with the model_selection module,
an estimator must support the base.clone function to replicate an estimator.
This can be done by providing a get_params method.
If get_params is present, then clone(estimator) will be an instance of
type(estimator) on which set_params has been called with clones of
the result of estimator.get_params().
Objects that do not provide this method will be deep-copied
(using the Python standard function copy.deepcopy)
if safe=False is passed to clone.
Pipeline compatibility¶
For an estimator to be usable together with pipeline.Pipeline in any but the
last step, it needs to provide a fit or fit_transform function.
To be able to evaluate the pipeline on any data but the training set,
it also needs to provide a transform function.
There are no special requirements for the last step in a pipeline, except that
it has a fit function. All fit and fit_transform functions must
take arguments X, y, even if y is not used. Similarly, for score to be
usable, the last step of the pipeline needs to have a score function that
accepts an optional y.
Estimator types¶
Some common functionality depends on the kind of estimator passed.
For example, cross-validation in model_selection.GridSearchCV and
model_selection.cross_val_score defaults to being stratified when used
on a classifier, but not otherwise. Similarly, scorers for average precision
that take a continuous prediction need to call decision_function for classifiers,
but predict for regressors. This distinction between classifiers and regressors
is implemented using the _estimator_type attribute, which takes a string value.
It should be "classifier" for classifiers and "regressor" for
regressors and "clusterer" for clustering methods, to work as expected.
Inheriting from ClassifierMixin, RegressorMixin or ClusterMixin
will set the attribute automatically.
Working notes¶
For unresolved issues, TODOs, and remarks on ongoing work, developers are advised to maintain notes on the GitHub wiki.
Specific models¶
Classifiers should accept y (target) arguments to fit
that are sequences (lists, arrays) of either strings or integers.
They should not assume that the class labels
are a contiguous range of integers;
instead, they should store a list of classes
in a classes_ attribute or property.
The order of class labels in this attribute
should match the order in which predict_proba, predict_log_proba
and decision_function return their values.
The easiest way to achieve this is to put:
self.classes_, y = np.unique(y, return_inverse=True)
in fit.
This returns a new y that contains class indexes, rather than labels,
in the range [0, n_classes).
A classifier’s predict method should return
arrays containing class labels from classes_.
In a classifier that implements decision_function,
this can be achieved with:
def predict(self, X):
D = self.decision_function(X)
return self.classes_[np.argmax(D, axis=1)]
In linear models, coefficients are stored in an array called coef_,
and the independent term is stored in intercept_.
sklearn.linear_model.base contains a few base classes and mixins
that implement common linear model patterns.
The sklearn.utils.multiclass module contains useful functions
for working with multiclass and multilabel problems.