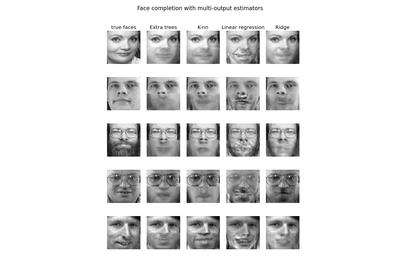
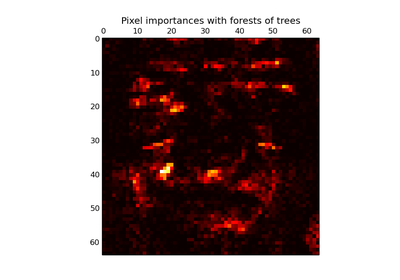
sklearn.datasets.fetch_olivetti_faces¶
- sklearn.datasets.fetch_olivetti_faces(data_home=None, shuffle=False, random_state=0, download_if_missing=True)[source]¶
Loader for the Olivetti faces data-set from AT&T.
Parameters: data_home : optional, default: None
Specify another download and cache folder for the datasets. By default all scikit learn data is stored in ‘~/scikit_learn_data’ subfolders.
shuffle : boolean, optional
If True the order of the dataset is shuffled to avoid having images of the same person grouped.
download_if_missing: optional, True by default :
If False, raise a IOError if the data is not locally available instead of trying to download the data from the source site.
random_state : optional, integer or RandomState object
The seed or the random number generator used to shuffle the data.
Returns: An object with the following attributes: :
data : numpy array of shape (400, 4096)
Each row corresponds to a ravelled face image of original size 64 x 64 pixels.
images : numpy array of shape (400, 64, 64)
Each row is a face image corresponding to one of the 40 subjects of the dataset.
target : numpy array of shape (400, )
Labels associated to each face image. Those labels are ranging from 0-39 and correspond to the Subject IDs.
DESCR : string
Description of the modified Olivetti Faces Dataset.
Notes
This dataset consists of 10 pictures each of 40 individuals. The original database was available from (now defunct)
The version retrieved here comes in MATLAB format from the personal web page of Sam Roweis: