Note
Go to the end to download the full example code or to run this example in your browser via JupyterLite or Binder
Pixel importances with a parallel forest of trees¶
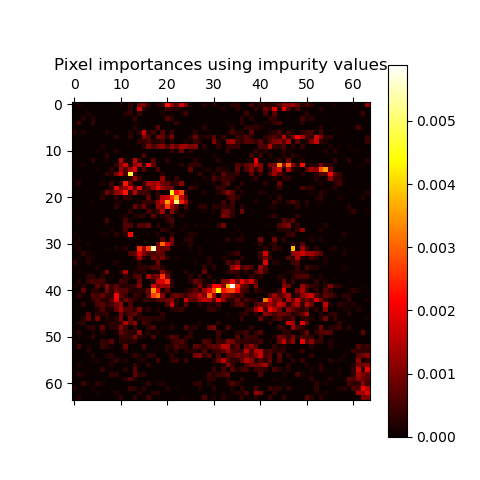
This example shows the use of a forest of trees to evaluate the impurity based importance of the pixels in an image classification task on the faces dataset. The hotter the pixel, the more important it is.
The code below also illustrates how the construction and the computation of the predictions can be parallelized within multiple jobs.
Loading the data and model fitting¶
First, we load the olivetti faces dataset and limit the dataset to contain only the first five classes. Then we train a random forest on the dataset and evaluate the impurity-based feature importance. One drawback of this method is that it cannot be evaluated on a separate test set. For this example, we are interested in representing the information learned from the full dataset. Also, we’ll set the number of cores to use for the tasks.
from sklearn.datasets import fetch_olivetti_faces
We select the number of cores to use to perform parallel fitting of
the forest model. -1 means use all available cores.
n_jobs = -1
Load the faces dataset
data = fetch_olivetti_faces()
X, y = data.data, data.target
Limit the dataset to 5 classes.
mask = y < 5
X = X[mask]
y = y[mask]
A random forest classifier will be fitted to compute the feature importances.
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=750, n_jobs=n_jobs, random_state=42)
forest.fit(X, y)
Feature importance based on mean decrease in impurity (MDI)¶
Feature importances are provided by the fitted attribute
feature_importances_ and they are computed as the mean and standard
deviation of accumulation of the impurity decrease within each tree.
Warning
Impurity-based feature importances can be misleading for high cardinality features (many unique values). See Permutation feature importance as an alternative.
import time
import matplotlib.pyplot as plt
start_time = time.time()
img_shape = data.images[0].shape
importances = forest.feature_importances_
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
imp_reshaped = importances.reshape(img_shape)
plt.matshow(imp_reshaped, cmap=plt.cm.hot)
plt.title("Pixel importances using impurity values")
plt.colorbar()
plt.show()
Elapsed time to compute the importances: 0.104 seconds
Can you still recognize a face?
The limitations of MDI is not a problem for this dataset because:
All features are (ordered) numeric and will thus not suffer the cardinality bias
We are only interested to represent knowledge of the forest acquired on the training set.
If these two conditions are not met, it is recommended to instead use
the permutation_importance.
Total running time of the script: (0 minutes 1.195 seconds)