
A demo of the Spectral Biclustering algorithm¶
This example demonstrates how to generate a checkerboard dataset and bicluster it using the Spectral Biclustering algorithm.
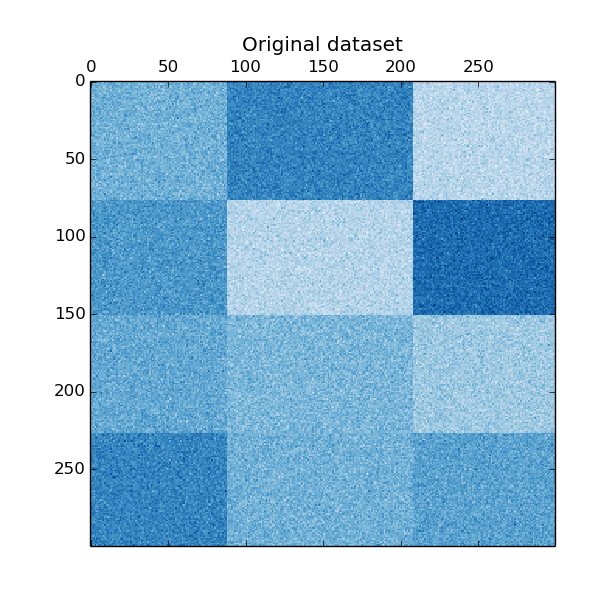
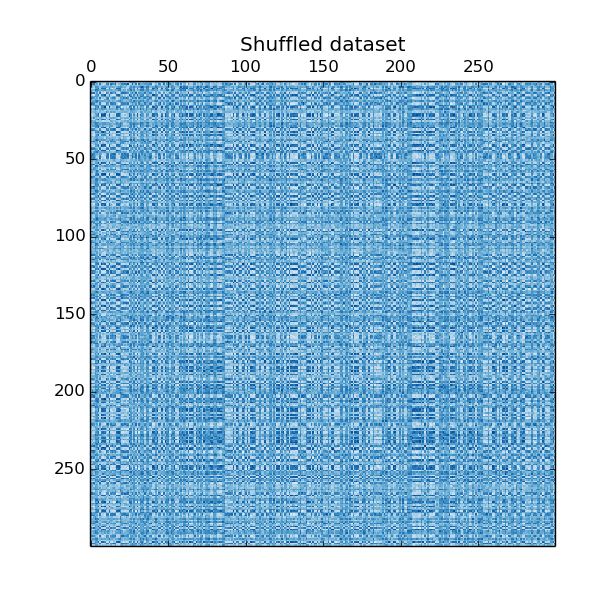
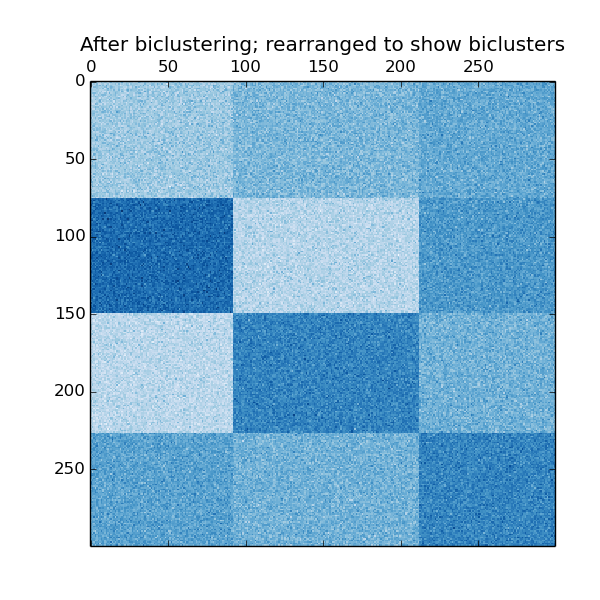
The data is generated with the make_checkerboard function, then shuffled and passed to the Spectral Biclustering algorithm. The rows and columns of the shuffled matrix are rearranged to show the biclusters found by the algorithm.
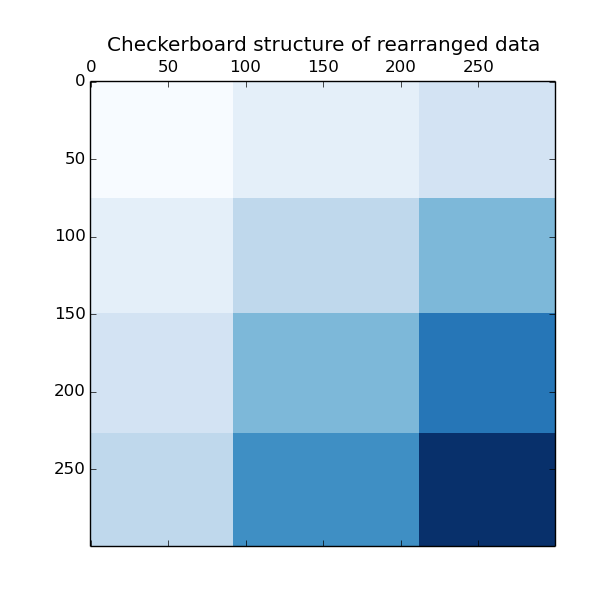
The outer product of the row and column label vectors shows a representation of the checkerboard structure.
Script output:
consensus score: 1.0
Python source code: plot_spectral_biclustering.py
print(__doc__)
# Author: Kemal Eren <kemal@kemaleren.com>
# License: BSD 3 clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_checkerboard
from sklearn.datasets import samples_generator as sg
from sklearn.cluster.bicluster import SpectralBiclustering
from sklearn.metrics import consensus_score
n_clusters = (4, 3)
data, rows, columns = make_checkerboard(
shape=(300, 300), n_clusters=n_clusters, noise=10,
shuffle=False, random_state=0)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
data, row_idx, col_idx = sg._shuffle(data, random_state=0)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
model = SpectralBiclustering(n_clusters=n_clusters, method='log',
random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_,
(rows[:, row_idx], columns[:, col_idx]))
print("consensus score: {:.1f}".format(score))
fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.matshow(np.outer(np.sort(model.row_labels_) + 1,
np.sort(model.column_labels_) + 1),
cmap=plt.cm.Blues)
plt.title("Checkerboard structure of rearranged data")
plt.show()
Total running time of the example: 0.54 seconds ( 0 minutes 0.54 seconds)