
2.1.3.2.1. Variational Gaussian Mixture Models¶
The API is identical to that of the GMM class, the main
difference being that it offers access to precision matrices as well
as covariance matrices.
The inference algorithm is the one from the following paper:
- Variational Inference for Dirichlet Process Mixtures David Blei, Michael Jordan. Bayesian Analysis, 2006
While this paper presents the parts of the inference algorithm that are concerned with the structure of the dirichlet process, it does not go into detail in the mixture modeling part, which can be just as complex, or even more. For this reason we present here a full derivation of the inference algorithm and all the update and lower-bound equations. If you’re not interested in learning how to derive similar algorithms yourself and you’re not interested in changing/debugging the implementation in the scikit this document is not for you.
The complexity of this implementation is linear in the number of
mixture components and data points. With regards to the
dimensionality, it is linear when using spherical or diag and
quadratic/cubic when using tied or full. For spherical or diag
it is O(n_states * n_points * dimension) and for tied or full it
is O(n_states * n_points * dimension^2 + n_states * dimension^3) (it
is necessary to invert the covariance/precision matrices and compute
its determinant, hence the cubic term).
This implementation is expected to scale at least as well as EM for the mixture of Gaussians.
2.1.3.2.2. Update rules for VB inference¶
Here the full mathematical derivation of the Variational Bayes update
rules for Gaussian Mixture Models is given. The main parameters of the
model, defined for any class ![k \in [1..K]](../_images/math/5d90819185ae56b9e0d1c08df4bd719b6aa06b03.png) are the class
proportion
are the class
proportion  , the mean parameters
, the mean parameters 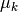 , the
covariance parameters
, the
covariance parameters 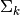 , which is characterized by
variational Wishart density,
, which is characterized by
variational Wishart density,  , where
, where
 is the degrees of freedom, and
is the degrees of freedom, and 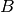 is the
scale matrix. Depending on the covariance parametrization,
is the
scale matrix. Depending on the covariance parametrization,
 can be a positive scalar, a positive vector or a Symmetric
Positive Definite matrix.
can be a positive scalar, a positive vector or a Symmetric
Positive Definite matrix.
2.1.3.2.2.1. The spherical model¶
The model then is

The variational distribution we’ll use is

2.1.3.2.2.1.1. The bound¶
The variational bound is
![\begin{array}{rcl}
\log P(X) &\ge&
\sum_k (E_q[\log P(\phi_k)] - E_q[\log Q(\phi_k)]) \\
&&
+\sum_k \left( E_q[\log P(\mu_k)] - E_q[\log Q(\mu_k)] \right) \\
&&
+\sum_k \left( E_q[\log P(\sigma_k)] - E_q[\log Q(\sigma_k)] \right) \\
&&
+\sum_i \left( E_q[\log P(z_i)] - E_q[\log Q(z_i)] \right) \\
&&
+\sum_i E_q[\log P(X_t)]
\end{array}](../_images/math/b654eee1dcbceb1e8500e575796fbfea6f5518bb.png)
The bound for
![\begin{array}{rcl}
E_q[\log Beta(1,\alpha)] - E[\log Beta(\gamma_{k,1},\gamma_{k,2})]
&=&
\log \Gamma(1+\alpha) - \log \Gamma(\alpha) \\ &&
+(\alpha-1)(\Psi(\gamma_{k,2})-\Psi(\gamma_{k,1}+\gamma_{k,2})) \\ &&
- \log \Gamma(\gamma_{k,1}+\gamma_{k,2}) + \log \Gamma(\gamma_{k,1}) +
\log \Gamma(\gamma_{k,2}) \\ &&
-
(\gamma_{k,1}-1)(\Psi(\gamma_{k,1})-\Psi(\gamma_{k,1}+\gamma_{k,2}))
\\ &&
-
(\gamma_{k,2}-1)(\Psi(\gamma_{k,2})-\Psi(\gamma_{k,1}+\gamma_{k,2}))
\end{array}](../_images/math/8a794bac91917159e451b8cfc65d3014cffcf45a.png)
The bound for
![\begin{array}{rcl}
&& E_q[\log P(\mu_k)] - E_q[\log Q(\mu_k)] \\
&=&
\int\!d\mu_f q(\mu_f) \log P(\mu_f)
- \int\!d\mu_f q(\mu_f) \log Q(\mu_f) \\
&=&
- \frac{D}{2}\log 2\pi - \frac{1}{2} ||\nu_{\mu_k}||^2 - \frac{D}{2}
+ \frac{D}{2} \log 2\pi e
\end{array}](../_images/math/6249d7686a865f94d4173d4351dc919df639f900.png)
The bound for 
Here I’ll use the inverse scale parametrization of the gamma distribution.
![\begin{array}{rcl}
&& E_q[\log P(\sigma_k)] - E_q [\log Q(\sigma_k)] \\ &=&
\log \Gamma (a_k) - (a_k-1)\Psi(a_k) -\log b_k + a_k - \frac{a_k}{b_k}
\end{array}](../_images/math/82c2a519749bba8b5cdf13fac6f28b6645b044ab.png)
The bound for z
![\begin{array}{rcl}
&& E_q[\log P(z)] - E_q[\log Q(z)] \\
&=&
\sum_{k} \left(
\left(\sum_{j=k+1}^K \nu_{z_{i,j}}\right)(\Psi(\gamma_{k,2})-\Psi(\gamma_{k,1}+\gamma_{k,2}))
+ \nu_{z_{i,k}}(\Psi(\gamma_{k,1})-\Psi(\gamma_{k,1}+\gamma_{k,2}))
- \log \nu_{z_{i,k}} \right)
\end{array}](../_images/math/ea7883239d280b3403de364242bc5eaa7c043fa3.png)
The bound for 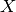
Recall that there is no need for a  so this bound is just
so this bound is just
![\begin{array}{rcl}
E_q[\log P(X_i)] &=& \sum_k \nu_{z_k} \left( - \frac{D}{2}\log 2\pi
+\frac{D}{2} (\Psi(a_k) - \log(b_k))
-\frac{a_k}{2b_k} (||X_i - \nu_{\mu_k}||^2+D) - \log 2 \pi e \right)
\end{array}](../_images/math/5ec40441786a0fb92ebe6de43edbc7d6f5b6bab2.png)
For simplicity I’ll later call the term inside the parenthesis ![E_q[\log P(X_i|z_i=k)]](../_images/math/e43d9cd0fe15ae82f739a60dd2cd5be2c65c1d99.png)
2.1.3.2.2.1.2. The updates¶
Updating 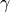

Updating 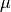
The updates for mu essentially are just weighted expectations of
regularized by the prior. We can see this by taking the
gradient of the bound with regards to  and setting it to zero.
The gradient is
and setting it to zero.
The gradient is

so the update is

Updating and 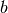
For some odd reason it doesn’t really work when you derive the updates
for a and b using the gradients of the lower bound (terms involving the
 function show up and is hard to isolate).
However, we can use the other formula,
function show up and is hard to isolate).
However, we can use the other formula,
![\log Q(\sigma_k) = E_{v \ne \sigma_k}[\log P] + const](../_images/math/5e0afb293a769e69c218750f2c321c3f81e12fba.png)
All the terms not involving get folded over into the
constant and we get two terms: the prior and the probability of
. This gives us

This is the log of a gamma distribution, with  and
and

You can verify this by normalizing the previous term.
Updating 
![\log \nu_{z_{i,k}} \propto \Psi(\gamma_{k,1}) -
\Psi(\gamma_{k,1} + \gamma_{k,2}) + E_q[\log P(X_i|z_i=k)] +
\sum_{j < k} \left (\Psi(\gamma_{j,2}) -
\Psi(\gamma_{j,1}+\gamma_{j,2})\right).](../_images/math/fd50a0c15b891077a575799eeb6d2dbcb4ed3cf2.png)
2.1.3.2.2.2. The diagonal model¶
The model then is

Tha variational distribution we’ll use is

2.1.3.2.2.2.1. The lower bound¶
The changes in this lower bound from the previous model are in the
distributions of 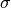 (as there are a lot more s
now) and .
(as there are a lot more s
now) and .
The bound for  is the same bound for and can
be safely omitted.
is the same bound for and can
be safely omitted.
The bound for :
The main difference here is that the precision matrix  scales the norm, so we have an extra term after computing the
expectation of
scales the norm, so we have an extra term after computing the
expectation of  , which is
, which is
 . We then
have
. We then
have
![\begin{array}{rcl}
E_q[\log P(X_i)] &=& \sum_k \nu_{z_k} \Big( - \frac{D}{2}\log 2\pi
+\frac{1}{2}\sum_d (\Psi(a_{k,d}) - \log(b_{k,d})) \\
&&
-\frac{1}{2}((X_i - \nu_{\mu_k})^T\bm{\frac{a_k}{b_k}}(X_i - \nu_{\mu_k})+ \sum_d \sigma_{k,d})- \log 2 \pi e \Big)
\end{array}](../_images/math/27fb9b03759b81490d29723a983e444e58902355.png)
2.1.3.2.2.2.2. The updates¶
The updates only chance for (to weight them with the new
), (but the change is all folded into the
![E_q[P(X_i|z_i=k)]](../_images/math/8c59c344ff9ba0a15e07b4bf3158a3b9d8123072.png) term), and the and variables themselves.
term), and the and variables themselves.
The update for

The updates for a and b
Here we’ll do something very similar to the spheric model. The main
difference is that now each controls only one dimension
of the bound:

Hence


2.1.3.2.2.3. The tied model¶
The model then is

Tha variational distribution we’ll use is

2.1.3.2.2.3.1. The lower bound¶
There are two changes in the lower-bound: for 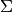 and for .
and for .
The bound for
![\begin{array}{rcl}
\frac{D^2}{2}\log 2 + \sum_d \log \Gamma(\frac{D+1-d}{2}) \\
- \frac{aD}{2}\log 2 + \frac{a}{2} \log |\mathbf{B}| + \sum_d \log \Gamma(\frac{a+1-d}{2}) \\
+ \frac{a-D}{2}\left(\sum_d \Psi\left(\frac{a+1-d}{2}\right)
+ D \log 2 + \log |\mathbf{B}|\right) \\
+ \frac{1}{2} a \mathbf{tr}[\mathbf{B}-\mathbf{I}]
\end{array}](../_images/math/1df05e599583852d227514ff84ea614fc5159fba.png)
The bound for X
![\begin{array}{rcl}
E_q[\log P(X_i)] &=& \sum_k \nu_{z_k} \Big( - \frac{D}{2}\log 2\pi
+\frac{1}{2}\left(\sum_d \Psi\left(\frac{a+1-d}{2}\right)
+ D \log 2 + \log |\mathbf{B}|\right) \\
&&
-\frac{1}{2}((X_i - \nu_{\mu_k})a\mathbf{B}(X_i - \nu_{\mu_k})+ a\mathbf{tr}(\mathbf{B}))- \log 2 \pi e \Big)
\end{array}](../_images/math/a1658cc847336e3efa70e0601d507a3f78cbefe8.png)
2.1.3.2.2.3.2. The updates¶
As in the last setting, what changes are the trivial update for ,
the update for and the update for and  .
.
The update for

The update for and
As this distribution is far too complicated I’m not even going to try going at it the gradient way.
![\log Q(\Sigma) = +\frac{1}{2}\log |\Sigma| - \frac{1}{2} \mathbf{tr}[\Sigma]
+ \sum_i \sum_k \nu_{z_{i,k}} \left( +\frac{1}{2}\log |\Sigma| - \frac{1}{2}((X_i-\nu_{\mu_k})^T\Sigma(X_i-\nu_{\mu_k})+\mathbf{tr}[\Sigma]) \right)](../_images/math/6cfe4cdaf5ef73a55c04bb0fcb95103837383bc8.png)
which non-trivially (seeing that the quadratic form with in
the middle can be expressed as the trace of something) reduces to
![\log Q(\Sigma) = +\frac{1}{2}\log |\Sigma| - \frac{1}{2} \mathbf{tr}[\Sigma]
+ \sum_i \sum_k \nu_{z_{i,k}} \left( +\frac{1}{2}\log |\Sigma| - \frac{1}{2}(\mathbf{tr}[(X_i-\nu_{\mu_k})(X_i-\nu_{\mu_k})^T\Sigma]+\mathbf{tr}[I \Sigma]) \right)](../_images/math/15c553f2cfb7fa130f468d1a1bf31553d617f0fc.png)
hence this (with a bit of squinting) looks like a wishart with parameters

and

2.1.3.2.2.4. The full model¶
The model then is

The variational distribution we’ll use is

2.1.3.2.2.4.1. The lower bound¶
All that changes in this lower bound in comparison to the previous one
is that there are K priors on different precision matrices
and there are the correct indices on the bound for X.
2.1.3.2.2.4.2. The updates¶
All that changes in the updates is that the update for mu uses only the proper sigma and the updates for a and B don’t have a sum over K, so


and
